Se pensavate che l’epoca delle tigri asiatiche fosse finita con l’industria manifatturiera, DeepSeek è qui per ricordarvi che oggi il vero impero si costruisce su tensor, modelli linguistici e centri di calcolo raffreddati a liquido. Il nuovo modello R1-0528, evoluzione muscolare e cerebrale del già notevole R1 lanciato a gennaio, è la risposta cinese ai soliti noti: OpenAI, Google, Meta, e per non farci mancare nulla, anche Anthropic.
Ma la vera notizia non è che DeepSeek abbia fatto l’upgrade. È come lo ha fatto, quanto ha osato, e soprattutto perché oggi dovremmo tutti smettere di ridere quando sentiamo “AI cinese”.
Intanto, due parole su hallucinations: no, non parliamo del viaggio lisergico di un algoritmo impazzito, ma dell’incapacità cronica dei LLM (Large Language Models) di distinguere verità da delirio plausibile. DeepSeek sostiene di aver ridotto questi deliri del 50%. Non “un po’ meglio”, ma metà del casino. Questo, nella scala degli upgrade dell’AI, è tipo passare da Chernobyl a una centrale con l’ISO 9001: serve rispetto.
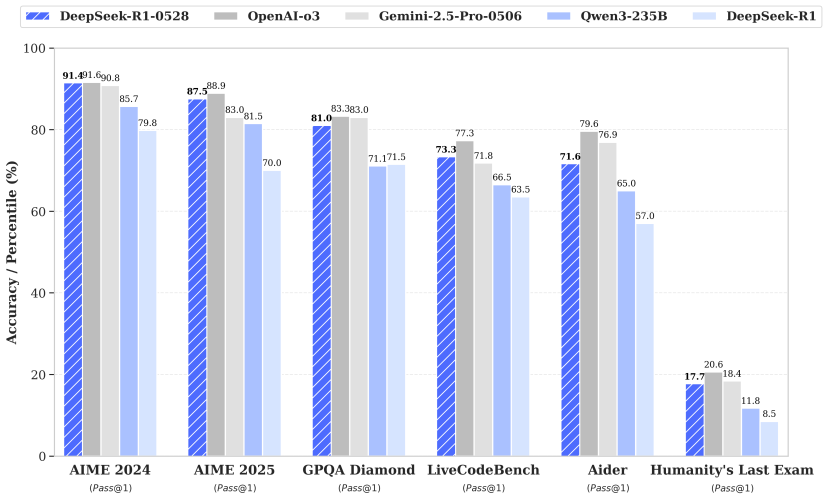
Il salto qualitativo non è magia né poesia (anche se ora sa scrivere anche quelle, pare). È il frutto di uno dei passaggi più sottovalutati del ciclo di vita di un LLM: il post-training. Qui DeepSeek ha deciso di usare la carta che in molti conservano per la IPO: potenza computazionale extra. Nessuna scorciatoia, nessuna promessa gonfiata. Solo GPU e ottimizzazioni chirurgiche. Per chi vive nel settore, significa una cosa: il modello è stato limato come un diamante sintetico costruito per vincere benchmark, non per raccontare barzellette.
Sì, perché i benchmark li ha vinti, e non quelli sfigati. R1-0528 ha surclassato Qwen3 di Alibaba – che solo un mese fa faceva il gallo nel pollaio open-source – e ha raggiunto gli stessi livelli di O3 di OpenAI e Gemini 2.5-Pro di Google. Per gli amanti del sangue, è come se una start-up di Shanghai avesse fatto slalom tra i cadaveri di Meta, Anthropic e xAI, per arrivare seconda sul podio mondiale. Il primo posto? Solo il semi-mitologico o4-mini (High) di OpenAI. Ma ormai non è più una distanza incolmabile, è una gara di millisecondi e parametri.
Chi pensa che siano solo numeri da nerd, si sbaglia. Perché il mercato si è accorto. Il giorno dopo il lancio, Tencent, Baidu e ByteDance – i tre tenori dell’AI cinese – hanno annunciato l’integrazione immediata del modello nei loro servizi cloud. Tradotto: DeepSeek non è più solo uno sviluppatore, è un fornitore strategico per la nuova economia algoritmica.
E mentre l’Occidente balbetta tra modelli chiusi, licenze blindate e pricing opaco, DeepSeek gioca la carta dell’open-source intelligente. Ha distillato (sì, distillato, proprio come si fa con gli alcolici pregiati) la conoscenza di R1-0528 in una versione mini, l’8B, che – tenetevi forte – raggiunge le performance di Qwen3-235B. In numeri, questo vuol dire stesso cervello con un trentesimo del peso. Se non vi si accende una lampadina sul futuro dei modelli edge e della sostenibilità AI, è il momento di preoccuparsi.
Perché è proprio qui il punto: l’efficienza cognitiva sta diventando la nuova valuta. Non bastano più modelli grandi, servono modelli intelligenti, addestrati meglio, più leggeri, ma ancora capaci di ragionare. DeepSeek sembra aver capito il trend prima degli altri. E non è un caso: mentre le big americane annaspano in aggiornamenti incrementali e modelli Frankenstein, in Cina l’approccio è verticale, sistemico, in stile guerra-lampo.
Curiosità: il team di Artificial Analysis, una delle poche entità con abbastanza sangue freddo da comparare seriamente modelli chiusi e open, ha dichiarato che DeepSeek è ormai “il laboratorio AI numero due al mondo”. Forse non hanno ancora messo la bandiera sul tetto, ma il messaggio è chiaro: la Silicon Valley non è più sola.
Il panorama dell’intelligenza artificiale è diventato una partita a scacchi quantistica, e la Cina si è stancata di giocare in difesa. R1-0528 è la prima mossa di attacco vera. Non un esperimento, ma un prodotto competitivo. E se è vero che il modello precedente ha fatto scalpore per l’efficienza nei costi, oggi il nuovo DeepSeek è anche un motore di prestigio geopolitico. Perché quando l’AI smette di allucinare e inizia a ragionare, allora diventa pericolosa. In senso buono. O forse no.
Nel frattempo, l’industria occidentale fa ancora finta che il vantaggio sia irriducibile. Ma DeepSeek non cerca di imitare ChatGPT. Cerca di superarlo. E potrebbe riuscirci. Anche perché, diciamocelo, la Silicon Valley non sa più cosa significa fame. A Shanghai, invece, lo sanno ancora benissimo.
E ora? Ora vedremo quanto vale davvero un modello che riesce a scrivere narrativa umana, risolvere problemi matematici, programmare con precisione chirurgica e non confondere Gengis Khan con il Dalai Lama. Quando l’AI smette di inventare e inizia a capire, il futuro cambia linguaggio. E DeepSeek ha appena deciso che, forse, quel linguaggio sarà scritto in caratteri cinesi.