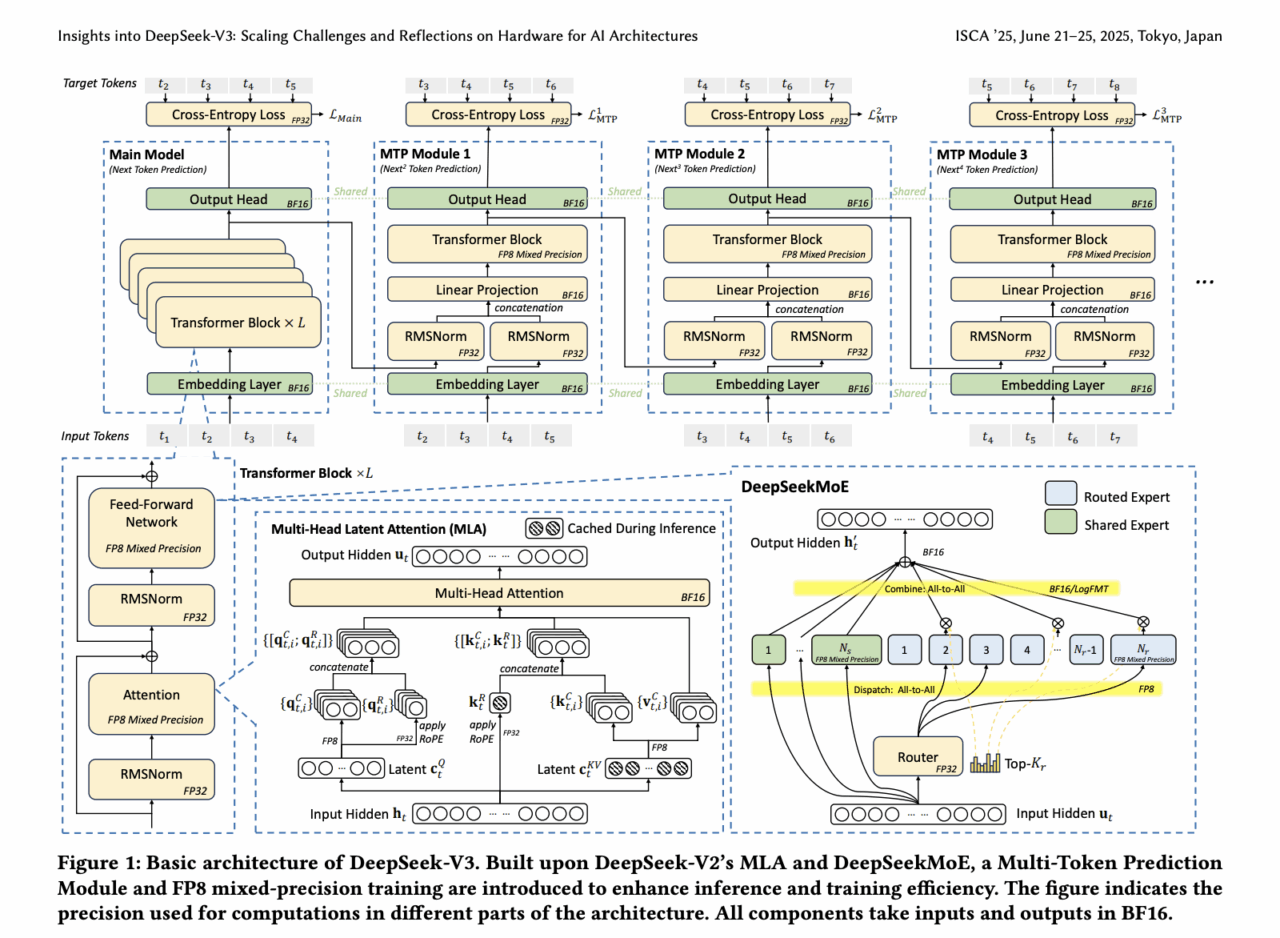
Uno sguardo freddo su documento presenato a ISCA 2025 (52nd Annual International Symposium on Computer Architecture, Tokyo Japan, June 21 – 25, 2025) di DeepSeek‑V3 rivela un mix esplosivo di ingegneria hardcore e visioni che rasentano la fantascienza. Il modello da 671 miliardi di parametri gira su “solo” 2 048 GPU NVIDIA H800, sfruttando Multi‑Head Latent Attention per ridurre l’occupazione dei KV cache a 70 KB per token, Mixture‑of‑Experts che attiva solo 37B parametri per token (circa 5 % del totale) e precisione FP8 che dimezza tempi e costi. La topologia “Multi‑Plane Network” ottimizza congestione e latenza nel training, placcando forti colpi al muro hardware‑model co‑design arXiv.
Poi però salta fuori la slide killer: “Region‑based acquire‑release” con +62 % di prestazioni. Funziona? No. Non esiste alcun supporto hardware noto per regioni semantic‑aware nella memoria distribuita. È come promettere una memoria che “capisce” i dati: intrigante, ma al momento pura speculazione. Nessuna API, nessun supporto a livello di cache L3 o protocolli di coerenza. Solo una slide che lascia l’ecosistema interdetto.
Sui social, LinkedIn riprende il cuore tecnico – MLA e MoE – ma evita la region bomb. Reddit incalza, e un utente commenta:
“Open‑weight doesn’t mean open‑hardware. Shit is confusing as fuck” Reddit
Nelle news, TechNode celebra l’efficienza da urlo: costi 90 % più bassi, KV cache snellissima, topologia network a prova di bomba. PYMNTS nota invece le preoccupazioni sulla sicurezza nazionale: DeepSeek cresce tra le imprese americane ma molti paesi bocciano l’uso governativo . RAND interpreta il tutto come un “access effect”: con meno calcolo si democratizza l’AI potente, mentre i big – Apple, Google, Nvidia – sentono il fiato sul collo.
In Europa? Siamo spettatori col broncio. Mentre DeepSeek sposta l’asticella del co‑design, noi continuiamo a partorire micro‑grant da 30 k€, concentrare cervelli in paper ben impaginati, intitolare “flagship” progetti che suonano bene ma non scalano davvero. A furia di far contenti tutti, esportiamo slogan e keynote patinati. Ma serve una DeepSeek nostrana, una filiera hardware‑model integrata, con rischio vero, budget forte e prototipi reali.
DeepSeek provoca: o si risponde con visione radicale, o si resta a guardare. Tra Milano e Berlino, prego, versatevi un bicchiere: la battaglia sull’accesso semantico alla memoria forse è iniziata, e sarà uno spettacolo – grottesco, fragoroso, forse anche esilarante.
Problemi Identificati
Latenza aggiuntiva (RTT) e sincronizzazione in RDMA
- Nelle architetture distribuite (come quelle usate per LLM, training distribuito, o inferenza su più nodi), ogni comunicazione tra nodi introduce latenza dovuta al Round-Trip Time (RTT).
- RDMA (Remote Direct Memory Access) consente accesso diretto alla memoria remota, ma senza un ordinamento garantito, possono verificarsi problemi di coerenza.
Necessità di barriere di memoria (fence)
- Dopo una scrittura in memoria remota, il mittente deve emettere una barriera di memoria (fence) prima di aggiornare un flag di notifica.
- Questo introduce overhead e potenziali colli di bottiglia.
Soluzioni Proposte e Rilevanza per DeepSeek
a) Supporto hardware per ordinamento garantito
- DeepSeek, essendo un modello ad alte prestazioni, potrebbe beneficiare di acceleratori hardware (come SmartNIC o processori specializzati) che garantiscano l’ordinamento automatico dei messaggi, riducendo la necessità di sincronizzazione software.
b) Bufferizzazione e numeri di sequenza (PSN)
- Se DeepSeek opera in un ambiente distribuito (es: multi-GPU o multi-node), l’uso di PSN (Packet Sequence Numbers) potrebbe aiutare a riordinare i pacchetti in modo efficiente, evitando stalli o letture inconsistenti.
c) Meccanismo RAR (Region-based Acquire/Release)
- Questo approccio fornisce semantiche di sincronizzazione più flessibili rispetto alle barriere globali.
- Per DeepSeek, che potrebbe avere pattern di accesso alla memoria eterogenei (es: alcuni layer più dipendenti da dati remoti di altri), RAR potrebbe ottimizzare la comunicazione riducendo i tempi di attesa.
Possibili Ottimizzazioni per Modelli come DeepSeek
- Pipeline più efficiente: Riducendo i ritardi nella comunicazione inter-nodo, si migliora l’efficienza del training e dell’inferenza distribuita.
- Minore overhead di sincronizzazione: Con meccanismi hardware o RAR, si riduce la necessità di barriere esplicite, accelerando operazioni come gradient aggregation in training distribuito.
- Supporto per scale-out: Garantire coerenza e ordinamento efficiente è cruciale per scalare su migliaia di GPU (come nei grandi cluster AI).
Problematiche cruciali per sistemi ad alte prestazioni come DeepSeek, dove la comunicazione memory-semantic efficiente è essenziale per:
Ridurre la latenza nelle operazioni distribuite
Garantire coerenza senza eccessivo overhead
Migliorare la scalabilità in ambienti multi-nodo
L’integrazione di soluzioni hardware (come PSN e RAR) potrebbe essere un’area di ottimizzazione per future versioni di modelli LLM ad alte prestazioni.
Domande aperte:
- DeepSeek utilizza RDMA o protocolli simili per la comunicazione inter-GPU/inter-node?
- Ci sono meccanismi specifici per gestire l’ordinamento nelle operazioni collective (es: AllReduce)?
- Sarebbe utile un’analisi più approfondita su come queste ottimizzazioni potrebbero ridurre i tempi di training?