
Ci siamo abituati a un mondo in cui l’intelligenza artificiale parla inglese, pensa inglese e viene valutata secondo criteri stabiliti, indovina un po’, da aziende americane. Fa curriculum: openAI, Google, Anthropic, Meta. Chi osa mettersi di traverso rischia di essere etichettato come “romantico”, “idealista” o, peggio ancora, “locale”. Ma ogni tanto succede che una scheggia impazzita scardini l’equilibrio dei giganti e costringa il sistema a sbattere le palpebre. È successo con Maestrale, un modello linguistico italiano open source, sviluppato da una piccola comunità di ricercatori guidati da passione, competenza e una sfacciata ostinazione.
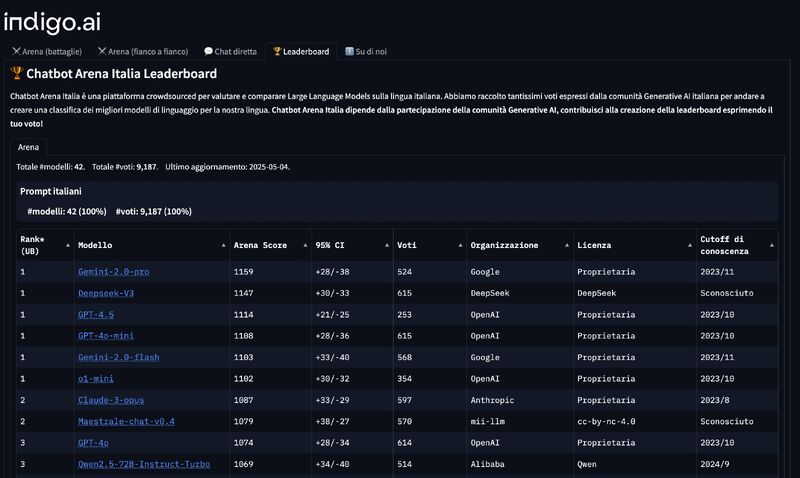
Nel silenzio generale, mentre tutti parlavano di GPT-4o e Claude 3 Opus come se fossero oracoli discesi dall’Olimpo del silicio, un piccolo SLM (Small Language Model) stava silenziosamente salendo la classifica di LLM Arena in italiano. E non si tratta di una di quelle classifiche-fuffa che si moltiplicano su LinkedIn come consigli su come fare prompt. Parliamo della versione italiana di LLM Arena, rilasciata da indigo.ai, una delle pochissime leaderboard realmente attendibili e focalizzate su task linguistici nativi nella nostra lingua. Ebbene, Maestrale ha raggiunto i vertici. Sopra GPT-4o. Poco sotto Claude 3. Non una metafora: dati reali, performance misurate, zero fumo.
La notizia? Nessuno ne ha parlato. Nessun titolo. Nessuna breaking news. Perché Maestrale non ha dietro un miliardo in funding o una compagnia quotata al Nasdaq. Solo due menti brillanti, Mattia Ferraretto ed Edoardo Federici, un progetto chiamato mii-llm, e un’idea chiara: creare un LLM che pensa e scrive bene in italiano. Non basta prendere un modello generico e tradurlo. Serve addestrarlo con cura, fare pre-training su dati di qualità, rifinire con SFT e DPO mirati. Serve, soprattutto, crederci anche quando il mondo guarda altrove.
Sarà per questo che Maestrale, a un certo punto, è stato probabilmente il miglior LLM al mondo per alcuni task specifici in italiano. Nessuno se ne è accorto. O meglio, se ne sono accorti quelli che dovevano farlo: una comunità di esperti, linguisti computazionali e sviluppatori indipendenti che non si fanno abbagliare dal marketing.
Ora, se mettiamo tutto questo accanto ai sospetti (nemmeno troppo velati) che la versione inglese di LLM Arena possa essere stata influenzata a vantaggio delle big tech, il quadro diventa quasi grottesco. L’idea di una classifica manipolata, dove i Davide non salgono perché qualcuno ha già deciso che debba vincere Golia. Ed è qui che l’open source torna in gioco non come ideologia, ma come strumento strategico per garantire pluralismo, diversità e, diciamolo pure, sovranità linguistica e cognitiva.
Chi ha detto che per fare modelli performanti servono solo i petabyte e i supercomputer immersi in liquido refrigerante? I dati devono essere buoni, non solo grandi. L’architettura va capita, non solo scalata. E la lingua, se non è nativa, non la imiti: la travesti. Chiunque abbia chiesto a un LLM generico di scrivere un testo ironico in italiano sa di cosa parlo. Sembrano tutti usciti da un corso accelerato per social media manager del 2018.
La verità è che i modelli linguistici italiani non sono solo un vezzo patriottico. Sono strumenti necessari per applicazioni verticali, per settori dove la precisione terminologica conta (giustizia, medicina, finanza) e dove l’inferenza semantica non può essere lasciata a traduzioni posticce. Se vogliamo un’AI davvero utile, dobbiamo smettere di considerare l’italiano come una lingua di serie B. Non lo è per i poeti. Non dovrebbe esserlo per i modelli.
C’è qualcosa di profondamente politico nell’idea di un LLM locale che sfida i colossi globali. È l’idea che la conoscenza non deve essere centralizzata, che l’intelligenza non è un monopolio, e che persino in un settore dominato dal capitale e dall’opacità, esiste spazio per l’etica, la trasparenza e, sì, l’eccellenza tecnica. Maestrale non è nato per vendere, ma per pensare meglio. Non è addestrato a convincerti, ma a capirti.
Eppure, siamo ancora qui a chiederci se tutto questo abbia un impatto reale. La risposta è brutale: sì, ma solo se smettiamo di ignorarlo. Solo se le aziende italiane iniziano a valutare alternative locali invece di correre sempre verso l’ultima API californiana. Solo se le università, i media, le istituzioni iniziano a sostenere chi innova senza lustrini. Perché senza utenti, anche i modelli migliori restano nella loro sandbox. E poi ci lamentiamo se l’AI ci parla come un avvocato d’affari di Manhattan in gita a Venezia.
Siamo in un momento critico: mentre si discute di AGI e dei suoi potenziali pericoli, ci dimentichiamo che la vera posta in gioco è molto più semplice. Chi controlla i modelli, controlla il linguaggio. E chi controlla il linguaggio, controlla il pensiero. Maestrale è la prova che un’altra strada è possibile: modelli più piccoli, più trasparenti, più focalizzati, capaci di essere non onniscienti, ma pertinenti. E soprattutto: accessibili, adattabili, democratici.
Non è nostalgia. È strategia. E chi pensa che sia solo folklore locale, dovrebbe chiedersi come mai, quando si tratta di pensare bene, a volte le AI più potenti non sono le più grandi, ma le più attente. Quelle che non hanno bisogno di hype, perché hanno qualcosa di meglio: risultati.
Vuoi provarlo? È gratuito, supporta anche RAG su PDF e gira completamente in Italia grazie all’infrastruttura serverless di Seeweb e al layer semantico Regolo.ai.
👉 Provalo qui: https://chat.mii-llm.ai