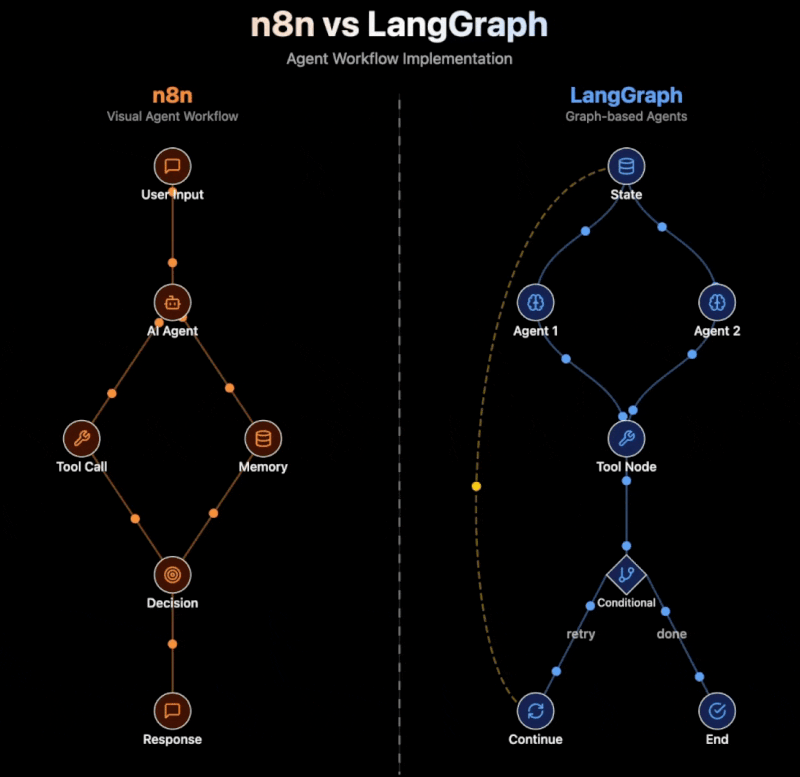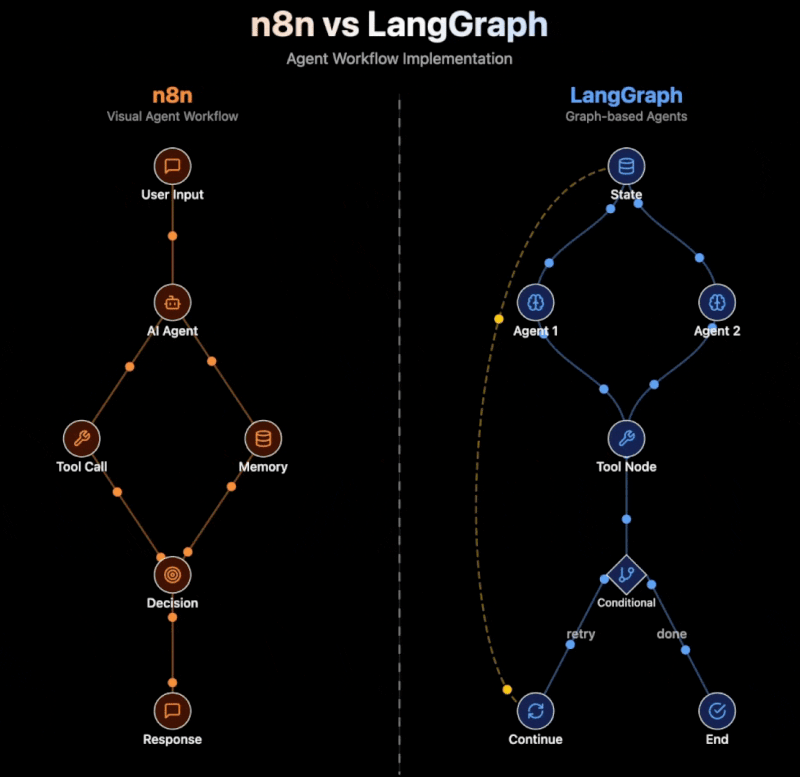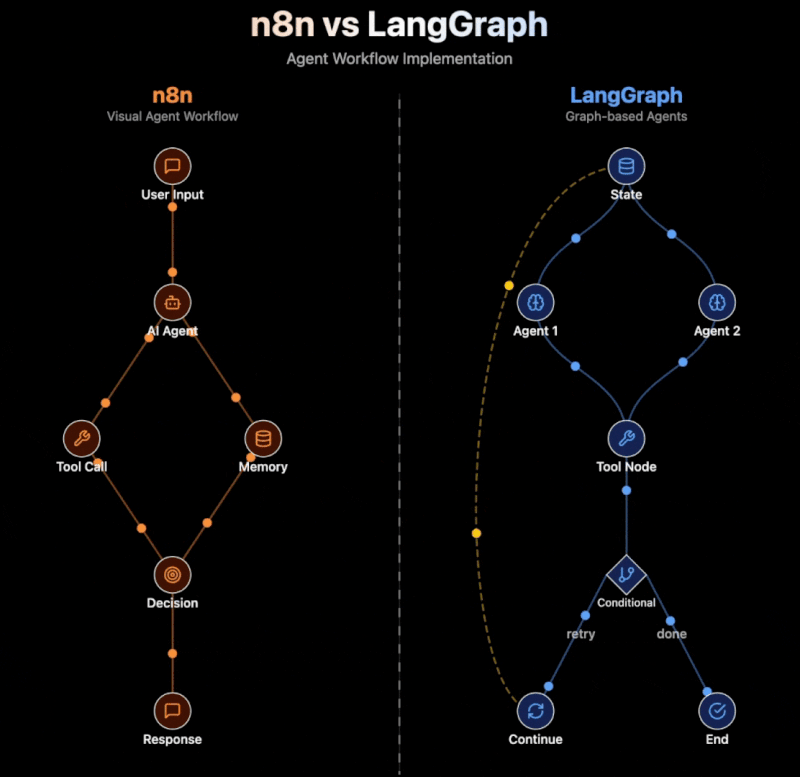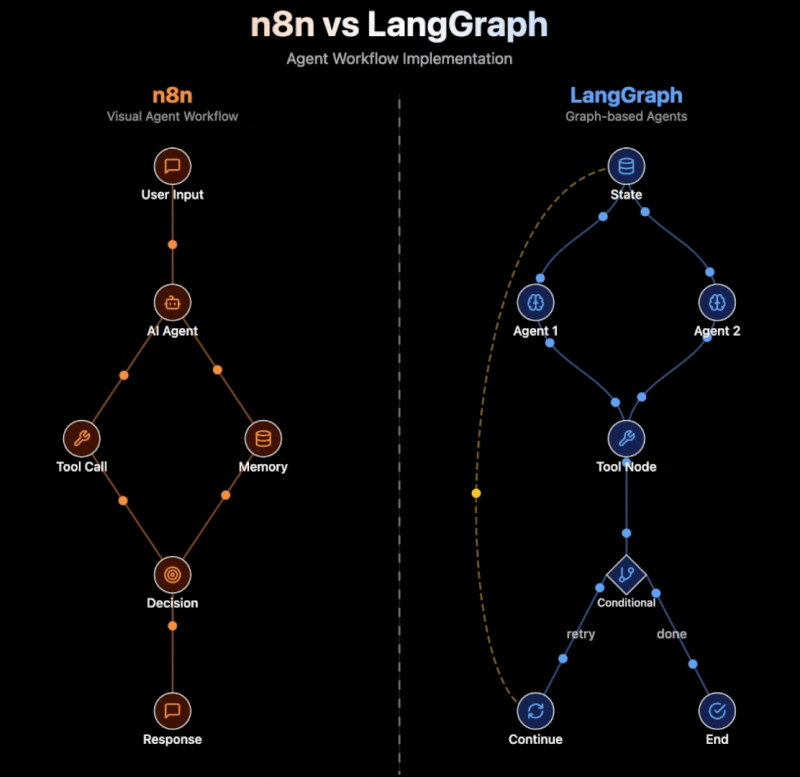
Negli ultimi tempi, mi sono trovato a rispondere a una domanda che sembra stuzzicare sempre di più la curiosità delle persone: qual è la differenza tra Generative AI, AI Agents e Agentic AI? Lasciatemi spiegare, senza entrare nel terreno paludoso del gergo tecnico, come distinguo solitamente queste categorie di intelligenza artificiale.
Generative AI: L’assistente ultra-intelligente ma senza iniziativa
La Generative AI è probabilmente ciò che la maggior parte delle persone pensa quando sente parlare di “AI”. È quella tecnologia che permette di generare contenuti: scrivere articoli, creare immagini, aiutare nella scrittura di codice e molto altro. Questi strumenti sono, essenzialmente, come assistenti super-intelligenti, ma con un grande limite: agiscono solo quando vengono sollecitati. Non prendono iniziativa, non hanno memoria e non possiedono obiettivi propri. Gli esempi classici di Generative AI sono ChatGPT, Claude, GitHub Copilot, e simili.
Questi strumenti sono fantastici per eseguire compiti specifici, ma la loro intelligenza è passiva, limitata a ciò che gli viene chiesto. Non sono in grado di proseguire da soli una volta che il comando viene eseguito. Non c’è evoluzione del processo e nessuna capacità di adattamento. È come avere un assistente brillante, ma che necessita sempre di input diretti.
Leggi tutto