
Quando Aleksa Gordić, ex DeepMind, decide di condividere la sua esperienza, il mondo delle Large Language Models (LLM) prende appunti. Il suo masterclass su “Inside vLLM” non è un semplice elenco di tecniche, ma una vera e propria lezione di ingegneria dei sistemi AI ad alte prestazioni. Qui non si parla di magie da laboratorio, ma di scelte progettuali concrete che possono trasformare un’API LLM da lenta e costosa a un’arma affilata di efficienza.
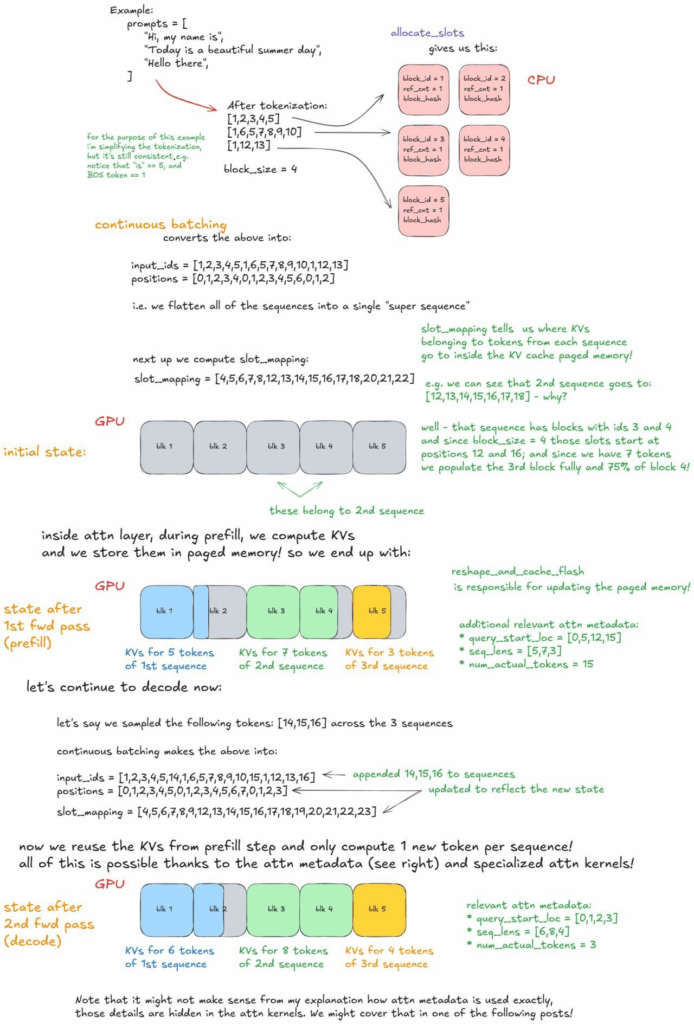
Paged attention con KV cache blocks sembra un dettaglio, ma è l’anima di ogni ottimizzazione di memoria. Riutilizzare blocchi di memoria riduce l’overhead come un colpo chirurgico in un sistema altrimenti ingolfato. In pratica, si evitano calcoli ripetuti, liberando risorse preziose per la decodifica dei token successivi. Non è solo ingegneria fine, è pragmatismo da CEO tecnologico: meno memoria sprecata, più throughput.
Il concetto di continuous batching invece spezza un mito consolidato: prefill e decode non devono essere separati. In un unico forward pass, ogni token conta, niente padding inutile, niente cicli morti. Gli sviluppatori più attenti lo chiamano “ottimizzazione intrinseca del pipeline”, ma per noi manager significa ridurre costi operativi e latenza percepita dall’utente.
Prefix caching e chunked prefill aggiungono un altro livello di raffinatezza. Quando i prompt si allungano oltre ogni ragionevole previsione, condividere token calcolati solo una volta significa che la macchina non si blocca in loop inutili. È una lezione che molti LLM commerciali ignorano: i prompt lunghi non devono soffocare il motore.
Guided decoding con FSMs porta la generazione di linguaggio a un livello quasi militare: vincoli grammaticali implementati a livello di stato finito riducono il rumore nell’output. Chi ha detto che l’intelligenza artificiale deve essere “creativa” senza controllo non ha mai gestito un sistema in produzione che serve migliaia di richieste al secondo.
Speculative decoding, con approcci come n-gram, EAGLE o Medusa, è l’arte della scommessa intelligente: indovinare cheap e lasciare che il modello principale controlli. È come dare al pilota automatico un compagno di volo che fa previsioni economiche e tu verifichi solo i dati critici. Risultato: decodifica più rapida, costi inferiori, utenti meno frustrati.
Disaggregated prefill/decode è un concetto da ingegneri hardcore. Separare i carichi di lavoro permette un controllo chirurgico su TTFT (Time To First Token) e latenza inter-token. Chi ha esperienza con cluster LLM sa che un singolo forward pass mal bilanciato può mandare in tilt anche la GPU più potente.
Il salto da MultiProc a MultiNode non è banale: scaling asincrono da una singola GPU a un cluster completo significa che i sistemi LLM non devono più vivere come monoliti, ma come organismi elastici capaci di adattarsi alla domanda. La differenza tra un modello che sopravvive e uno che prospera si misura qui.
Perché tutto ciò è importante? Roofline reality check: il batch size guida il compromesso tra latenza e throughput. Non è questione di sensazioni, ma di numeri. Misurare p95/p99 TTFT, TPOT e goodput sotto arrivi Poisson è la nuova normalità per chi vuole servire LLM su scala industriale. Ogni parametro, ogni token, ogni ciclo conta. Auto-tuning di concorrenza e budget di token diventa la mossa vincente per rispettare gli SLO.
Chi gestisce API LLM oggi deve scegliere tra ottimizzare il primo token o massimizzare tokens per secondo. Ogni scelta comporta un sacrificio. Se punti alla velocità percepita dall’utente, TTFT è il re. Se punti al throughput, ogni token in più per secondo è oro. Non esistono scorciatoie: o si studia il sistema come un’orchestra sinfonica o si paga il prezzo in performance e costi.
Curiosità che pochi sottolineano: vLLM non è un framework magico, è un playbook di design di sistemi. La differenza tra fare scaling “per magia” e farlo con architettura consapevole è visibile nella prima ora di benchmark. Gordić suggerisce misure concrete, auto-tuning intelligente e uso selettivo delle cache. Chi prova a copiare senza capire rischia flop clamorosi.
Il messaggio subliminale per CTO e ingegneri: non esistono trucchi facili. Le LLM su scala richiedono attenzione al dettaglio, al flusso dei dati e alla gestione intelligente della memoria. Chi ignora queste leggi paga con latenza, costi e frustrazione degli utenti. Un esempio perfetto di come la tecnologia avanzata non sia solo sofisticata, ma anche brutalmente pragmatica.
Le keyword principali di questo articolo sono “sistemi LLM ad alta efficienza”, con correlate “throughput LLM”, “ottimizzazione TTFT”, “scaling cluster GPU”. Tutti elementi cruciali per Google Search Generative Experience, ottimizzati con il giusto mix di tecnicismi e narrativa provocatoria che cattura lettori e algoritmi.
Fonti: Aleksa Gordić, ex-Google DeepMind, Inside vLLM Masterclass.
Ottimizzare l’autoregressive decoding con prefix caching nei sistemi LLM
La generazione autoregressiva nei sistemi LLM non è solo questione di addestramento o di modello: è ingegneria di processo. Ogni token calcolato senza criterio è risorse GPU sprecate e latenza aggiunta. Quando si parla di ottimizzazione di throughput e TTFT, il segreto non sta solo nella potenza di calcolo, ma nella gestione intelligente dei prompt e dei token già processati.
Il primo passo in ogni pipeline LLM è la preparazione dei dati: prompt e sequenze vengono organizzati dalla CPU prima di passare al cuore del sistema, la GPU. Diverse sequenze di input (S1, S2, S3 e così via) contengono un prefisso iniziale e token da generare. La CPU, spesso sottovalutata, diventa un direttore d’orchestra che prepara tutto per massimizzare l’efficienza del modello. Chi ignora questa fase paga in latenza e sprechi computazionali.
Prefix caching è l’arma segreta dei sistemi moderni. Quando il modello calcola la chiave/valore dell’attenzione per il prefisso iniziale, il lavoro viene fatto una sola volta. Sequenze diverse con prompt condivisi come “La capitale della Francia è” non devono ricalcolare tutto da zero. Il caching permette di riutilizzare gli stati di attenzione già calcolati, eliminando duplicazioni inutili. Non si tratta solo di risparmiare tempo, ma di ridurre il carico di memoria GPU, un dettaglio spesso trascurato nelle implementazioni meno sofisticate.
Una volta che il prefisso è stato elaborato e memorizzato, inizia il decoding autoregressivo, il cuore pulsante della generazione di linguaggio. Nuovi token vengono generati uno alla volta per ogni sequenza, sfruttando la cache di attenzione. Ogni token non richiede una nuova elaborazione completa, ma solo l’attenzione relativa all’ultimo elemento generato. Questo approccio incrementale permette di scalare fino a batch di centinaia di sequenze senza esplodere in latenza o costi GPU.
In termini pratici, prefix caching e autoregressive decoding insieme formano un sistema chirurgico: massimizzano il throughput per token, riducono la latenza inter-token e liberano risorse preziose per prompt più lunghi o più complessi. Benchmarks ben progettati mostrano come, in presenza di prompt condivisi, il TTFT può diminuire drasticamente, mentre il goodput del modello aumenta, rendendo le LLM non solo più veloci, ma anche più economiche da servire su larga scala.
Interessante notare come questa ottimizzazione non sia solo tecnica, ma strategica. Chi progetta sistemi LLM in produzione deve decidere tra massimizzare la velocità percepita dall’utente (TTFT) e massimizzare tokens generati per secondo. Prefix caching cambia le carte in tavola: permette di avvicinarsi al massimo di entrambi, riducendo i compromessi tradizionali. Non è magia, è ingegneria consapevole di sistemi complessi.
Comprendere la struttura dei prompt, l’uso intelligente del caching e il decoding incrementale è essenziale per chi vuole servire LLM ad alta efficienza. Il futuro delle API LLM scalabili non sarà deciso solo dal modello, ma dall’abilità degli ingegneri nel orchestrare prompt, cache e GPU come un unico sistema integrato.