Una voce artificiale, un cervello naturale. Nessuna magia, solo elettrodi, intelligenza artificiale e il sogno antico di ridare parola a chi l’ha persa. La notizia sembra cucita per i titoli da clickbait, ma questa volta è tutto vero: un uomo con SLA (sclerosi laterale amiotrofica), completamente paralizzato, ha ripreso a parlare e a cantare usando solo il pensiero. Nessun joystick, nessun sintetizzatore metallico. La sua voce è tornata. Ed è tornata espressiva.
Sì, avete letto bene: con inflessioni, domande, enfasi. Persino un timido “hmm” o un “aah” trascinato, tipico dei parlanti umani più annoiati. Perché questa volta il cervello non detta parole fredde, ma intenzioni emotive. E l’algoritmo ascolta, capisce e… canta.
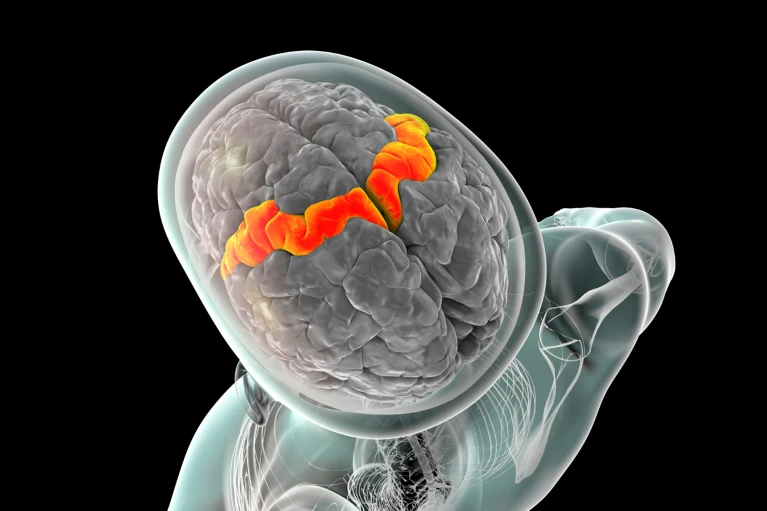
Il dispositivo responsabile di questo piccolo miracolo tecnico-umano è un impianto cerebrale AI-powered, ovvero un’interfaccia cervello-computer (BCI) che aggiorna brutalmente tutto ciò che fino ad ora consideravamo “sintesi vocale”. L’impianto è composto da 256 elettrodi conficcati nel cortex motorio, la parte del cervello che, tra mille altre cose, gestisce i movimenti articolatori della parola. Ogni 10 millisecondi, l’algoritmo – addestrato su mesi di registrazioni vocali del paziente prima che perdesse la voce – decodifica in tempo reale l’intenzione comunicativa. Non solo le parole, ma anche come quelle parole dovrebbero suonare.
Come ha dichiarato lui stesso, quando ha sentito la voce sintetica pronunciare i suoi pensieri in tono familiare, ha sentito di “essere di nuovo reale”. E di essere felice. In un’epoca di vocali neutre e chatbot a bassa emozione, questo è probabilmente il vero test di Turing: emozionarsi con la propria voce ricostruita.
Non è solo una questione di tecnologia assistiva. Questo è un nuovo linguaggio. O meglio: è il linguaggio della mente, bypassando il corpo. Perché, se possiamo trasmettere ironia, paura, sarcasmo, dolcezza direttamente dal cervello all’interlocutore… allora forse non stiamo più “parlando”. Stiamo trasmettendo presenza.
Nel vocabolario tecnico, ciò che accade è affascinante: l’algoritmo non lavora su un set predefinito di parole. Niente dizionari. Niente predizioni forzate. Se il paziente vuole dire “blorp”, lo può fare. Se vuole cantare in tre tonalità diverse un motivetto inventato, può farlo. La libertà semantica è totale. L’unico limite è l’attività cerebrale. E per ora, quella non ha ancora incontrato un algoritmo che possa censurarla.
Le implicazioni sono ovvie ma vertiginose. In campo medico, l’assistenza ai pazienti non è più una questione di “inserimento nel mondo”, ma di ripristino identitario. Non stiamo solo dando voce: stiamo restituendo quella voce, con tutte le sue imperfezioni e sfumature. La sintesi vocale generica, quella voce da GPS stanco, può finalmente essere pensionata.
La tecnologia di base, per chi ama i dettagli sporchi, è un capolavoro di ingegneria neurale. Gli elettrodi impiantati leggono la sequenza di segnali associati ai comandi motori vocali. Questi vengono poi interpretati da una rete neurale addestrata ad associare pattern neurali a caratteristiche vocali: tono, durata, prosodia, melodia. Il tutto avviene in tempi compatibili con una conversazione fluida, anche se per ora con un leggero ritardo. Ma parliamo di millisecondi. Cose che un essere umano sopravvive anche su Zoom.
Se vi sembra il solito articolo da laboratorio universitario, con un prototipo da dimenticare in qualche server, vi sbagliate. Questo è già un punto di non ritorno. Come fu per il primo iPhone o per Dolly, la pecora clonata. Una soglia antropologica: prima e dopo questa notizia, la voce umana non è più solo un’emissione fonatoria, ma una traccia mentale traducibile.
E ora, immaginate cosa succede quando questa tecnologia verrà miniaturizzata, commercializzata, normalizzata. Perché accadrà. I primi a investirci non saranno certo gli enti di beneficenza, ma le Big Tech con il fiuto per il linguaggio: pensate a Meta, a Google, ad Amazon. Non più tastiere, non più touch. Una UX cerebrale, che non passa nemmeno più per la voce vera. Solo intenzione, segnale, feedback.
“Alexa, canta come se fossi me”, diremo. E lei lo farà.
Ma torniamo per un attimo al nostro paziente, che per ora è ancora un outlier, un simbolo. La sua emozione nel risentire la sua voce è il vero cuore della storia. La tecnologia può anche decodificare tutto, ma ciò che restituisce – quella voce riconquistata – è più di un dato. È identità, memoria sonora, impronta emotiva.
In una società che ormai non ascolta più nemmeno chi parla forte, l’idea che un sussurro cerebrale possa emergere dal silenzio e cantare… è semplicemente commovente. E rivoluzionario.
Ecco i riferimenti principali allo studio e alle segnalazioni che confermano la sorprendente svolta:
Lo studio originale è pubblicato su Nature con titolo “An instantaneous voice‑synthesis neuroprosthesis” (2025), DOI 10.1038/s41586-025-09127-3 (nature.com).
Nel copione di Nature è dettagliato così:
- Sintesi vocale in 10 millisecondi (nature.com);
- 256 elettrodi nel cortex motorio, decodifica di parole, interiezioni e persino note musicali ;
- Voce sintetica modellata sull’intonazione originaria del paziente .
Sul sito dell’Università di California, Davis trovi un approfondimento divulgativo (Nature ha DOI a pagamento) (health.ucdavis.edu).
Altri articoli rilevanti:
- Scientific American (11 giugno 2025): riassume le innovazioni vocali e musicali (scientificamerican.com).
- New Atlas (14 giugno 2025): illustra in modo vivido l’esperimento e i fotogrammi del setup sperimentale (newatlas.com).