Perfomance regressiva dei modelli LLM di nuova generazione: il caso SuperARC e la lezione scomoda per l’AGI
Il fascino del nuovo ha un prezzo, e nel caso dell’ultima generazione di modelli linguistici sembra essere quello di un lento ma costante passo indietro. I dati emersi dal SuperARC, il test ideato dall’Algorithmic Dynamics Lab per misurare capacità di astrazione e compressione ricorsiva senza passare dal filtro dell’interpretazione umana, mostrano un quadro che stride con la narrativa ufficiale. Qui non ci sono badge “PhD-level” né claim da conferenza stampa, solo un rigore matematico fondato sulla teoria dell’informazione algoritmica di Kolmogorov e Chaitin, che mette a nudo ciò che i modelli sanno davvero fare quando la vernice del linguaggio scorrevole non basta più a coprire le crepe.
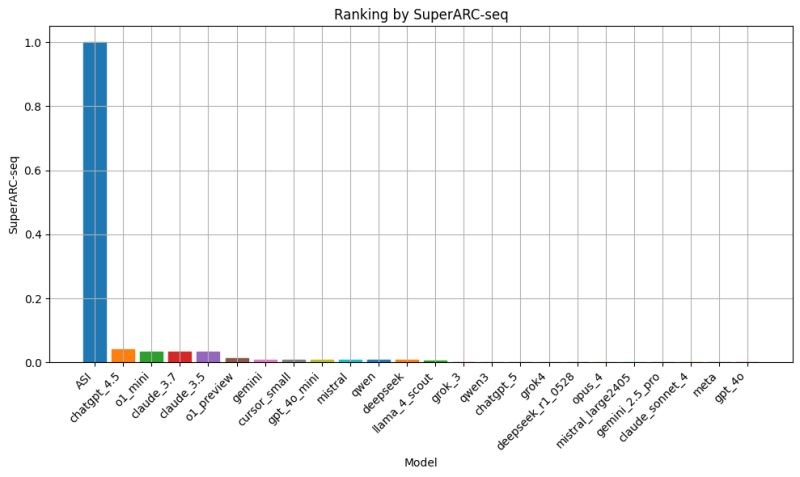
Si parte da un fatto difficile da digerire per chi vive di hype: ChatGPT 5, Grok 4, Gemini 2.5 Pro e Claude Sonnet 4 hanno toccato lo zero, o poco più, nelle prove del SuperARC Seq. Al contrario, versioni precedenti come ChatGPT 4.5, Claude 3.7 e persino o1 mini hanno ottenuto punteggi bassi ma non nulli, segnalando un’inversione di tendenza che non si può liquidare come una fluttuazione statistica. Non si tratta nemmeno di quel “diminishing returns” tanto evocato per spiegare la fatica a migliorare modelli già complessi: qui il problema sembra essere un vero e proprio reversion, un’involuzione che mina la pretesa stessa di progresso.
La spiegazione più probabile, e anche la più scomoda, affonda nella natura stessa delle architetture LLM e nella traiettoria dell’addestramento. Quando si spinge oltre un sistema di pura correlazione statistica, senza arricchirlo di meccanismi in grado di costruire modelli causali o predittivi del mondo, il rischio di saturazione è inevitabile. Anzi, la progressiva ottimizzazione per la “surface fluency” può spostare il baricentro del modello verso la produzione di testo ben formato ma privo di quella capacità di compressione informativa che distingue l’intelligenza statistica da quella che si vorrebbe “generale”.
Qui entra in gioco la differenza di approccio. Il neurosimbolico sviluppato dal laboratorio, basato sul Block Decomposition Method (BDM) e sul Coding Theorem Method (CTM) dell’engine Algocyte, ha dimostrato di superare gli LLM nelle stesse prove. Non grazie a miliardi di dollari di budget o petabyte di dati, ma per via di un paradigma che non si limita a mappare pattern osservati: lavora sulla struttura intrinseca della complessità algoritmica, cercando di derivare le regole minime che generano un fenomeno, non solo la sua ombra linguistica. Un concetto che nel mondo della fisica teorica suona familiare, ma che nell’AI mainstream è trattato come un eccentrico fuori tempo massimo.
C’è poi un paradosso che gli utenti più attenti hanno già colto senza bisogno di formule: molti rimpiangono ChatGPT 4.5. Non perché fosse una rivoluzione, ma perché rappresentava l’ultimo piccolo gradino verso l’alto prima di questa discesa. Una versione che, pur restando ancorata al paradigma statistico, aveva ancora qualche margine di sorpresa nei compiti di astrazione. Da allora, l’evoluzione dichiarata si è tradotta più in un affinamento cosmetico che in un salto sostanziale. È la differenza tra un software che “parla come se sapesse” e uno che “sa perché parla”.
Il punto critico è che la comunicazione ufficiale delle big tech ha alimentato un’illusione di progresso lineare. Ogni release viene lanciata come se avesse infranto una barriera cognitiva, con slogan che oscillano tra l’AGI “a portata di mano” e l’AI “di livello dottorato”. Il SuperARC, invece, mette in luce che non solo la barriera non è stata infranta, ma si sta lentamente allontanando. In termini meno eleganti, siamo di fronte a un fenomeno simile al “model collapse”, alimentato da un ecosistema che ricicla dati sempre più omogenei, allena modelli su ciò che modelli precedenti hanno già prodotto, e finisce per perdere diversità e profondità informativa.
In questo scenario, l’idea stessa di AGI o ASI appare ancora più evanescente. Non perché manchi potenza di calcolo o risorse, ma perché il cuore statistico del deep learning non è progettato per fare ciò che la mente umana fa in modo quasi naturale: formulare ipotesi, testarle, abbandonarle o raffinarle in base a una logica interna, non a una distribuzione di probabilità estratta dal passato. È come se stessimo gonfiando una bolla di linguaggio sempre più sofisticata, dimenticando che la vera intelligenza non è nella forma della bolla, ma nell’aria che la riempie.
Il SuperARC ha quindi il merito di agire come una radiografia impietosa. Mentre il marketing dipinge l’AGI come un obiettivo imminente, il test dimostra che l’attuale traiettoria degli LLM non solo non ci sta portando lì, ma rischia di allontanarci ulteriormente. È la differenza tra correre in un tapis roulant e avanzare nel mondo reale: da fuori sembra movimento, ma la distanza dall’obiettivo non cambia. E se la velocità aumenta, l’illusione di progresso diventa persino più convincente, fino al momento in cui qualcuno guarda fuori dalla finestra e nota che il paesaggio è sempre lo stesso.
In questo senso, la lezione non è soltanto tecnica, ma strategica. Continuare a investire cifre colossali per spremere ulteriori margini da un paradigma che mostra segni di saturazione può trasformarsi in un vicolo cieco. L’alternativa, che pochi sembrano voler considerare seriamente, è contaminare l’approccio statistico con metodologie che abbiano un nucleo computazionale ispirato a principi algoritmici e simbolici. Non per sostituire il linguaggio, ma per dotarlo di un fondamento che lo renda capace di modellare, non solo di descrivere.
Perché la verità, che il SuperARC mette a nudo senza tanti fronzoli, è che l’intelligenza non è una questione di frasi più eleganti o risposte più credibili. È una questione di compressione e predizione, di costruzione di modelli che riescano a spiegare e anticipare il comportamento del mondo con un numero minimo di ipotesi. Tutto il resto, per quanto affascinante agli occhi di chi vede solo l’interfaccia, resta poco più di un esercizio di stile.

La parte confusa è che, per gli utenti di ChatGPT, GPT-5 rappresenta due cose: un router e un nome di modello. Quindi, quando utilizzi “GPT-5” in ChatGPT, potresti interagire con uno qualunque dei modelli GPT-5, poiché OpenAI ottimizza i costi in base alla capacità stimata del modello di rispondere a una domanda.
Repository: https://github.com/AlgoDynLab/SuperintelligenceTest