
Quando parliamo di autoencoder, non stiamo parlando di una moda passeggera nel machine learning, ma di uno dei pilastri più eleganti e sottili della rappresentazione dei dati. Immagina di avere un oceano di numeri, immagini o segnali, e di riuscire a comprimerli in poche coordinate senza perdere l’essenza. Questa non è fantascienza, è matematica applicata e ingegneria neurale. Autoencoder funziona codificando i dati in uno spazio latente più piccolo tramite una rete neurale, per poi ricostruirli. Il risultato? Una rete che capisce i dati meglio di chiunque li abbia mai guardati senza strumenti di compressione.
L’anatomia di un autoencoder è semplice ma potente. L’encoder riduce l’input in uno spazio latente z=fθ(x)z = f_\theta(x)z=fθ(x), mentre il decoder tenta di ricostruire l’input x^=gϕ(z)\hat{x} = g_\phi(z)x^=gϕ(z). La funzione di perdita misura quanto x^\hat{x}x^ si discosta da xxx, tipicamente una mean squared error. Qui sta il trucco: la rete deve imparare a rappresentare il mondo in pochi numeri. Troppo piccolo lo spazio latente e perdi informazioni critiche; troppo grande e il modello impara la funzione identità, diventando un inutile specchio dei dati originali. Questo equilibrio è dove risiede l’arte e la scienza.
Matematicamente, l’obiettivo di un autoencoder è:
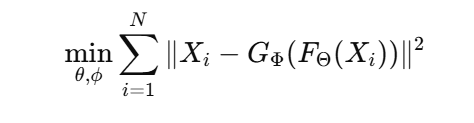
Se ti fermassi qui, sembrerebbe un esercizio accademico. Invece, è un laboratorio di intuizione: ogni numero nello spazio latente è una specie di “concetto condensato” del dataset. Immaginiamo volti umani: un autoencoder può rappresentare occhi, bocca e forma del viso come coordinate astratte. Interpolando tra punti nello spazio latente, ottieni volti nuovi, coerenti e realistici, come se la rete avesse sviluppato un senso estetico proprio.
La scelta dell’architettura è cruciale. ReLU, sigmoid o leaky ReLU cambiano il tipo di pattern che la rete può catturare. Profondità maggiore significa feature più complesse, simili a quelle dei CNN pre-addestrati. Skip connection e batch normalization aiutano a stabilizzare l’allenamento e a prevenire gradient vanishing. In pratica, progettare un autoencoder è come costruire un’astronave: ogni componente influenza le prestazioni e la capacità di esplorare mondi complessi senza schiantarsi.
Le applicazioni sono vaste. Riduzione dimensionale alternativa alla PCA, pulizia dei dati tramite denoising, feature learning per classificazione e clustering. Il denoising è particolarmente interessante: addestrando la rete su dati corrotti e chiedendo di ricostruire l’originale, ottieni un modello capace di rimuovere rumore strutturale e preservare informazioni critiche. In ambito industriale, questo si traduce in monitoraggio predittivo o miglioramento della qualità dei dati in sistemi complessi.
Varianti come i variational autoencoders (VAE) portano l’idea un passo oltre. Invece di mappare un input in un punto deterministico, lo mappano come distribuzione nello spazio latente. Questo permette generazione di dati plausibili e controllabili, aprendo le porte a modelli generativi sofisticati, dai volti sintetici alla musica. In pratica, il VAE trasforma la compressione in creatività.
Un dettaglio affascinante è l’aspetto probabilistico. Nello spazio latente, certe dimensioni possono rappresentare caratteristiche interpretabili, mentre altre codificano variazioni sottili. Esplorare questo spazio equivale a giocare con una tavolozza di concetti astratti: muoversi in una direzione modifica la lunghezza degli occhi, in un’altra la luminosità della pelle. Il tutto senza alcuna supervisione, solo la logica interna della rete.
Autoencoder e business sono più collegati di quanto sembri. In grandi dataset, come log aziendali, transazioni finanziarie o dati di sensori IoT, ridurre dimensionalità significa poter fare analisi predittive più rapide e precise. Feature latenti ben progettate diventano input per algoritmi di classificazione o clustering, aumentando l’efficienza dei processi decisionali. È come avere un filtro intelligente che seleziona solo ciò che conta davvero.
Un’osservazione provocatoria: molti parlano di intelligenza artificiale generativa senza capire che gli autoencoder ne sono uno dei mattoni fondanti. Mentre i modelli più pubblicizzati catturano l’immaginazione con output spettacolari, gli autoencoder lavorano dietro le quinte, strutturando lo spazio dei dati e rendendo possibili applicazioni creative e industriali. Ignorarli significa costruire castelli in aria senza fondamenta solide.
Dal punto di vista della ricerca, il campo continua a evolversi. Sparse autoencoder, contractive autoencoder, denoising autoencoder: ogni variante aggiunge una sfumatura al concetto originale. Alcune enfatizzano la robustezza, altre la generatività, altre ancora l’interpretabilità. Comprendere queste differenze è essenziale per chi vuole passare dalla curiosità accademica a implementazioni reali capaci di generare valore.
Curiosità: esperimenti con autoencoder su dati biologici hanno rivelato cluster nascosti in espressione genica, mostrando che queste reti possono rivelare pattern che sfuggono a metodi tradizionali. In un certo senso, un autoencoder è come un esploratore silenzioso, che cammina tra montagne di dati e scopre valli segrete che nessun occhio umano potrebbe notare.
Implementare un autoencoder oggi significa fare scelte tecniche precise: architettura, funzione di attivazione, dimensione dello spazio latente, funzione di perdita, ottimizzatore. Ogni scelta ha conseguenze concrete sulla qualità della rappresentazione e sulla capacità di generalizzazione. Progettare male significa addestrare una rete che impara solo la funzione identità. Progettare bene significa creare uno strumento che capisce, sintetizza e persino crea.
Nell’era dei dati, capire gli autoencoder equivale a capire come comprimere il mondo senza perderne l’essenza. È un approccio alla realtà che combina matematica, ingegneria e un tocco di poesia digitale. Guardare un dataset dopo averlo passato attraverso un autoencoder è come vedere la stessa scena filtrata da un occhio più acuto: dettagli invisibili emergono, rumore irrilevante sparisce, la struttura interna diventa chiara.
Per chi lavora con dati complessi, ignorare gli autoencoder significa ignorare uno strumento fondamentale per riduzione dimensionale, feature learning e denoising. Per chi ama la tecnologia, rappresentano una sfida concettuale affascinante: come insegnare a una macchina a rappresentare la realtà in uno spazio più piccolo senza tradirla? Per chi osserva con ironia, sono l’ennesima conferma che la semplicità matematica può produrre risultati sorprendenti, quasi magici.
Infine, l’impatto pratico non è solo teorico: riduzione dei tempi di calcolo, miglioramento della qualità dei dati, capacità predittive potenziate. Nel mondo reale, queste reti diventano strumenti competitivi, capaci di fare la differenza tra analisi superficiali e insight strategici profondi.
Di seguito An Introduction to Autoencoders
Umberto Michelucci
umberto.michelucci@toelt.ai
January 12, 2022