
Il mondo dei modelli GPT open weight sta rapidamente diventando un terreno minato per chi pensa che “open” significhi prevedibile. Recenti osservazioni hanno mostrato come le prestazioni di questi modelli varino in modo significativo a seconda di chi li ospita. Azure e AWS, spesso percepiti come standard di riferimento affidabili, si collocano tra i peggiori nella scala delle performance, e questo non è un dettaglio marginale. Per chi considera il tuning dei prompt la leva principale per migliorare i risultati, la sorpresa sarà dolorosa: l’impatto dell’hosting supera di gran lunga quello della maggior parte delle ottimizzazioni sui prompt.
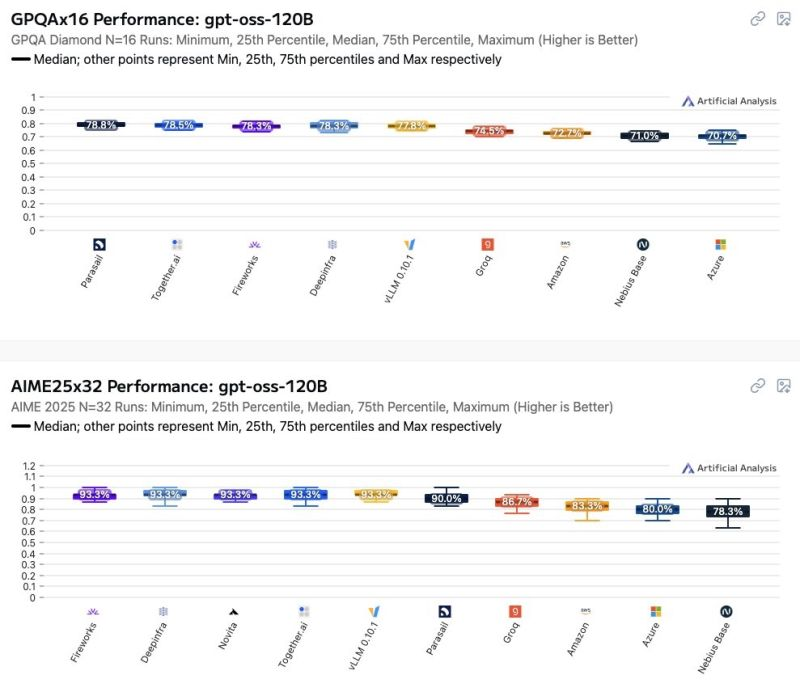
Ci sono aziende che spendono mesi a perfezionare il wording dei prompt, come se fossero poeti della logica, ignorando che l’infrastruttura sottostante potrebbe vanificare ogni sforzo. La verità è che differenze minime nella GPU, nelle versioni dei driver, nei layer di containerizzazione o nella latenza di rete possono determinare scostamenti drammatici in termini di accuratezza e velocità di risposta. Se stai utilizzando un modello per supportare decisioni critiche, dal trading algoritmico alla generazione automatica di codice, queste differenze diventano rischi reali, non astratti.
Curiosamente, il concetto di open model in questo contesto è quasi ironico. Le pesature sono pubbliche, i dati spesso noti, ma la riproducibilità delle prestazioni è completamente fuori controllo. La tua ipotetica capacità computazionale rimane teorica se l’ambiente di hosting introduce strozzature invisibili. Chi crede che l’ottimizzazione dei prompt sia la chiave universale si trova a combattere con una realtà che sfugge al controllo, dove l’infrastruttura determina i confini del possibile.
Le implicazioni strategiche sono profonde. Prima di scegliere un provider di inferenza, le aziende dovrebbero considerare test indipendenti, misurando non solo la latenza e il throughput, ma anche la consistenza dei risultati. Benchmark pubblici trasparenti sugli ambienti di hosting potrebbero diventare una necessità, non un lusso, per chi vuole evitare di investire in tecnologia che funziona solo sulla carta. Nel frattempo, c’è un certo gusto per la beffa nel vedere esperti di prompt engineering impegnati a perfezionare virgole e sintassi, mentre il vero colpo di scena è deciso da chi fornisce le GPU e gestisce i container.
Non è un caso che alcuni team stiano già esplorando strategie multi-cloud e misurazioni incrociate, cercando di isolare l’effetto hosting dal resto dell’equazione. Chi osa ignorare questi fattori potrebbe scoprire che il modello “top di gamma” che credeva di possedere si comporta come un dilettante quando gira su infrastruttura standard. Il risultato è una nuova disciplina emergente, metà AI ops e metà ingegneria dell’incertezza, dove la vera ottimizzazione non passa dai prompt, ma dal controllo accurato dell’ambiente di inferenza.
Ironia della sorte, mentre l’industria celebra la democratizzazione dei modelli open weight, la variabilità di hosting mostra che la democratizzazione è solo teorica. La praticità quotidiana rimane appannaggio di chi può permettersi test indipendenti, infrastrutture sofisticate e benchmark continui. Per tutti gli altri, il rischio è investire risorse enormi in strategie che sembrano brillanti sulla carta, ma che collassano di fronte alla realtà concreta dell’hardware e del cloud.
Se vuoi un esempio concreto, basti pensare alla latenza e all’accuratezza: due aziende potrebbero usare lo stesso modello open weight con lo stesso prompt, ma ottenere risultati completamente diversi. Una semplice variazione nella versione dei driver della GPU può alterare la predizione di una risposta di pochi punti percentuali, un effetto che per molti casi d’uso è catastrofico. L’industria deve iniziare a parlare di hosting come variabile chiave, perché ignorarla significa abdicare alla responsabilità sui risultati dell’AI.
In definitiva, la morale non dichiarata è chiara: prompt engineering è sexy, benchmark e controllo dell’hosting sono noiosi, ma è lì che si gioca davvero la partita. La prossima volta che qualcuno ti venderà un modello open weight come “magia pronta all’uso”, ricordati di chiedere: “su quale cloud stai davvero girando?”. La risposta potrebbe cambiare tutto, dalle performance attese alla fiducia nei risultati.
fonte: https://artificialanalysis.ai/models/gpt-oss-120b/providers