

Il mondo dei modelli GPT open weight sta rapidamente diventando un terreno minato per chi pensa che “open” significhi prevedibile. Recenti osservazioni hanno mostrato come le prestazioni di questi modelli varino in modo significativo a seconda di chi li ospita. Azure e AWS, spesso percepiti come standard di riferimento affidabili, si collocano tra i peggiori nella scala delle performance, e questo non è un dettaglio marginale. Per chi considera il tuning dei prompt la leva principale per migliorare i risultati, la sorpresa sarà dolorosa: l’impatto dell’hosting supera di gran lunga quello della maggior parte delle ottimizzazioni sui prompt.
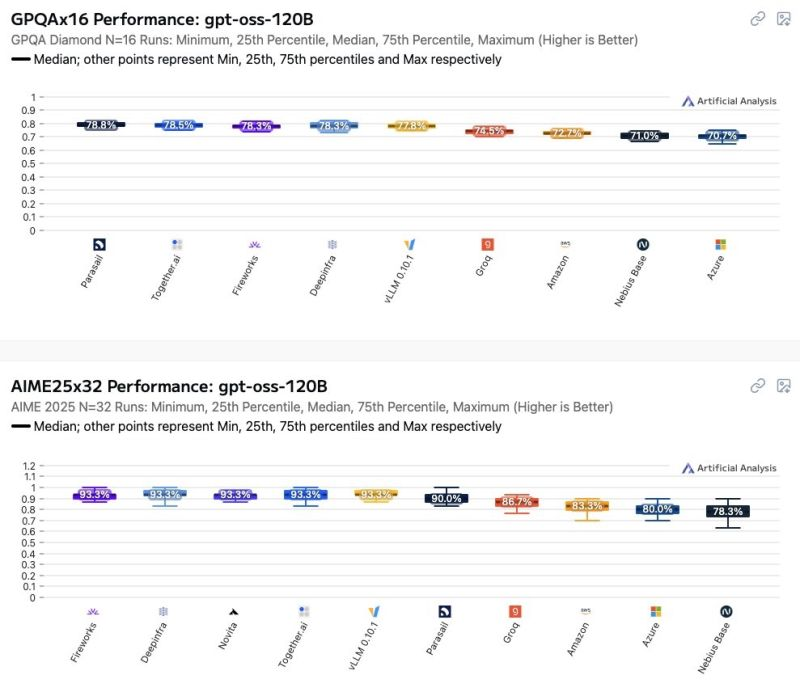
Ci sono aziende che spendono mesi a perfezionare il wording dei prompt, come se fossero poeti della logica, ignorando che l’infrastruttura sottostante potrebbe vanificare ogni sforzo. La verità è che differenze minime nella GPU, nelle versioni dei driver, nei layer di containerizzazione o nella latenza di rete possono determinare scostamenti drammatici in termini di accuratezza e velocità di risposta. Se stai utilizzando un modello per supportare decisioni critiche, dal trading algoritmico alla generazione automatica di codice, queste differenze diventano rischi reali, non astratti.