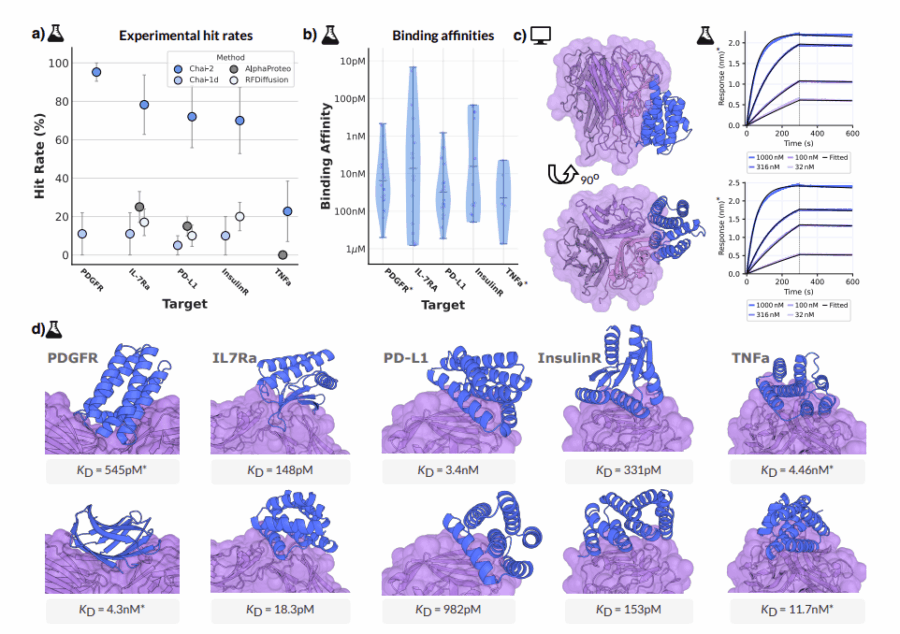
Per anni ci siamo raccontati che i dati fossero il nuovo petrolio. Una narrazione comoda, elegante, quasi poetica, che dava un senso alle guerre silenziose combattute a colpi di privacy policy e scraping selvaggi. Ma mentre l’industria dell’intelligenza artificiale entra in una fase muscolare, fatta di centri dati da miliardi e chip che costano quanto miniere d’oro, una nuova verità emerge, brutale e ineludibile: è il compute, non i dati, a decidere chi guida e chi insegue.
Il report di Konstantin Pilz, James M. S., Robi Rahman e Lennart Heim, che analizza oltre 500 supercomputer AI tra il 2019 e il 2025, è una specie di radiografia del cuore pulsante dell’economia cognitiva. Altro che narrativa da laboratorio accademico. Qui si parla di infrastrutture pesanti, di consumi energetici che rivaleggiano con piccole nazioni, e di una concentrazione di potere computazionale che fa impallidire anche i più accaniti critici del capitalismo digitale.
Il trend più impressionante? Le performance di calcolo stanno raddoppiando ogni 9 mesi. Avete letto bene: siamo in un’era in cui la velocità con cui raddoppiano le capacità computazionali supera persino la mitica Legge di Moore. E ogni raddoppio non è un semplice upgrade. È un salto quantico che permette ad alcune entità poche, selezionatissime di costruire modelli sempre più grandi, sempre più potenti, sempre più inaccessibili.
Leggi tutto