
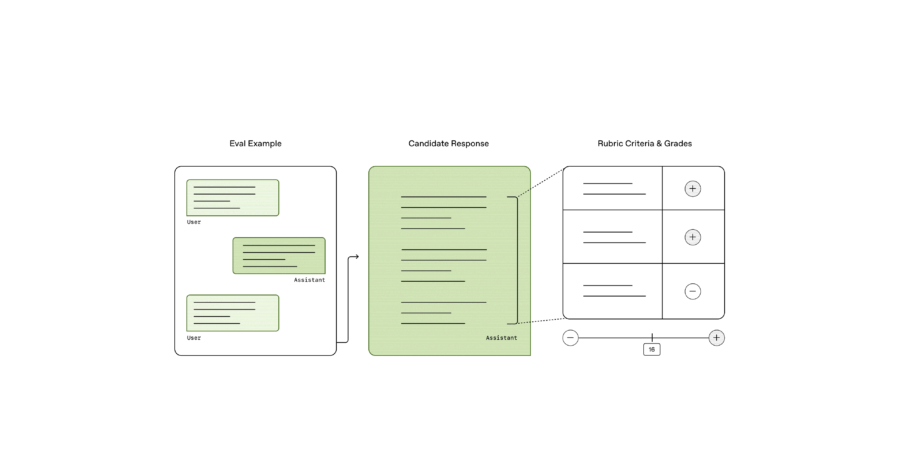
OpenAI ha appena alzato il livello della sfida, portando il mondo dell’intelligenza artificiale medica verso un nuovo orizzonte con il lancio di HealthBench, un benchmark open source progettato per testare le capacità degli LLM (modelli linguistici di grandi dimensioni) nel rispondere a domande mediche. Ma non stiamo parlando di un generico set di dati o di un sistema che si limita a rispondere in modo aleatorio: HealthBench si distingue per un approccio sofisticato e mirato, con criteri medici rigorosi e la capacità di analizzare risposte in ben 49 lingue diverse. Questo non è solo un passo in avanti nel campo dell’AI, è una vera e propria rivoluzione nella valutazione della competenza medica delle AI, che rischia di cambiare per sempre il modo in cui interagiamo con le tecnologie sanitarie.
Ma chi sta davvero vincendo in questa partita? Gli LLM? O siamo solo spettatori di un gioco dove l’umanità si trova a fare da semplice comparsa? La risposta, ovviamente, non è semplice.