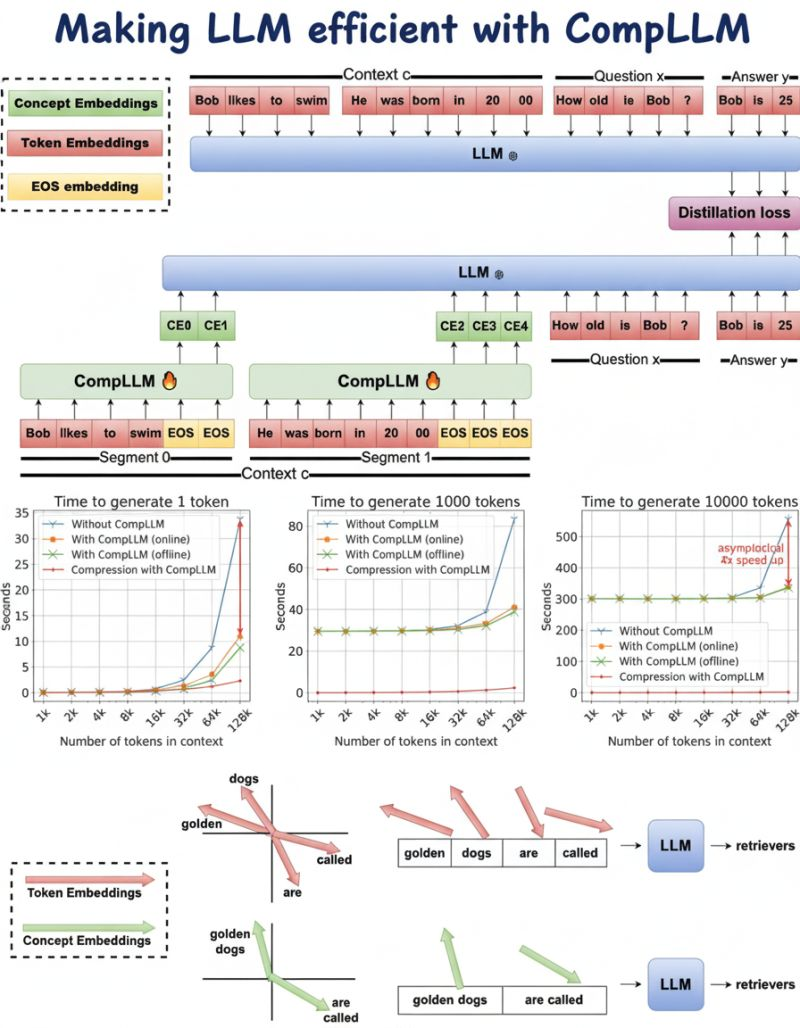
CompLLM è un approccio innovativo per migliorare l’efficienza dei Large Language Models (LLM) nel gestire contesti molto lunghi. I modelli tradizionali faticano con input estesi a causa della complessità quadratica dei meccanismi di self-attention, che aumenta significativamente i costi computazionali e l’uso di memoria. CompLLM affronta queste sfide adottando una strategia di compressione a segmenti.
Invece di processare l’intero contesto come un’unica unità, CompLLM divide l’input in segmenti più piccoli e li comprime indipendentemente. Questa segmentazione trasforma la compressione da complessità quadratica a lineare, riducendo drasticamente latenza e memoria necessaria. Inoltre, i segmenti compressi possono essere riutilizzati in diverse query, aumentando scalabilità ed efficienza.
Nelle applicazioni pratiche, CompLLM ha dimostrato miglioramenti notevoli. Con un tasso di compressione di 2x, ha ottenuto fino a 4 volte riduzione del Time To First Token (TTFT) e il 50% in meno di uso di memoria. È importante notare che le prestazioni sui compiti a lungo contesto sono mantenute o addirittura migliorate, confermando l’efficacia di questo approccio.
Questo progresso è particolarmente vantaggioso in settori che richiedono l’elaborazione di documenti estesi, come legale, sanitario e ricerca. Consentendo agli LLM di gestire contesti più lunghi in modo efficiente, CompLLM apre nuove possibilità per applicazioni reali che necessitano di elaborazione ad alta fedeltà di dati lunghi e non strutturati.
L’adozione di tecniche come CompLLM suggerisce un cambiamento nello sviluppo degli LLM, spostando il focus dal semplice aumento della scala all’ottimizzazione dell’architettura per l’efficienza. Questo paradigma privilegia il fare di più con meno, in linea con la crescente necessità di soluzioni AI sostenibili e cost-effective.
Per chi volesse approfondire, il paper completo è disponibile qui: arxiv.org.