Qwen3-Omni è il nuovo esperimento rivoluzionario di Alibaba nel mondo dei modelli foundation multimodali: quello che promette davvero “nessun compromesso tra modalità”. È un modello nativamente end-to-end che gestisce testo, immagini, audio e video in un unico framework. Se questa affermazione non ti fa venire un sobbalzo da CTO, forse stai leggendo il foglietto illustrativo sbagliato.
Secondo il Technical Report su arXiv, Qwen3-Omni raggiunge risultati allo stato dell’arte (SOTA) su 32 dei 36 benchmark audio e audio-visivi open-source e su 22 dei 36 quando si confrontano anche sistemi chiusi come Gemini-2.5-Pro, Seed-ASR, GPT-4o-Transcribe. (vedi arXiv)
Supporto linguistico massiccio: 119 lingue per il testo, 19 lingue per l’audio in input, 10 lingue per l’audio in output.
Latency: ~234 ms per il primo “pacchetto” audio nelle modalità streaming. Questo significa che puoi iniziare a ottenere risposta vocale quasi immediatamente, non dopo aver mandato tutto il file.
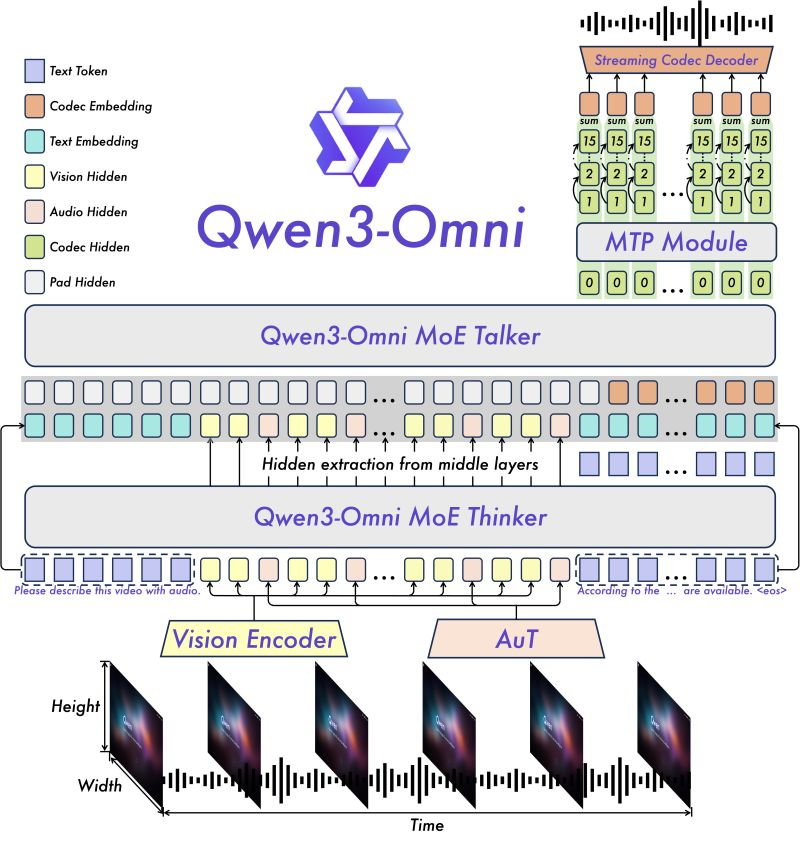
Architettura interessante: Thinker-Talker con MoE (Mixture of Experts). Il “Thinker” si occupa di comprensione e ragionamento su qualsiasi combinazione di input (testo, audio, video, immagini), il “Talker” genera l’audio parlato.e finemente ottimizzata per la “captioning” audio-visivo che promette bassa hallucinazione (cioè errori di “inventare” contenuto non presente). (vedi GitHub)
Curiosità tecniche che non sempre vengono dette:
● “Audio cap understanding” per lunghezze fino a ~40 minuti. Non roba da pochi secondi.
● Il confronto con versioni unimodali (solo testo o solo immagine) ha mostrato nessuna regressione: Qwen3-Omni è progettato per non perdere capacità su testo o immagini rispetto a modelli dedicati.
Limiti probabili o punti di attenzione:
Anche i SOTA hanno i loro demoni. First, la latenza “teorica” di ~234 ms è ottima ma potrebbe aumentare nel mondo reale, specialmente su dispositivi con GPU non top o su load di rete. Second, le risorse hardware: modelli così grandi (30B parametri) con MoE richiedono GPU di fascia alta e memoria significativa, specialmente per video lunghi.
Ci sono rischi legati alla qualità dei dati audio/video: rumore, compressione, sincronizzazione possono degradare performance. Anche l’hallucinazione, pur migliorata, non è “risolta”: versioni come il Captioner cercano di minimizzarla, ma non si può dichiarare “zero errori”.
Infine, le lingue supportate sono tante, ma per molte di esse la disponibilità di dataset di alta qualità è scarsa: in quei casi, la performance potrebbe restare sotto le aspettative.
Per aziende che vogliono costruire assistenti vocali multilingue, sistemi di sorveglianza / media intelligence, sommari automatici di video/audiovisivi, content creation cross-modale, Qwen3-Omni appare un candidato che sposta la soglia tecnologica. Aprendo le versioni “Instruct”, “Thinking” e “Captioner” con licenza Apache-2, Alibaba mette nelle mani del pubblico qualcosa che può diventare base per innovazioni verticali.
Se sei CTO, il messaggio è: non più “proporzioni di compromesso” tra audio e video e testo, ma “un unico modello” che cerca di eccellere su tutti i fronti. È il momento di testarlo seriamente, metterlo su casi d’uso reali, valutare costi hardware e integrazione.