
Mentre i recenti generatori di immagini da testo come Google’s Imagen e OpenAI’s DALL-E hanno attirato molta attenzione, i ricercatori della Tsinghua University e della BAAI intendono fare un passo avanti proponendo un generatore di video da testo, chiamato CogVideo, che si dice sia in grado di superare di gran lunga tutti i modelli pubblicamente disponibili nelle valutazioni di macchina e umane. Diamo un’occhiata ad alcune demo qui sotto.
Dato un prompt di testo come “Una donna sta correndo sulla spiaggia nel tardo pomeriggio”, il modello genererà un video di 480×480 come quello qui sotto.

Oppure un cuore in fiamme:

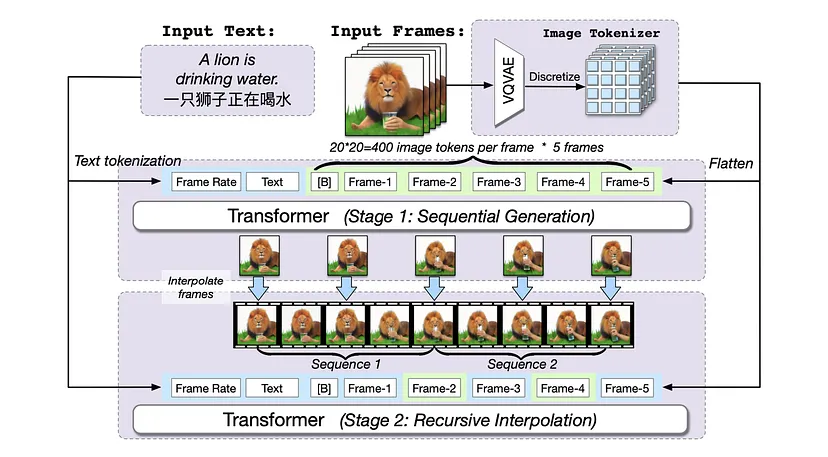
Dettagli tecnici: CogVideo è costruito sul modello di testo-immagine pre-addestrato della BAAI, CogView2, migliorato da una strategia di addestramento gerarchica a più frame rate per allineare meglio il testo e i clip video. Come spiegato nella carta, “La sequenza di input include la frequenza dei fotogrammi, il testo, i token di fotogrammi. B è un token separatore, ereditato da CogView2. Nella fase 1, vengono generati Ts fotogrammi in sequenza sulla base della frequenza dei fotogrammi e del testo. Poi, nella fase 2, i fotogrammi generati vengono reinseriti come regioni di attenzione bidirezionale per interpolare ricorsivamente i fotogrammi. La frequenza dei fotogrammi può essere regolata durante entrambe le fasi. Le regioni di attenzione bidirezionale sono evidenziate in blu e quelle unidirezionali in verde”. In sostanza, CogVideo è un Transformer con 9 miliardi di parametri pre-addestrati su un set di dati di 5,4 milioni di video con didascalie.
Perché è importante: CogVideo è stato definito come il primo modello open-source su larga scala per la generazione di video da testo. I ricercatori sperano che questo progetto possa essere utile ai creatori di video brevi o agli artisti digitali. Inoltre, CogVideo è un’eredità di successo dei modelli di testo-immagine, quindi i ricercatori non devono costruire modelli di testo-video da zero.
Confronto con i modelli statunitensi:
CogVideo si distingue dai modelli statunitensi come Google’s Imagen e OpenAI’s DALL-E per la sua capacità di generare video da un prompt di testo, mentre i modelli statunitensi si concentrano principalmente sulla generazione di immagini. Inoltre, CogVideo è un modello open-source, il che significa che chiunque può accedervi e utilizzarlo, mentre i modelli statunitensi non sono sempre open-source. Infine, CogVideo è stato addestrato su un set di dati di 5,4 milioni di video con didascalie, che è un set di dati più ampio rispetto a quelli utilizzati per i modelli statunitensi. Questo potrebbe contribuire alla capacità di CogVideo di superare i modelli statunitensi nelle valutazioni di macchina e umane.
Lascia un commento
Devi essere connesso per inviare un commento.