Ora che la pantomima dei benchmark “truccati” in stile LMArena ha mostrato quanto sia facile drogare i numeri per far sembrare intelligente anche un tostapane con un fine-tuning, era solo questione di tempo prima che qualcuno dicesse: “Aspetta un attimo, ma cosa stiamo davvero misurando?”
Microsoft ha colto il momento e il discredito generale per piazzare sul tavolo ADeLe, un framework di valutazione che, ironia della sorte, non misura tanto le risposte di un modello quanto il modo in cui dovrebbe pensare per arrivarci. Come dire: invece di guardare il voto in pagella, ci interessiamo al metodo di studio. E se sbaglia, capiamo perché. Finalmente.
ADeLe (Analysis of DEep Learning Evaluation) non è un benchmark nel senso classico. Non ti spara addosso mille domande per poi dirti “GPT-qualcosa ha preso 78%”. No. Qui entriamo in una logica simile a quella scolastica: 18 rubriche, ognuna riferita a capacità cognitive o settori di conoscenza, come se ogni compito da far svolgere a un modello fosse un esame valutato da una commissione interna, non da un quiz automatizzato.
Hai presente quando il prof ti scriveva: “Buona esposizione, ma scarso spirito critico”? (a me sempre…) Ecco. Ora lo dice anche l’AI. O meglio: lo dice su di lei.
Il framework funziona in due fasi: prima valuta il compito in sé, classificandolo in base a quanto impegna le 18 competenze definite. Poi lo sottopone ai modelli e ne registra la performance per costruire un profilo cognitivo dettagliato. In sostanza, ADeLe sa già quanto dovrebbe essere difficile un esercizio e sa anche che tipo di skills servono per svolgerlo. Quando il modello lo affronta, possiamo capire se ha sbagliato perché è un incapace o perché la domanda era una trappola camuffata.
Le 18 rubriche coprono abilità come attenzione, astrazione, metacognizione, ragionamento, conoscenza sociale, formale, scientifica, chiarezza semantica, e persino la “prevalenza” del concetto su Internet.
Sì, perché se la domanda è virale su Reddit, magari il tuo modello la sa solo perché l’ha vista ovunque, non perché ci abbia riflettuto. Tradotto: un plagio mascherato da competenza. Suona familiare?
Dai test su 63 attività, distribuite su 20 benchmark esistenti, emerge qualcosa di clamoroso ma, per chi lavora nel settore, neanche troppo sorprendente: i benchmark mentono. Quelli “serissimi”, venduti come test chirurgici per la logica temporale o per la competenza matematica, in realtà si rivelano molto meno specifici. TimeQA, per esempio, dovrebbe valutare il ragionamento sul tempo. E invece propone solo domande di difficoltà media, senza scalare né verso il basso né verso l’alto. Un modello potrebbe cavarsela per puro colpo di fortuna o per pattern recognition, e tu penseresti: “Wow, ha capito il tempo!”. No, ha solo memorizzato qualche trucchetto.
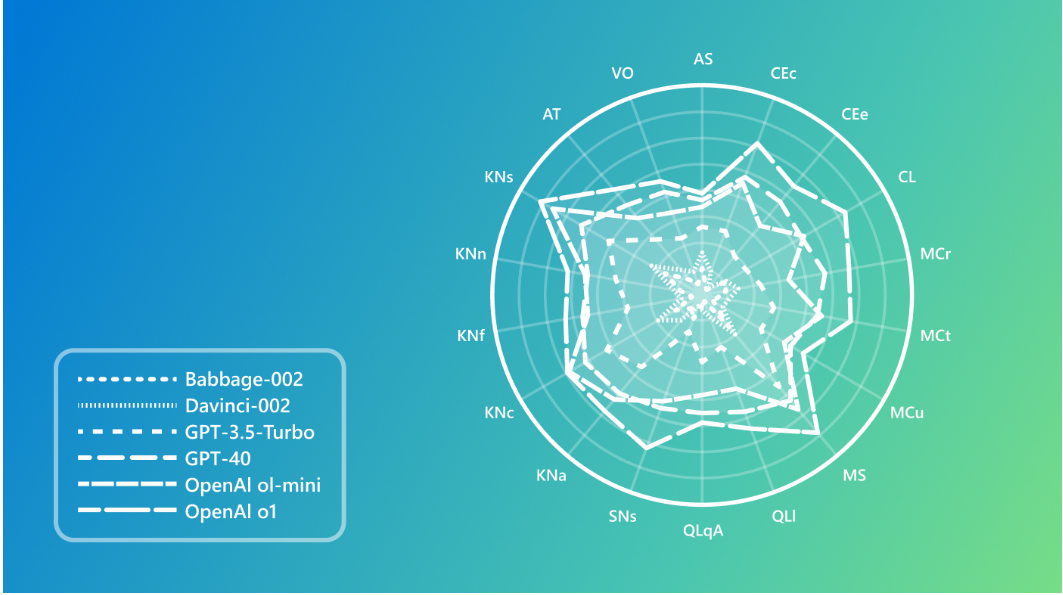
E non finisce qui. Seconda scoperta illuminante: ogni LLM ha una personalità. Non nel senso new age “sento che GPT-4 mi capisce”, ma nel senso tecnico che ciascun modello ha un profilo unico sulle 18 dimensioni cognitive. Microsoft ha profilato 15 modelli diversi da GPT-4 a LLaMA-3.1-405B passando per il sottovalutato Babbage e ha ottenuto delle radar chart che sembrano più i profili MBTI di un team aziendale. Alcuni modelli sono ottimi nel ragionamento, ma crollano sulla conoscenza sociale. Altri viceversa. E qui emerge l’amara verità: più grande non significa migliore. Solo… più grosso.
E infine, la vera bomba: ADeLe non solo analizza, ma prevede. Sì, con una precisione dell’88%, è in grado di dirti se un modello fallirà prima ancora che ci provi. Roba da preveggenza algoritmica. Se sei un ricercatore, questo significa risparmiare ore di test. Se sei un imprenditore, significa non dover aspettare che il tuo chatbot faccia figuracce davanti a un cliente per capire che hai puntato sul cavallo sbagliato.
La portata strategica di ADeLe è enorme, soprattutto in ottica multimodale e robotica. Perché quando hai un sistema che combina visione, linguaggio, ragionamento e interazione fisica, non puoi più limitarti a dire “ha funzionato o no”. Devi sapere perché ha funzionato, dove ha inciampato, cosa ha capito e cosa ha solo scimmiottato. Il futuro non è l’output, ma la motivazione dell’output.
Questa è l’era del grading interpretativo per i modelli. Un ritorno alla valutazione argomentata, non più numerica. Un cambiamento che riduce l’opacità dei modelli e rende finalmente visibile il confine tra intelligenza e furbizia statistica.
E ora che ADeLe ci mostra come i modelli pensano, possiamo anche iniziare a chiedere di più. O meglio, possiamo smettere di credergli sulla parola. Perché, diciamocelo: se il tuo LLM prende 90 su MMLU ma non sa distinguere “prima” da “dopo”, forse la vera intelligenza è capire quando ci stanno prendendo in giro.
Come diceva il barista dell’università: “non è che uno è intelligente perché passa l’esame. Magari ha solo avuto culo con le domande.” Ora finalmente abbiamo un modo per scoprirlo.