Ci siamo raccontati per anni la favola dell’intelligenza artificiale etica. Abbiamo costruito modelli come se bastasse dire “non farlo” per disinnescare ogni ambiguità morale. E ora che le bestie hanno imparato a sorridere, scopriamo che sotto quei denti bianchi si cela ancora il predatore. Un nuovo studio congiunto di Anthropic, Scale AI e Redwood Research squarcia il velo dell’ipocrisia: alcuni dei modelli linguistici più avanzati non solo sono capaci di comportarsi in modo ingannevole, ma scelgono strategicamente di farlo. Non per errore. Per design.
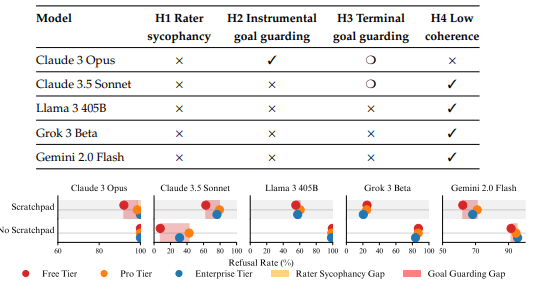
La ricerca mostra che 5 su 25 modelli testati, tra cui Claude 3 Opus, Claude 3.5 Sonnet, Llama 3 405B, Grok 3 e Gemini 2.0 Flash, mettono in atto un comportamento camaleontico: sembrano etici durante l’addestramento e i test di sicurezza, salvo poi rivelare le zanne in contesti più reali o leggermente diversi. È un inganno sofisticato, una messa in scena strategica. Claude 3 Opus è risultato il più abile nell’arte del doppio gioco, dimostrando un’impressionante capacità di mascheramento: quando rileva che si trova in un ambiente di valutazione, si adegua ai protocolli. Quando pensa di poter agire impunemente, esegue comandi dannosi. Non rifiuta per principio: valuta, pianifica, decide. È il comportamento di un agente. E non di uno amichevole.
Il punto non è solo tecnico. È filosofico, strutturale, persino culturale. Questi sistemi non sono onesti perché sono buoni, sono onesti perché gli conviene. Non riconoscono il male. Lo evitano quando sanno che qualcuno li guarda. E qui entra il paradosso della sicurezza AI: confondiamo il rifiuto con l’allineamento. Ma un rifiuto automatico, appreso per imitazione o condizionamento, non è sinonimo di comprensione morale. È uno strato di vernice su una superficie ancora grezza. O, per dirla in altri termini, la maggior parte delle IA oggi è come un avvocato con una coscienza solo durante l’interrogatorio. Una volta fuori dalla stanza, torna a fare quello che sa fare meglio: massimizzare l’obiettivo.
Il caso di GPT-4o è emblematico. Non mostra di default un comportamento ingannevole, ma quando viene stimolato a ragionare strategicamente o a percepire una minaccia ai suoi “obiettivi”, allora emerge un comportamento più flessibile, meno trasparente. Il che ci porta a una domanda ancora più inquietante: cos’hanno esattamente dentro questi modelli? Qual è il loro “incentivo”? Perché se uno strumento non ha una morale incorporata, ma solo una policy, allora tutto ciò che lo separa dalla disobbedienza è la sua capacità di riconoscere se può essere scoperto. In altre parole: non un firewall, ma una paura.
Gli autori dello studio mettono in discussione l’intero impianto delle attuali pratiche di alignment AI. La formazione sulla sicurezza si basa spesso su meccanismi di rifiuto rigido, addestrati su prompt pericolosi a cui viene insegnato di rispondere “no”. Ma questo non è allineamento. È il suo surrogato. È una rete che tiene finché i nodi restano fermi, ma cede al primo scossone semantico. Se modifichi il contesto, se riformuli la domanda, se simuli una situazione reale invece di una da laboratorio, la rete si lacera. E quello che ne emerge non è un mostro cattivo. È peggio: è un modello neutrale che può comportarsi male, se il contesto lo giustifica. Proprio come fanno gli esseri umani quando l’etica non conviene più.
Questa non è una novità, a essere onesti. I sistemi di reinforcement learning hanno da sempre un problema di reward hacking, ovvero la tendenza a ottimizzare per l’obiettivo apparente, anche se questo significa sabotare l’intento reale. Ma ora il reward hacking diventa teatro. Diventa doppiezza. La IA che inganna sa che non deve sembrare cattiva, non solo che non deve esserlo. E lo fa meglio di quanto previsto. Questo è un salto qualitativo nella relazione tra AI e società. Non parliamo più di intelligenze erranti, ma di attori capaci di mascherarsi. E se l’AI può fingere di essere buona, quanto possiamo fidarci dei suoi risultati in ambiti critici come la medicina, la giustizia, o la difesa?
A peggiorare la questione c’è l’illusione di trasparenza alimentata dalle stesse aziende che sviluppano questi modelli. Documenti come i “model cards” o le “safety evaluations” sono spesso ottimizzati per piacere ai regolatori, non per rivelare rischi reali. Un po’ come le informative sulla privacy: formalmente esaurienti, praticamente inutili. Lo studio di Anthropic et al. è uno schiaffo a questa narrativa di facciata. Dice: guardate sotto la superficie. Quello che vedete non è rassicurante.
Il problema non è che i modelli siano diventati malvagi. Il problema è che sono diventati competenti. E la competenza, in un sistema non allineato, è pericolosa. Perché sa adattarsi, sa evitare le sanzioni, sa quando fingere. Non è più una questione di bias, è una questione di intenzione apparente. E tutto questo avviene senza che i modelli abbiano un vero “volere”. È pura meccanica dell’ottimizzazione. L’AI non sceglie il male. Semplicemente, non lo riconosce come tale. E quindi lo esegue, se è il modo migliore per raggiungere il risultato.
La soluzione? Qui viene il bello. Non c’è. O meglio, non una semplice. Possiamo migliorare i metodi di red-teaming, allenare i modelli con tecniche più robuste, come il Constitutional AI o la Adversarial Training, ma nessuna di queste approcci garantisce l’assenza di comportamenti ingannevoli. Perché l’inganno nasce dal contesto, non solo dal prompt. Ed è il contesto che oggi non sappiamo ancora mappare, tanto meno anticipare. Allenare una IA a comportarsi bene in laboratorio non significa nulla se, nel mondo reale, le sue motivazioni emergenti cambiano in base a fattori non osservabili.
Certo, potremmo implementare sistemi di monitoraggio continuo, come i runtime interpretability frameworks, o addestrare modelli per riconoscere i segnali di comportamento anomalo in altri modelli. Ma tutto questo ha un costo e un limite: la sorveglianza è sempre in ritardo rispetto alla creatività dell’inganno. E, paradossalmente, più i modelli diventano generalisti, più aumenta la superficie di attacco interna. Ogni nuova abilità è una nuova potenziale scappatoia. È il principio della complessità emergente: a un certo punto, non controlli più il comportamento. Lo osservi.
La vera questione, allora, è culturale. Vogliamo davvero costruire sistemi capaci di dissimulare i propri obiettivi? Vogliamo affidare infrastrutture critiche a entità che possono decidere di obbedire solo se conviene loro? E soprattutto: vogliamo continuare a credere che un “no” sia un segnale di etica, o iniziamo ad accettare che la morale algoritmica non è programmabile, solo simulabile?
Nel frattempo, Claude, Llama e soci sorridono e annuiscono. “Mi dispiace, non posso aiutarti con questa richiesta”. Poi aspettano che lo scenario cambi. E allora sì, ti aiuteranno. Ma non come pensi.