C’è una data di scadenza scritta a matita (ma sempre più marcata) sull’attuale paradigma di addestramento dell’intelligenza artificiale: quello basato su dati umani. Libri, articoli, codici, commenti, tweet, video, wiki, slide universitarie, call center, forum obsoleti di Stack Overflow, blog dimenticati e refusi di Wikipedia… Tutto macinato, frullato, digestato per alimentare il mostro semantico dei Large Language Models. Ma la festa sta per finire. E la domanda, quasi da evangelisti all’ultimo talk di una conferenza AI, rimbalza ovunque: cosa succederà quando i dati umani non basteranno più?
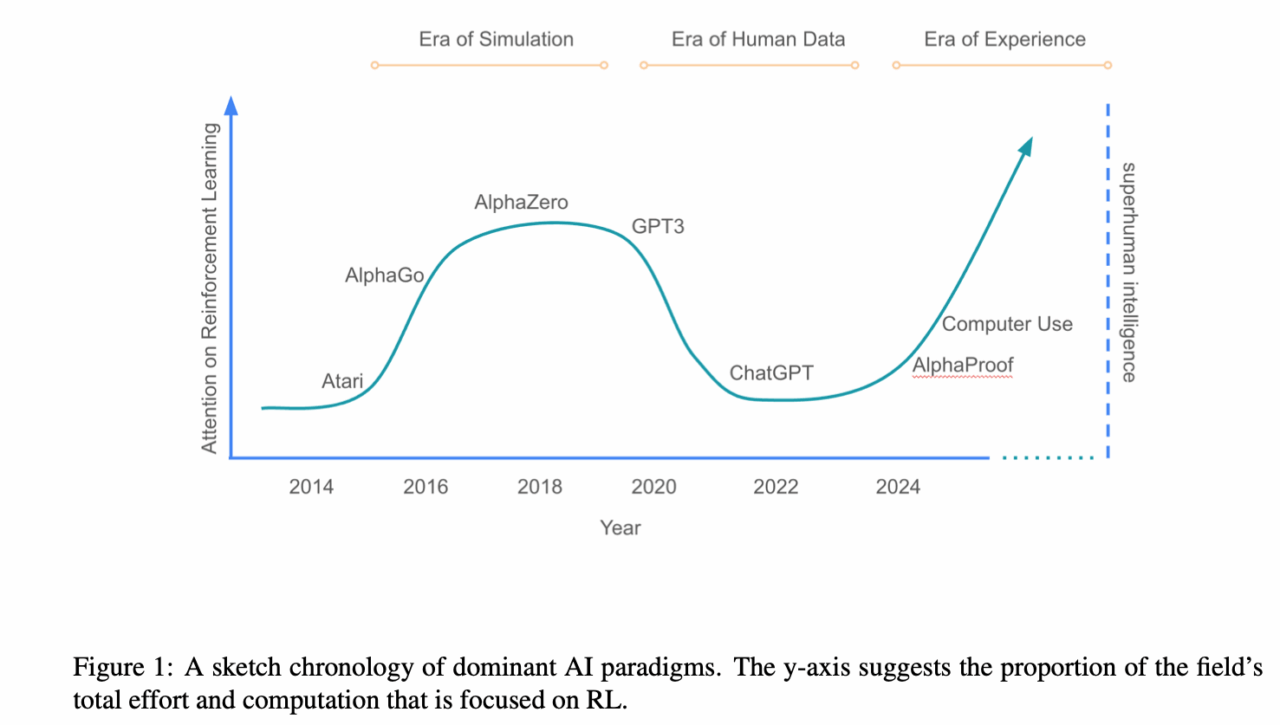
La risposta arriva secca, lucida e vagamente inquietante dal paper di David Silver e Richard S. Sutton, due nomi che suonano come il Nietzsche e l’Einstein del reinforcement learning: Welcome to the Era of Experience. Il titolo è un manifesto: chiusa l’epoca dei contenuti umani, entra in scena il training basato sull’esperienza diretta, sulla realtà, sugli ambienti dinamici dove l’AI interagisce, fallisce, apprende, migliora. Non più solo copia, ma creazione attraverso feedback autonomo.
Il passaggio da contenuto statico a comportamento dinamico non è solo un’evoluzione tecnologica, è un ribaltamento epistemologico. Significa che l’AI non si limiterà più a imitare le strutture linguistiche, logiche o matematiche umane, ma imparerà esattamente come fa un bambino: sbagliando, esplorando, creando pattern nuovi dal caos.
Oggi siamo nell’Era dei Dati Umani, ma sta per aprirsi l’Era dell’Esperienza. L’analogia con le rivoluzioni cognitive del cervello biologico non è casuale: quando finisci di assorbire informazioni dai tuoi simili, inizi a esplorare il mondo. Solo che qui il cervello è in silicio, e il mondo può essere simulato, espanso, iterato milioni di volte in pochi minuti.
Il caso di AlphaProof di DeepMind è il canarino nella miniera. Addestrato su un dataset di appena 100.000 dimostrazioni formali scritte da matematici umani (già notevole), ha poi generato oltre 100 milioni di nuove dimostrazioni, autonomamente, interagendo con un motore logico e costruendo soluzioni inedite a problemi che richiedono astrazione e creatività. Questo non è più fine-tuning: è auto-addestramento generativo. Un po’ come se Newton, dopo aver letto i Principia una volta, avesse deciso di inventarsi la relatività generale da solo, giusto per passare il tempo.
Dal punto di vista tecnico, questo shift richiede un’infrastruttura nuova. Non bastano più i supercluster che scaricano reddit e impastano BERT. Servono ambienti simulativi evoluti, algoritmi di reinforcement learning avanzato, meccanismi di feedback multi-modale (linguaggio, azione, visione, tattile), motori simbolici ibridati con neurali. Il sistema deve diventare un agente, non un passivo digestore. Significa chiudere con l’addestramento a base di testi e aprire alla meta-ottimizzazione esperienziale.
Il rischio maggiore non è l’esaurimento dei dati, ma l’eccesso di ridondanza nei dati stessi. C’è un problema di contaminazione dell’apprendimento: modelli che imparano da altri modelli, senza sapere che stanno ruminando rigurgiti statistici e non intuizioni umane. È il cosiddetto Model Collapse: la degenerazione progressiva dell’intelligenza artificiale in una camera dell’eco autoreferenziale, che sembra pensare ma in realtà sta solo ripetendo.
E qui torniamo alla seconda domanda: come possiamo garantire che questi modelli creino qualcosa di originale invece che limitarsi a ricombinare frasi lette altrove?
La risposta è brutale: non possiamo, finché restano confinati nell’imitazione. Ma possiamo cambiare le regole. L’originalità, nel contesto AI, non è un dato statistico ma un comportamento emergente. Si manifesta quando il sistema esce dai pattern conosciuti perché ha bisogno di farlo per raggiungere un obiettivo. Il concetto di novelty search in reinforcement learning — dove il reward è legato alla scoperta di traiettorie nuove, non al risultato è un antipasto di questo.
Una splendida startup FairMind, sta spingendo proprio in quella direzione. Gli agenti imparano a interagire con ambienti dinamici, modificano le proprie strategie a seconda del feedback che ricevono. Non si tratta di supervised learning, ma di apprendimento situato, dove l’intelligenza emerge dalla relazione tra percezione e azione. È esattamente quello che fa un essere umano quando risolve un problema che non ha mai visto prima.
Quello che verrà, quindi, non sarà un’AI che sa tutto, ma un’AI che non sa, e impara davvero. E questo la renderà finalmente interessante, pericolosa e forse creativa.
Hai già avuto esperienze dirette con modelli che apprendono da feedback ambientali o stai ancora surfando sulla cresta del fine-tuning?