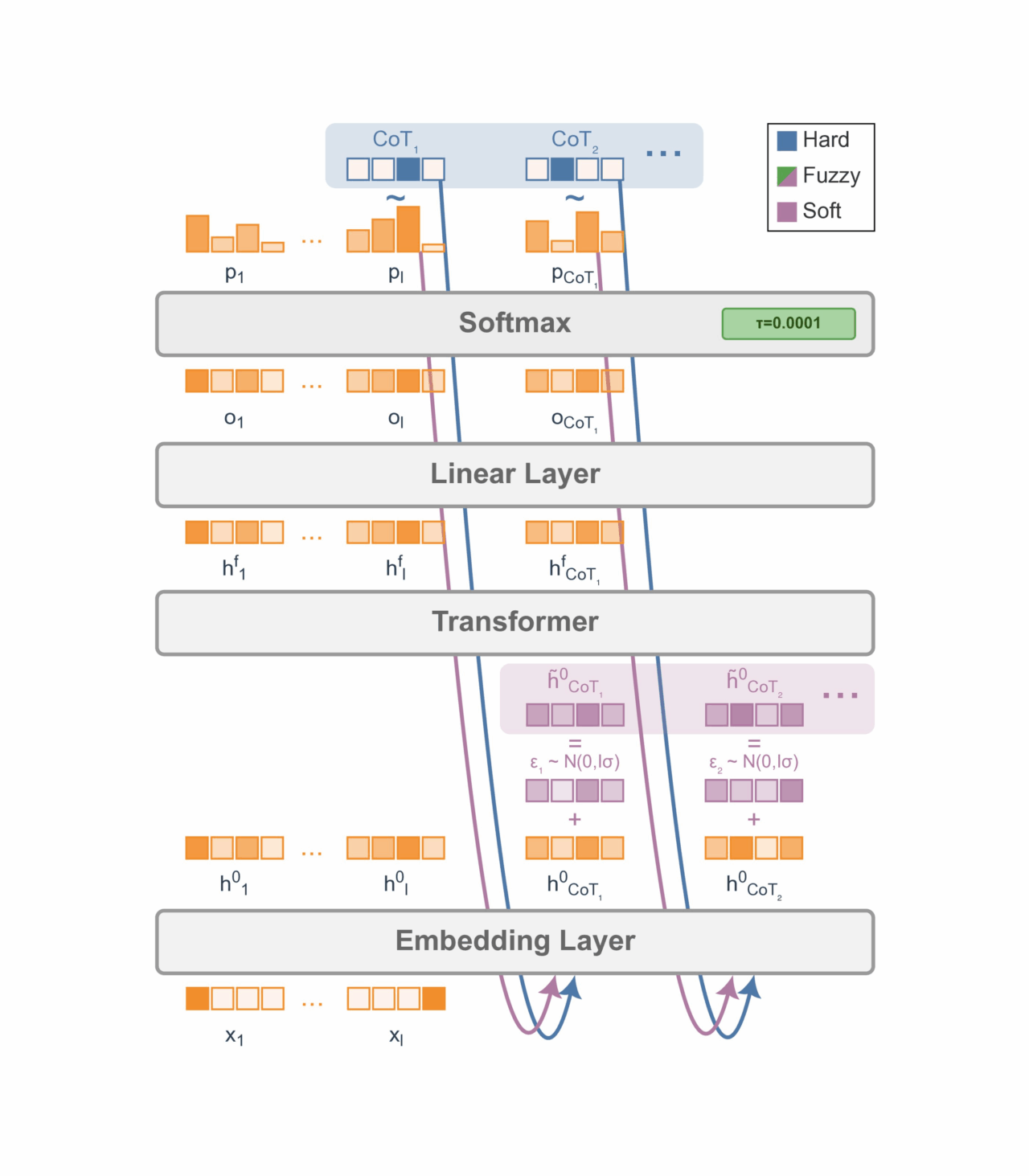
Meta, in collaborazione con l’Università di Amsterdam e la New York University, ha recentemente pubblicato su arXiv un articolo intitolato “Soft Tokens, Hard Truths”, che introduce un metodo innovativo per allenare i modelli linguistici di grandi dimensioni (LLM) a ragionare utilizzando catene di pensiero continue (CoT) tramite l’apprendimento per rinforzo, senza la necessità di distillare da CoT discrete di riferimento.
L’idea centrale è superare le limitazioni dei token linguistici discreti, che costringono gli LLM a passaggi di ragionamento sequenziali, impiegando “soft tokens”: miscele di token con aggiunta di “rumore” sugli embedding di input per fornire esplorazione nell’apprendimento per rinforzo. Questo approccio consente agli LLM di simulare una sovrapposizione di più percorsi di ragionamento simultaneamente, portando a una risoluzione dei problemi più espressiva ed efficiente.
Lo studio dimostra che quando i sistemi sono autorizzati a abitare stati continui e probabilistici, piuttosto che essere costretti in stati discreti e deterministici, emergono forme completamente nuove di intelligenza e ragionamento. Questa prospettiva non solo avanza il ragionamento degli LLM, ma suggerisce anche un paradigma più ampio: abbracciare la variabilità intrinseca—anziché sopprimerla—potrebbe ispirare innovazioni in molti domini, dall’architettura dell’IA alla gestione del rumore nel calcolo quantistico.
L’articolo “Soft Tokens, Hard Truths” presenta un approccio innovativo per migliorare le capacità di ragionamento degli LLM sfruttando percorsi di ragionamento continui. Questo metodo non solo migliora le prestazioni sui benchmark esistenti, ma apre anche la strada a sistemi di IA più adattabili e intelligenti in futuro.