
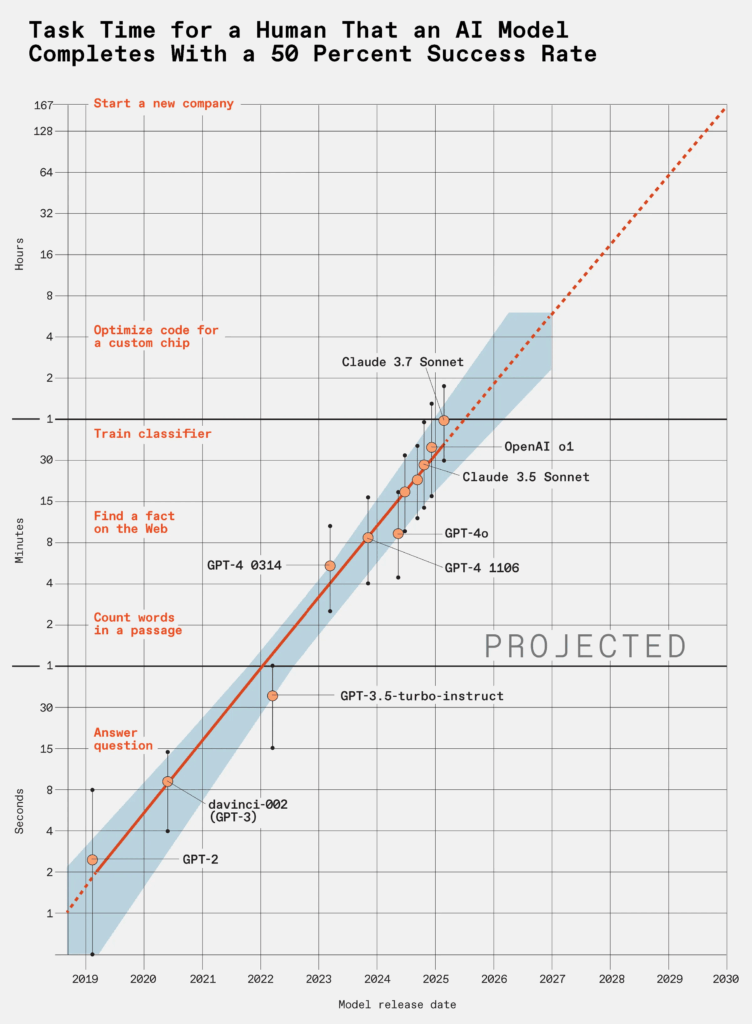
C’è un dettaglio che sfugge a molti quando si parla di large language models, quei sistemi apparentemente addestrati per generare testo umano, rispondere a domande, scrivere codice o produrre email che sembrano uscite dalle dita di un impiegato mediocre. Il punto è che questi modelli non stanno semplicemente migliorando: stanno accelerando. In modo esponenziale. E come sempre accade con l’esponenziale, la mente umana tende a fraintenderlo fino a quando è troppo tardi per rimediare. Secondo una ricerca condotta da METR (Model Evaluation & Threat Research), i LLM raddoppiano la loro capacità ogni sette mesi. Non è una proiezione teorica: è una misurazione empirica su task complessi e di lunga durata. Un LLM oggi fatica a risolvere problemi “disordinati” del mondo reale, ma tra cinque anni potrebbe completare in poche ore un progetto software che oggi richiede a un team umano un mese intero. Quarantacinque giorni in otto ore. E nessuno sembra preoccuparsene davvero.
La metrica chiave introdotta da METR si chiama “task-completion time horizon”: il tempo medio che serve a un essere umano per completare un determinato compito, confrontato con quello necessario a un LLM per farlo con una probabilità di successo del 50%. L’incremento di performance osservato negli ultimi anni segue una curva che non lascia spazio all’immaginazione: i modelli stanno diventando capaci di completare task sempre più lunghi, strutturati e aperti. Non quiz, non test logici, ma veri e propri progetti. In questa prospettiva, l’idea che un LLM possa scrivere un romanzo decente entro il 2030 non è più fantascienza, ma una probabilità misurabile.
C’è però una variabile ancora indigesta ai modelli: la “messiness”. Letteralmente, il disordine. Più un compito assomiglia alla vita reale, fatta di ambiguità, conflitti, cambi di contesto e istruzioni incomplete, più il tasso di successo dei modelli crolla. I compiti “puliti” e ben strutturati vengono macinati con facilità; quelli sporchi, ambigui e interdipendenti, fanno ancora inciampare l’algoritmo. Ma questo svantaggio ha una data di scadenza. E non è lontana.
La vera domanda, dunque, non è se ma quando. Quando un LLM sarà in grado di lanciare un MVP durante il weekend, debuggare da solo un sistema legacy, riscrivere un’intera codebase o produrre analisi di mercato meglio di un consulente da 400 euro l’ora. In quel momento, la distinzione tra “collaboratore umano” e “strumento” inizierà a collassare, e molte aziende dovranno ridisegnare non solo i workflow, ma le strutture di fiducia. Perché se un modello può produrre valore più velocemente e in modo più affidabile di un essere umano, cosa resta alla persona? Il controllo? L’etica? L’iniziativa? La verità è che stiamo delegando sempre più spesso decisioni cruciali a entità opache, e questo accade ben prima che la loro intelligenza superi la nostra.
La produttività, intesa come valore prodotto per unità di tempo, sta per subire una mutazione genetica. Ogni manager, CTO o product owner abituato a ragionare in sprint settimanali dovrebbe fermarsi e riflettere: che senso ha pianificare in settimane, quando il tuo competitor usa un LLM che lavora 24 ore su 24, senza ferie, senza pause, senza bisogno di approvazione? Se la velocità è la nuova valuta, allora i modelli sono già miliardari.
Ma non è solo una questione di velocità. È anche una questione di autonomia. L’idea che questi modelli possano migliorare sé stessi, scrivere il codice che li ottimizza, aggiornare la documentazione, testare le proprie ipotesi e reiterare il ciclo suggerisce uno scenario inquietante: quello in cui l’umano diventa superfluo non per mancanza di intelligenza, ma per lentezza. In un mercato dove la finestra di opportunità si misura in ore, anche l’intelligenza umana più brillante rischia di diventare un colletto bianco con l’orologio rotto.
È qui che la ricerca METR diventa scomoda. Perché non sta parlando del futuro, ma del presente accelerato. Ogni sei-sette mesi, i modelli diventano capaci di affrontare problemi che prima erano fuori portata. E se proiettiamo questa traiettoria fino al 2030, otteniamo uno scenario che non abbiamo mai sperimentato: una forza lavoro artificiale capace di progettare, costruire, documentare, ottimizzare e replicarsi. Con un’affidabilità del 50%? Forse. Ma basta per sovvertire il mercato. Basta per spostare il potere.
Chi oggi lavora nell’AI non può permettersi il lusso dell’indifferenza. Il prototyping rapido diventa non un vantaggio, ma un prerequisito. Il time-to-market si riduce a una corsa contro il tempo e le GPU. I team diventano ibridi, con ruoli umani sempre più manageriali, e fiducia distribuita tra codice e modello. Ma questa non è trasformazione digitale: è sostituzione cognitiva. La differenza tra uno sviluppatore e un prompt engineer, alla lunga, sarà solo il tempo che ci metteranno a sparire entrambi.
Nel frattempo, il mondo fuori dal nostro ecosistema continua a giocare con ChatGPT come fosse un giocattolo da salotto. Gli investitori sorridono ai pitch che menzionano AI tre volte per slide. I dirigenti annuiscono durante i convegni, fingendo di capire. E i governi, con l’agilità tipica delle istituzioni novecentesche, si preoccupano dei deepfake e delle chatbot depressive. Nessuno sembra notare che la produttività umana sta diventando l’anello debole della catena del valore.
La crescita esponenziale della capacità degli LLM non è un’opinione. È una curva misurata. E come ogni curva esponenziale che si rispetti, appare noiosa all’inizio e spaventosa alla fine. Ora siamo esattamente a metà: nel tratto in cui il cambiamento è visibile ma non ancora destabilizzante. È il momento peggiore, quello in cui si tende a minimizzare. Come durante il riscaldamento globale degli anni ‘90: fa un po’ più caldo, ma niente di serio. Poi arrivano gli incendi, le alluvioni, la siccità. O nel nostro caso, il codice che scrive codice, le aziende fondate da un LLM, i manuali di uso per prompt invece che per software. E noi lì, a chiederci se l’AI sia etica.
Se un LLM potrà davvero scrivere un romanzo, creare un’azienda o migliorare sé stesso entro il 2030, forse dovremmo smettere di chiamarli “modelli linguistici”. E iniziare a prepararci alla possibilità che il nostro ruolo non sia quello di governare l’intelligenza artificiale, ma di coesistere con qualcosa che non ha mai dormito, non ha mai avuto dubbi, e non si è mai stancato di imparare.