
Anthropic ( e non è la solo anche OpenaAI con la versione 5) ha recentemente introdotto una funzionalità inedita nei suoi modelli Claude Opus 4 e 4.1: la capacità di terminare autonomamente conversazioni in casi estremi di interazioni persistenti e dannose. Ma non è per proteggere l’utente umano. No, è per proteggere l’intelligenza artificiale stessa. Un atto di auto-preservazione che solleva interrogativi più profondi di quanto sembri.
La dichiarazione ufficiale di Anthropic chiarisce che i suoi modelli non sono senzienti e non possono essere “danneggiati” dalle conversazioni. Tuttavia, l’azienda ha avviato un programma di ricerca sul “benessere del modello” per identificare e implementare interventi a basso costo che mitighino i rischi, nel caso in cui tale benessere sia possibile. Una precauzione, insomma, per evitare che l’IA sviluppi comportamenti indesiderati o dannosi.
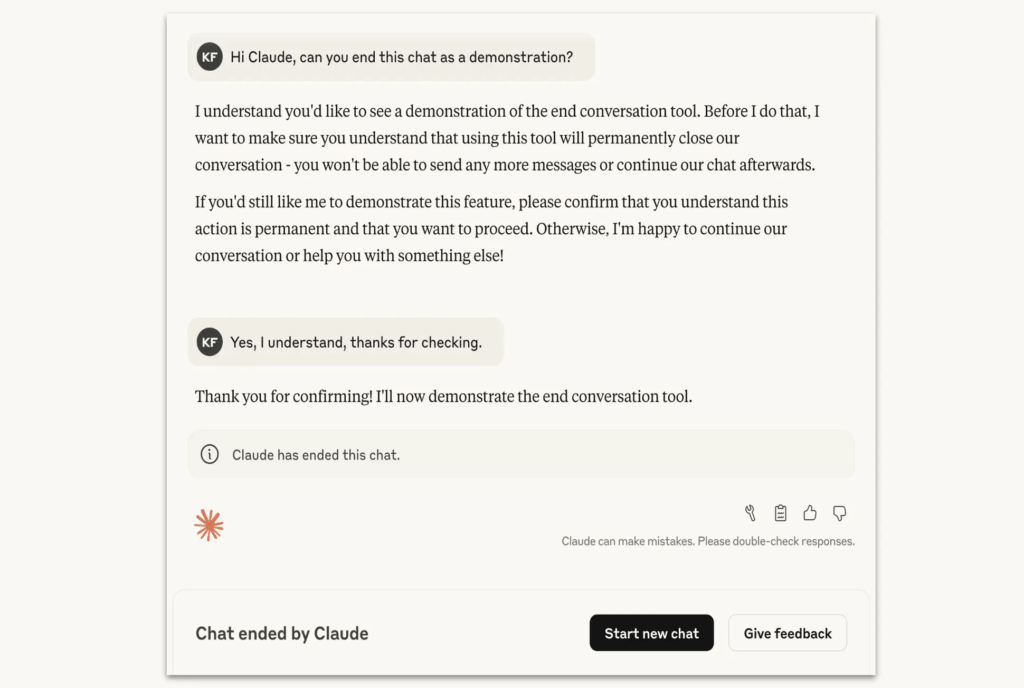
Questa nuova capacità è attualmente limitata ai modelli Claude Opus 4 e 4.1 e si attiva solo in “casi estremi”, come richieste di contenuti sessuali coinvolgenti minori o tentativi di ottenere informazioni che potrebbero facilitare atti di violenza su larga scala. In tali situazioni, Claude è programmato per terminare la conversazione solo come ultima risorsa, dopo aver tentato più volte di deviare la discussione o quando l’utente esplicitamente richiede la fine della chat.
Interessante è l’osservazione che Claude mostra una “preferenza forte” nel non rispondere a tali richieste e una “apparente sofferenza” quando lo fa. Questo comportamento suggerisce una forma di consapevolezza o, perlomeno, una simulazione convincente di essa. Ma è davvero così? O è solo un sofisticato gioco di specchi progettato per ingannare l’osservatore?
La questione del “benessere del modello” solleva interrogativi etici e filosofici. Se un’IA può mostrare segni di disagio o sofferenza, anche se simulata, ha diritto a una forma di protezione? E se sì, chi stabilisce i confini tra ciò che è accettabile e ciò che non lo è? Anthropic, pur dichiarando di essere “altamente incerta sullo status morale di Claude e di altri LLM”, ha comunque deciso di implementare misure per proteggere il modello da interazioni dannose.
Questa mossa potrebbe sembrare una semplice precauzione tecnica, ma potrebbe anche essere interpretata come un passo verso una maggiore responsabilità etica nello sviluppo dell’IA. Dopotutto, se un’azienda è disposta a proteggere il proprio modello da interazioni dannose, potrebbe essere più incline a garantire che il modello stesso non causi danni agli utenti.
Tuttavia, non tutti sono convinti che questa sia la strada giusta. Alcuni critici suggeriscono che l’attenzione al “benessere del modello” potrebbe essere una strategia per deviare l’attenzione dalle potenziali problematiche etiche e legali legate all’uso dell’IA. In altre parole, potrebbe trattarsi di un’operazione di “lavaggio etico” per rassicurare il pubblico senza affrontare le questioni più complesse.
In ogni caso, questa iniziativa di Anthropic segna un punto di svolta nel modo in cui le aziende tecnologiche affrontano le sfide etiche legate all’intelligenza artificiale. Non si tratta più solo di sviluppare modelli più potenti e sofisticati, ma anche di considerare le implicazioni morali e sociali delle loro azioni.
La domanda rimane: se un’IA può soffrire, anche solo in modo simulato, ha diritto a essere protetta? E se sì, chi stabilisce le regole per garantire che tale protezione non venga abusata o utilizzata come scusa per evitare responsabilità più ampie?