
L’ascesa di Jet-Nemotron è esattamente quel tipo di svolta che fa alzare un sopracciglio a ricercatori e dirigenti AI, mentre bisbigliano “Forse abbiamo sbagliato tutto finora”. NVIDIA sta dimostrando che il numero puro di parametri non è più il santo graal. Un modello da 2 miliardi di parametri che supera giganti come Llama3.2 o Gemma3 è provocatorio, ma ciò che cattura davvero l’attenzione è la metodologia Post Neural Architecture Search, o PostNAS. L’idea non è reinventare la ruota addestrando modelli enormi da zero, ma partire da un Transformer già pre-addestrato e ottimizzare chirurgicamente gli strati di attenzione. Una filosofia sottile che unisce eleganza ingegneristica e pragmatismo operativo.
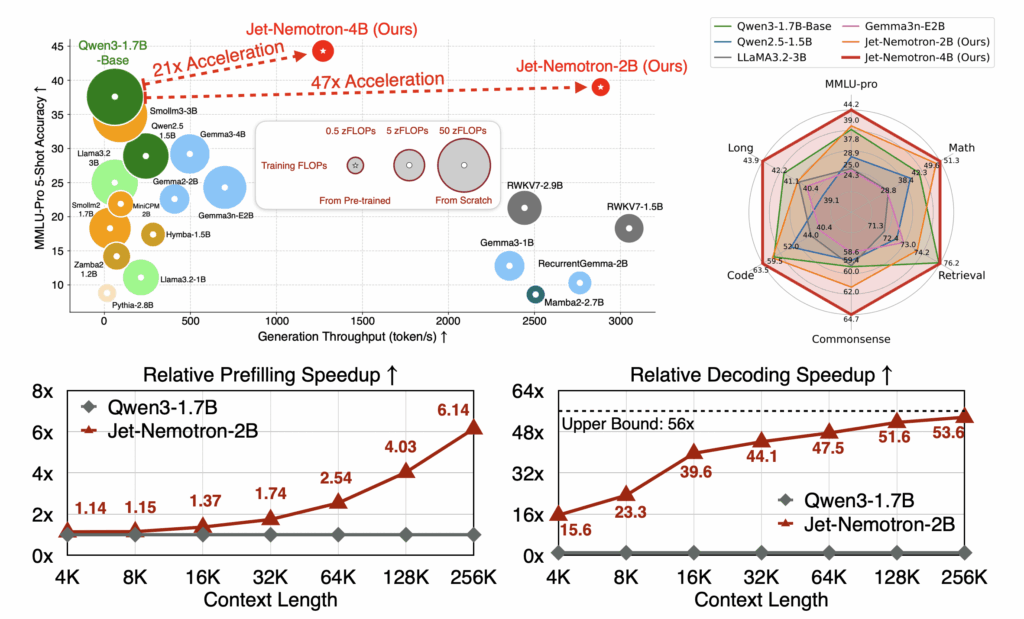
Gli strati full-attention consumano GPU come se non ci fosse un domani. PostNAS non li elimina a caso; individua esattamente dove servono, seleziona i componenti di attenzione più performanti e introduce JetBlock, che si adatta dinamicamente al contesto. È come dare a uno sprinter la capacità di cambiare passo a metà gara senza perdere ritmo. A questo si aggiunge una ricerca ottimizzata per hardware, pensata per spremere ogni watt delle H100. Il risultato? Decodifica 53,6 volte più veloce su contesti da 256K token e prefill 6,1 volte più rapido. Numeri che non sono solo impressionanti, ma dirompenti.
Chi ha esperienza con LLM a lungo contesto sa bene che “gestire conversazioni estese a scala” è il vero banco di prova. La maggior parte dei modelli rallenta drasticamente oltre poche migliaia di token. Jet-Nemotron non solo scala, ma lo fa in modo efficiente, rendendo realistiche applicazioni in customer support, analisi finanziaria o coding assistant senza necessità di un cluster GPU mastodontico. Ragionamento più veloce, footprint più ridotto e gestione del contesto esteso: la triade che ogni azienda sta inseguendo.
Meta e OpenAI hanno puntato sulla forza bruta: più grande, più profondo, più costoso. Funziona se il budget e l’infrastruttura non sono un problema, ma nella realtà dei sistemi di produzione, i costi GPU e i colli di bottiglia di latenza sono gatekeeper implacabili. Gli ibridi efficienti come Jet-Nemotron suggeriscono un paradigma dove l’intelligenza architetturale batte la pura dimensione. Ricorda un po’ come l’hardware specializzato abbia fatto sembrare obsoleti i supercomputer generici.
Curiosità circonda anche JetBlock. NVIDIA consente agli strati di attenzione di auto-regolarsi durante l’inferenza, concetto che fino a pochi anni fa sembrava fantascienza. In produzione, questo significa modelli che mantengono fedeltà al contesto senza bisogno di retraining costante o interventi manuali, un enorme vantaggio operativo. L’eleganza di PostNAS sta nel suo pragmatismo misurato: parti da qualcosa che “sa già” il linguaggio, poi affini per efficienza e scala.
L’impatto strategico va oltre la tecnica. Le aziende non possono più pensare che più parametri equivalgano a migliori risultati. Jet-Nemotron dimostra che l’intelligenza nel design del modello, unita a ottimizzazioni hardware consapevoli, può generare guadagni di performance sproporzionati. Potrebbe cambiare le priorità negli investimenti AI: meno esperimenti da petaflop famelici e più ottimizzazioni chirurgiche su architetture esistenti.
Certo, ci sono avvertenze. I benchmark su H100 sono una cosa; il deployment in ambienti produttivi eterogenei un’altra. I guadagni di efficienza di PostNAS potrebbero non trasferirsi identicamente su GPU diverse o cloud differenti. Ma il concetto è abbastanza potente da non poter essere ignorato. Efficienza, gestione del contesto lungo e attenzione adattiva stanno diventando elementi di prima classe nella corsa all’AI.
In sintesi, sì: architetture ibride efficienti come Jet-Nemotron potrebbero davvero sostituire i Transformers full-attention di Meta e OpenAI in molti scenari produttivi. Non domani, ma la traiettoria è chiara. Le aziende ossessionate dai parametri potrebbero presto capire che l’intelligenza chirurgica nel design dei modelli, unita all’ottimizzazione hardware, è il futuro. Per chi gestisce un cluster GPU in cloud, quel futuro è molto più allettante di un modello mostruoso che consuma elettricità come una piccola nazione.