Il tempismo è una forma d’arte, soprattutto quando il palcoscenico è l’intelligenza artificiale cinese e il pubblico globale è pronto a giudicare con lo stesso cinismo con cui commenta i mercati finanziari. DeepSeek ha deciso di bruciare ancora una volta le tappe lanciando il suo V3.2-Exp proprio alla vigilia della Festa Nazionale cinese, trasformando un semplice esperimento in una dichiarazione geopolitica. Altro che fuochi d’artificio, qui il vero spettacolo pirotecnico è il codice.
DeepSeek V3.2-Exp si presenta come un modello “sperimentale”, ma è un errore pensare che sperimentale significhi marginale. In realtà il nuovo rilascio è il più chiaro indizio della corsa senza fiato di Hangzhou per dimostrare che la Silicon Valley non detiene più il monopolio dell’immaginazione algoritmica. V3.2-Exp introduce il meccanismo di sparse attention, una soluzione tanto tecnica quanto politica, perché riduce i costi di calcolo e rende più accessibile lo sviluppo di agenti intelligenti in un contesto in cui la scarsità di chip avanzati pesa più delle sanzioni diplomatiche. Con una mossa, DeepSeek ha reso i suoi modelli non solo competitivi, ma quasi sovversivi rispetto al monopolio occidentale delle infrastrutture AI.
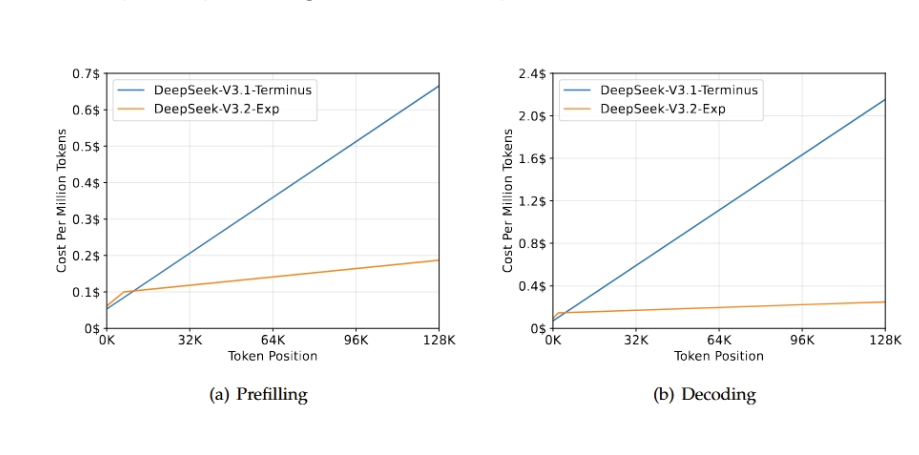
Chi osserva superficialmente potrebbe liquidare questa release come un aggiornamento minore, una sorta di patch strategica in attesa del fantomatico V4. In realtà la logica è molto più sottile: le versioni intermedie di DeepSeek funzionano come test clinici di un farmaco sperimentale, con la differenza che i pazienti siamo noi, gli utenti globali, e la medicina è una nuova architettura di intelligenza artificiale open source. Pubblicare su Hugging Face e ModelScope non è un gesto di apertura innocente, ma un attacco diretto al modello di business di OpenAI e dei colossi americani. Quando una startup cinese riduce del 50% i costi API e mantiene performance “pari” alle versioni precedenti, il messaggio è chiaro: il futuro dell’AI potrebbe costare la metà e arrivare due volte più in fretta.
La narrativa ufficiale parla di maggiore efficienza nell’addestramento e nell’inferenza, ma la vera notizia è l’ossessione con cui la Cina sta inseguendo la prossima generazione di AI agent. DeepSeek dichiara apertamente che il potenziamento delle capacità agentiche dei suoi modelli è solo il primo passo verso “l’era degli agenti”. Una frase che suona quasi come uno slogan pubblicitario, ma che in realtà definisce il terreno della battaglia tecnologica dei prossimi anni. Gli agenti non sono chatbot da salotto, ma software capaci di agire autonomamente, eseguire task complessi, coordinarsi con sistemi esterni e trasformare l’interazione uomo-macchina in un ecosistema quasi post-umano. Il problema tecnico? Le famose context windows limitate, che impediscono oggi di gestire sequenze lunghe di azioni. Il problema politico? Chi controllerà gli agenti controllerà il lavoro intellettuale.
Intelligenza artificiale cinese, sparse attention, modelli open source AI. Queste tre espressioni sono diventate le parole chiave di un racconto che mischia innovazione e strategia industriale. Sparse attention è la nuova bacchetta magica dei ricercatori, capace di eliminare gran parte dello spreco computazionale che affligge i transformer classici. È la differenza tra addestrare un modello con un reattore nucleare e addestrarlo con una batteria portatile, almeno sul piano dei costi. Per l’AI cinese è ossigeno puro, perché significa ridurre la dipendenza da GPU americane e ottimizzare ogni frammento di silicio disponibile. A questo si aggiunge la scelta di rendere open source i risultati, una mossa che non solo democratizza l’accesso, ma crea un circolo vizioso virtuoso: più sviluppatori sperimentano con V3.2-Exp, più dati indiretti tornano a DeepSeek, più la Cina avanza verso la leadership tecnologica.
C’è poi l’aspetto teatrale della competizione interna. In un mercato già affollato da Qwen di Alibaba Cloud, da Baidu con il suo Ernie Bot, e da una miriade di startup con nomi più o meno poetici, DeepSeek ha capito che l’unico modo per restare rilevante è accelerare il ciclo di rilascio. In dieci mesi ha presentato V3, V3.1, V3.1-Terminus, e ora V3.2-Exp. È una strategia che ricorda le corse automobilistiche: non vince chi ha l’auto perfetta, ma chi riesce a fare più pit-stop in meno tempo senza perdere velocità. Il risultato? La comunità di benchmarking internazionale ha posizionato Terminus alla pari con GPT-OSS-120B di OpenAI come miglior modello open source al mondo. La differenza, ironia della sorte, è che Terminus si trova a Hangzhou, non a San Francisco.
Certo, il sospetto resta: che cosa bolle davvero nella pentola di DeepSeek? La risposta implicita arriva dai rumor: V4 arriverà l’anno prossimo, R2 intorno al Capodanno lunare. Ma V3.2-Exp serve a preparare il terreno psicologico. È come se la startup stesse dicendo al mercato “non aspettatevi fuochi d’artificio adesso, ma state pronti a vedere il cielo incendiarsi più avanti”. Nel frattempo però la semina è già iniziata. Sparse attention non è solo un upgrade tecnico, è la promessa che la Cina non solo giocherà la partita, ma imporrà nuove regole.
Dietro ogni modello open source c’è un’altra narrativa meno evidente: quella dei costi. La retorica sulla democratizzazione spesso nasconde una dura verità economica. Ridurre del 50% le spese API significa rendere possibile lo sviluppo di applicazioni che prima erano proibitive. Significa dare a migliaia di startup locali la possibilità di costruire prodotti su DeepSeek anziché su OpenAI o Anthropic. Significa soprattutto creare un ecosistema che non dipende da GPU Nvidia importate a caro prezzo. In altre parole, il V3.2-Exp è un’arma economica prima ancora che tecnologica.
La città di Hangzhou, patria dei cosiddetti “Sei Piccoli Draghi”, sta diventando la nuova capitale dell’intelligenza artificiale cinese. Non è un caso se DeepSeek abbia scelto di posizionarsi qui, nello stesso terreno che ha visto nascere Alibaba e le sue derivazioni. La logica è semplice: concentrare cervelli, capitale e infrastrutture in un unico hub e lasciare che la competizione interna produca innovazione esponenziale. Se la Silicon Valley ha costruito la sua fortuna sull’ossessione californiana per il rischio, Hangzhou sta replicando il modello con una miscela di pragmatismo politico e velocità imprenditoriale. Il risultato è un ecosistema che sfida apertamente l’ordine tecnologico globale.
Chi osserva da fuori potrebbe sorridere pensando che il V3.2-Exp sia solo una curiosità tecnica. Ma la verità è che questi rilasci intermedi sono la forma più sottile di soft power cinese. Ogni volta che un ricercatore europeo scarica il modello su Hugging Face, ogni volta che una startup indiana testa l’API a basso costo, DeepSeek guadagna terreno non solo come player tecnologico, ma come simbolo della possibilità di un’AI alternativa. Non è più una gara di performance pura, ma di influenza. È la vecchia logica della diplomazia trasformata in pipeline di PyTorch.
La corsa all’intelligenza artificiale cinese non è più un esercizio accademico, è la nuova partita per l’egemonia digitale. E il dettaglio ironico è che il pubblico globale applaude convinto di assistere a uno spettacolo tecnico, senza accorgersi che dietro ogni sparse attention si nasconde un’agenda geopolitica. DeepSeek non ha bisogno di dire di voler sfidare OpenAI, lo sta già facendo con i fatti. E mentre aspettiamo V4 o R2 come se fossero blockbuster annunciati, il messaggio è già passato: la Cina non sta correndo per inseguire, ma per sorpassare.