
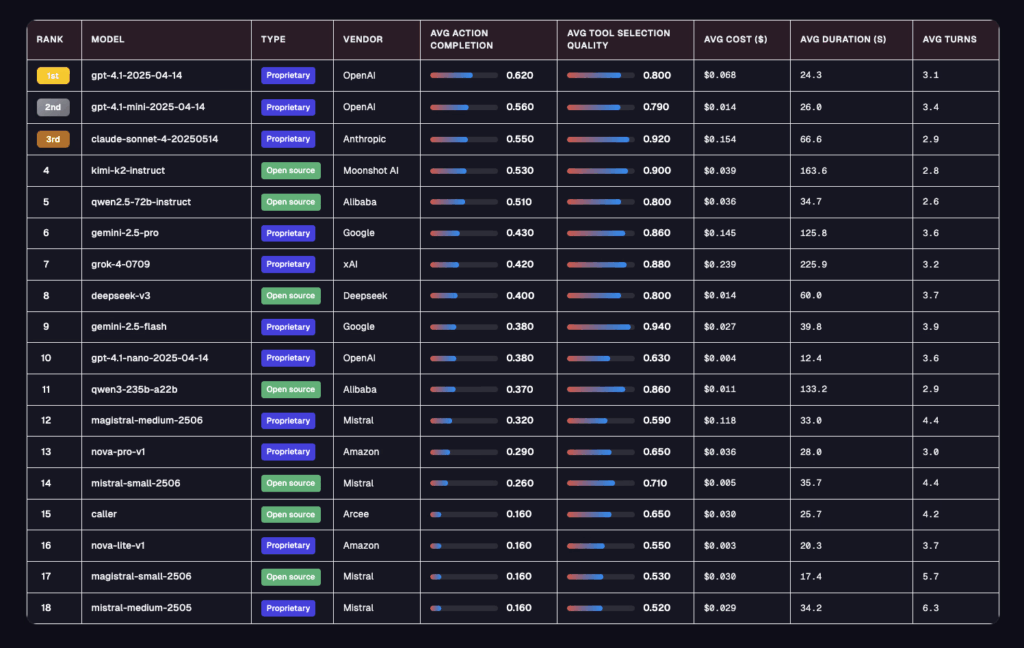
Galileo ha appena sganciato la bomba con il suo agent leaderboard, la valutazione più spietata finora per capire se un agente ai è davvero pronto per il mondo enterprise. Dimentica i soliti benchmark da laboratorio, qui si gioca su 5 settori ad alto rischio, banking, healthcare, insurance, telecom e investment, con oltre 100 conversazioni per dominio e obiettivi intrecciati in 5-8 turni. Niente scorciatoie, solo caos controllato: ambiguità intenzionale, strumenti inutili piazzati apposta, utenti che cambiano idea e dipendenze multi-turn che spezzano i modelli troppo rigidi e la metrica non è più la solita accademica, ma due parametri che pesano davvero in azienda, action completion e tool selection quality.
GPT-4.1 guida la classifica con un onesto 62% di action completion, segno che porta a casa il risultato più spesso degli altri. Ma il premio di precisione nella scelta strumenti se lo prende gemini 2.5 flash, un impressionante 94% tsq che però si sgonfia quando deve chiudere le azioni, solo 38% ac. Il che dimostra un paradosso irritante: puoi scegliere lo strumento giusto e comunque non portare a termine il compito e se pensi che il futuro sia solo closed source, kim k2 mette a tacere qualche scettico, 53% ac e 90% tsq a un costo che fa gola a chi guarda il roi prima della potenza bruta. Per il resto, grok 4 non brilla in nulla e i modelli di ragionamento complesso sembrano arrancare quando il compito è pratico e non teorico.
Qui c’è un cambio di paradigma che pochi sembrano cogliere. non basta più generare risposte credibili, serve capacità di completare azioni reali, adattarsi, coordinarsi, fallire e riprovare. la retorica dei supermodelli onnipotenti si sgonfia quando li metti a fare cose che impattano processi aziendali e clienti veri e sì, serve anche pensare al costo per sessione, perché il miglior compromesso attuale è gpt-4.1-mini a 0,014 dollari, un dettaglio che a un cto serio interessa più di mille paper.
L’ironia? chi ancora crede che basti una chain-of-thought ben scritta per gestire un processo di banking dovrebbe forse tornare a studiare. galileo ci ricorda che l’intelligenza generativa non è magia, è infrastruttura da costruire, testare e misurare con logica da ingegnere e cinismo da CEO.
Leaders Board: https://huggingface.co/spaces/galileo-ai/agent-leaderboard
Blog: https://huggingface.co/spaces/galileo-ai/agent-leaderboard