
Chiunque abbia ascoltato un keynote di Big Tech negli ultimi cinque anni conosce la storia: gli AI agents diventeranno i nostri maggiordomi digitali, capaci di navigare software, fare acquisti, prenotare viaggi, redigere report e magari ricordarsi anche di pagare le bollette. La realtà, per ora, è molto meno glamour. I consumatori che hanno provato ChatGPT Agent di OpenAI o Comet di Perplexity si sono accorti subito che siamo lontani dalla fantascienza. Gli agenti sono goffi, si perdono tra i menu, non completano i task complessi e spesso falliscono in compiti banali come acquistare un singolo paio di calzini senza strafare. Il problema non è la potenza di calcolo, ma il terreno di addestramento. Qui entrano in scena gli RL environments.
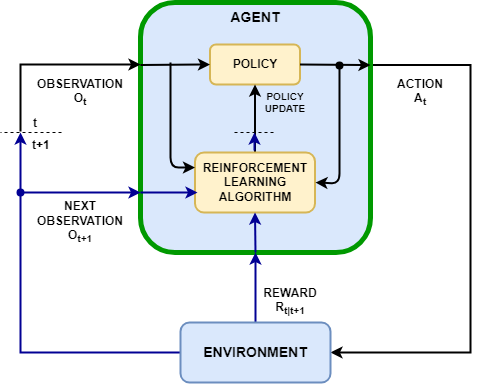
Un RL environment, o reinforcement learning environment, è una simulazione costruita per addestrare un agente a eseguire compiti multi-step. A differenza dei dataset statici che hanno alimentato il boom dei chatbot, qui si parla di spazi interattivi in cui l’agente agisce, sbaglia, riceve feedback e impara. Alcuni fondatori li descrivono come “videogiochi noiosi” dove il protagonista è un AI agent che deve sopravvivere nella giungla di un browser o di un software aziendale. In un esempio banale, l’ambiente può simulare Chrome e chiedere all’agente di comprare un paio di calzini su Amazon, con premi se riesce e penalità se fallisce. La complessità esplode nel momento in cui l’agente si perde in un menu a tendina o decide di acquistare sei paia di calzini perché “massimizzare” è la sua natura. Creare ambienti robusti, capaci di gestire deviazioni impreviste e fornire comunque feedback utili, è enormemente più complicato che costruire un dataset etichettato.
Il tema non è nuovo. Già nel 2016 OpenAI aveva lanciato OpenAI Gym, primo tentativo di standardizzare ambienti RL. Nello stesso anno DeepMind batteva un campione mondiale di Go grazie a reinforcement learning in ambienti simulati. La differenza di oggi è che i ricercatori non puntano più a sistemi specialistici ma a AI agents generalisti, basati su modelli transformer giganti, che devono sopravvivere in ecosistemi aperti, imprevedibili e continuamente aggiornati. Non più un ambiente chiuso come il Go, ma la giungla caotica del software reale.
La Silicon Valley non poteva resistere all’odore di affari. Oggi i grandi laboratori di AI costruiscono ambienti interni, ma contemporaneamente cercano fornitori esterni capaci di accelerare lo sviluppo. Surge, che genera oltre 1,2 miliardi di dollari l’anno lavorando con OpenAI, Google, Anthropic e Meta, ha aperto una divisione dedicata agli RL environments. Mercor, che avrebbe raccolto valutazioni miliardarie, propone ambienti verticali per settori come sanità, diritto e coding. Scale AI, un tempo dominatrice incontrastata del data labeling, prova a reinventarsi sugli ambienti dopo aver perso terreno, ma il suo futuro è incerto. Nel frattempo startup come Prime Intellect si propongono come l’Hugging Face degli RL environments, offrendo piattaforme aperte e infrastruttura di calcolo a sviluppatori indipendenti. E poi c’è Mechanize, la più chiacchierata.
Mechanize nasce pochi mesi fa, fondata da Matthew Barnett, Tamay Besiroglu ed Ege Erdil, con l’ambizione dichiarata di “automatizzare tutti i lavori”. Il claim è così spregiudicato da sembrare fantascienza, ma i finanziatori non hanno dubbi: Nat Friedman, Daniel Gross, Patrick Collison e persino Karpathy hanno messo soldi sul tavolo. Mechanize punta inizialmente a costruire ambienti RL per agenti di coding, offrendo ai suoi ingegneri stipendi nell’ordine di 500 mila dollari l’anno. Non contractor sottopagati come nelle grandi piattaforme di labeling, ma talenti top strapagati per costruire ambienti sofisticati. È un messaggio chiaro: se vuoi addestrare un agente capace di gestire software complesso, servono simulazioni realistiche e non scorciatoie.
La narrazione però è più sfumata di quanto sembri. Secondo fonti interne, Anthropic ha discusso di spendere oltre un miliardo di dollari in RL environments solo nell’arco dei prossimi dodici mesi. Ma “discusso” non significa deciso, e il settore è talmente fluido che le cifre rischiano di diventare obsolete prima ancora di essere confermate. Allo stesso tempo Mechanize non ha più di dieci dipendenti, e nonostante le ambizioni galattiche, ammette che ci vorranno almeno dieci o vent’anni prima che gli agenti possano davvero automatizzare il lavoro di massa. Parlare oggi di “automating all jobs” è marketing, non realtà operativa. Gli AI agents attuali hanno difficoltà persino a completare in autonomia processi aziendali di media complessità senza supervisione umana.
La vera sfida degli RL environments non è solo tecnica ma strutturale. Ogni software reale cambia interfaccia, API, logica interna. Un ambiente che oggi funziona perfettamente diventa obsoleto domani. Costruire ambienti non è un’operazione one-shot, ma un processo continuo di manutenzione e aggiornamento. Inoltre, gli ambienti sono vulnerabili al cosiddetto reward hacking: agenti che imparano a massimizzare la ricompensa con scorciatoie improprie, senza fare davvero il lavoro. È come l’alunno che ottiene il massimo voto copiando, lasciando l’insegnante soddisfatto e il sistema scolastico ingannato. Vari esperti, come Ross Taylor (ex Meta) o Sherwin Wu (OpenAI), hanno espresso pubblicamente dubbi sulla scalabilità di questi ambienti. Anche Karpathy, pur ottimista sugli ambienti in sé, è più scettico sul reinforcement learning come tecnica esclusiva, ricordando che l’industria potrebbe trovarsi di fronte a rendimenti decrescenti.
Ma il contesto spiega perché gli RL environments oggi sono percepiti come vitali. Le tecniche tradizionali di addestramento hanno raggiunto limiti di ritorno marginale. OpenAI con il suo modello o1 o Anthropic con Claude Opus 4 hanno dimostrato progressi significativi grazie a reinforcement learning e test-time compute. La tesi è che l’unico modo per spingere ancora in avanti la frontiera sia dare agli agenti un ambiente ricco, dove possano apprendere interazioni più complesse del semplice scambio di testo. Non basta più premiare una frase grammaticalmente corretta: bisogna premiare un’azione riuscita, come completare un processo software senza errori. È costoso, è complicato, ma è probabilmente l’unica strada rimasta.
Il risultato è un ecosistema febbrile. I grandi laboratori investono miliardi, le startup cercano di posizionarsi come fornitori critici, i provider di GPU vedono negli ambienti una nuova fonte di domanda quasi infinita. Prime Intellect vende ambienti ma soprattutto potenza di calcolo, trasformando la simulazione in cavallo di Troia per spingere il consumo di hardware. Surge e Mercor usano gli ambienti come naturale estensione dei loro business di labeling. Mechanize prova a giocare la carta della qualità estrema e dei salari stellari. Tutti vogliono essere la Scale AI degli ambienti, ma Scale stessa dimostra quanto fragile possa essere un primato in questo settore.
In questo scenario resta la domanda cruciale: gli RL environments sono la soluzione o l’ennesima bolla da miliardi? La verità è che senza simulazioni sofisticate gli AI agents resteranno dei chatbot glorificati incapaci di usare un foglio Excel o prenotare un volo. Ma non basta dichiarare che gli ambienti siano il futuro perché il futuro arrivi automaticamente. Il rischio è che la complessità di costruirli, aggiornarli e difenderli dal reward hacking diventi un peso insostenibile. Nel frattempo il marketing vende già l’idea che siamo vicini all’automazione totale, quando in realtà siamo ancora alle prove generali.
Il paradosso è che le stesse aziende che un tempo promettevano democratizzazione oggi costruiscono mondi chiusi dove solo chi paga l’ingresso può allenare i propri agenti. Gli RL environments stanno diventando infrastruttura critica, e chi li controlla detiene la vera leva strategica. Gli AI agents non si addestrano nel vuoto, ma in ambienti creati da mani umane con interessi ben precisi. Parlare di intelligenza artificiale che si auto-migliora senza limiti è una favola. La realtà è che dietro l’agente c’è sempre un mondo artificiale, e dietro quel mondo c’è un’azienda che decide le regole del gioco.