Chi pensa che il cloud sia infinito non ha mai provato a far girare un Hugging Face Large Language Model su un cluster k3s dentro l’infrastruttura Seeweb. È il classico scenario da “o sei preparato o ti fai male”. Eppure la promessa è irresistibile: prendersi un colosso come Qwen2.5-7B-Instruct e addomesticarlo in una macchina Ubuntu con una GPU NVIDIA che suda come un motore di Formula 1. Il deploy LLMs con KubeAI su k3s non è una passeggiata, è più simile a una scalata, con la differenza che invece della corda hai Helm e invece dei chiodi da roccia usi docker e driver grafici. La ricompensa però è grande, perché se lo fai bene ti ritrovi con un modello conversazionale di livello enterprise, senza chiedere il permesso a OpenAI o Google.
Il mito che basti cliccare su “install” e il gioco è fatto crolla già ai prerequisiti. Devi avere Ubuntu aggiornato, accesso SSH, privilegi sudo e soprattutto una GPU seria, altrimenti il tuo amico Qwen2.5-7B-Instruct non si muove di un millimetro. Parliamo di un modello che, in precisione FP16, può richiedere 16GB o più di VRAM, quindi scordati di farlo girare su una vecchia GTX polverosa. Senza driver NVIDIA funzionanti, nvidia-smi che ti sorride e almeno 32GB di RAM, il tuo cluster morirà ancora prima di nascere. La verità è che la differenza tra un proof of concept e un ambiente produttivo sta tutta nella noiosa fase preparatoria che molti saltano e che invece è il vero campo di battaglia.
La sequenza è chirurgica. Prima aggiorni pacchetti, poi ti assicuri che la GPU venga vista. Se nvidia-smi non mostra nulla, sei fuori gioco. Poi arriva Docker, il motore di tutto, che va installato e verificato con log e status come se fosse un paziente in sala operatoria. Non è raro che si inceppi per conflitti di porte o limiti di risorse, e qui scatta la prima ironia: quanti CTO pensano ancora che Docker sia “banale”, salvo scoprire che al primo deploy un banalissimo container non parte e si ritrovano a imprecare contro systemd.
Il passo successivo è la magia dell’NVIDIA Container Toolkit, quello che permette ai container di vedere la GPU. Senza di lui sei condannato a un Kubernetes che ignora la parte più costosa del tuo hardware. Solo dopo aver visto nvidia-smi girare dentro un container CUDA puoi iniziare a respirare. Poi arriva Helm, il package manager di Kubernetes. Tutti lo considerano noioso e burocratico, ma senza Helm sei praticamente cieco, perché KubeAI senza i suoi chart non parte. E qui arriva la parte interessante, perché k3s entra in scena.
Chi non conosce k3s lo considera il “Kubernetes giocattolo”, mentre in realtà è la versione snella e geniale, ideale per ambienti edge o per chi vuole evitare di montare un cluster mostruoso solo per testare un modello. Lo installi in due righe di shell e ti trovi con un cluster funzionante. Ovviamente, funziona solo se sai dove mettere le mani: la disabilitazione di Traefik, la configurazione del kubeconfig, la verifica con kubectl get nodes che deve mostrare lo stato Ready. Se vedi Connection Refused, benvenuto nel club: controlla i log, riavvia servizi e preparati a quella che i manuali chiamano troubleshooting e che io chiamo “pazienza zen per CTO”.
Ora che il cluster respira, la vera sfida è far capire a Kubernetes come parlare con la GPU. Qui entra in scena il GPU Operator di NVIDIA. Con un paio di comandi Helm ti ritrovi un namespace pieno di pod che sembrano mostri alieni. Devi aspettare che tutti entrino nello stato Running o Completed, e solo allora puoi guardare il nodo e vedere quella scritta che ti fa sorridere: nvidia.com/gpu sotto Allocatable e Capacity. In quel momento capisci che il tuo cluster non è più un giocattolo, ma una piattaforma di calcolo seria.
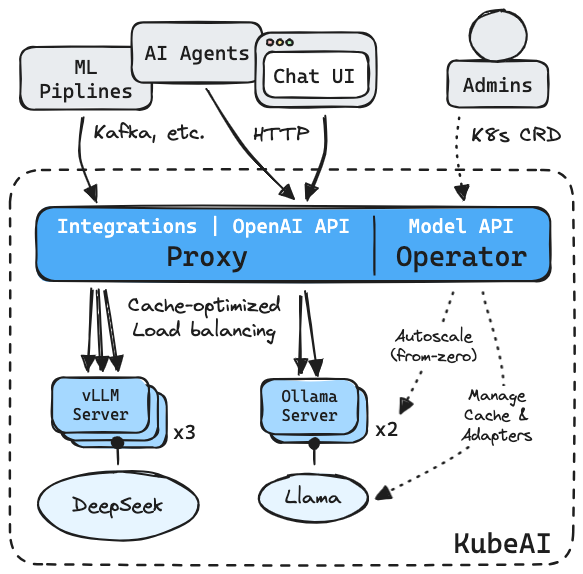
Ed è qui che entra KubeAI, la ragione per cui stiamo facendo tutto questo. Con il suo helm chart e un values file dedicato alle GPU NVIDIA, l’infrastruttura diventa davvero un AI runtime scalabile. Il trucco è semplice: Helm installa tutto, tu definisci le risorse, e KubeAI orchestra. Ma la vera arte sta nell’aggiungere un token Hugging Face, perché senza di lui i modelli che richiedono autenticazione restano un miraggio. Una riga di export HF_TOKEN e hai la chiave per aprire il magazzino di modelli di Hugging Face.
Ecco quindi il momento clou: deploy del Qwen2.5-7B-Instruct. Un manifesto YAML che racconta al cluster la favola di un modello con features TextGeneration, engine VLLM e resourceProfile nvidia-gpu-l40:1. Qui la sintassi non è poesia, è potere. Applichi con kubectl e ti siedi ad aspettare che il pod scarichi gigabyte di pesi dal repository Hugging Face. È il momento in cui la tua connessione Internet diventa il vero collo di bottiglia. Una volta che il pod entra in Running, hai fatto l’impossibile: hai messo un LLM da miliardi di parametri a girare sul tuo piccolo cluster k3s.
A questo punto serve solo il tocco finale: renderlo accessibile. E qui entra il gioco delle matrioske digitali. Prima crei un tunnel SSH dal tuo portatile al server remoto, un 8080:localhost:8080 che sembra innocuo ma che in realtà è il ponte tra due mondi. Poi, sul server, fai un port-forward del servizio KubeAI, aprendo la porta 80 del pod e legandola alla tua 8080 locale. Una danza elegante tra SSH e Kubernetes che ti regala la magia di aprire un browser e parlare con il tuo modello da http://localhost:8080. Non serve spiegare che la prima interazione è sempre banale, un “Qual è la capitale della Francia?”. Ma dietro quella risposta c’è tutta l’infrastruttura che hai montato, e la consapevolezza che potresti chiedere qualsiasi cosa a un modello addestrato su una mole sterminata di dati.
Chi crede che tutto finisca qui si sbaglia. Perché ora puoi chiamare il modello via API, orchestrare conversazioni con curl o integrarlo in un servizio aziendale. Puoi spingerlo a dialogare con i tuoi sistemi interni, testarne temperature e limiti di token, stressarlo fino a capire quanto vale davvero in produzione. Ed è qui che la parte provocatoria diventa inevitabile: se una PMI può mettere in piedi un Hugging Face Large Language Model con questa ricetta, cosa impedisce a un’azienda media di liberarsi dalla dipendenza cieca dai grandi provider americani?
Il deploy LLMs con KubeAI su k3s dentro Seeweb dimostra che il controllo dell’intelligenza artificiale non è monopolio delle Big Tech, ma un territorio che chi ha coraggio e competenza può conquistare. Certo, non è un percorso per tutti, richiede risorse, pazienza e una mentalità ingegneristica che non si insegna nei webinar. Ma la lezione è chiara: chi sa domare un mostro come Qwen2.5-7B-Instruct, sa costruire infrastrutture che non dipendono più da infrastrutture altrui. E in un mondo in cui l’autonomia tecnologica è la nuova valuta del potere, questa è la vera vittoria.
GUIDA QUI: https://blog.seeweb.it/guide-deploying-llms-with-kubeai-on-k3s-ubuntu/