
Nel mondo dell’intelligenza artificiale, la gestione e l’ottimizzazione dei modelli linguistici di grandi dimensioni (LLM) è diventata un aspetto cruciale per il successo delle applicazioni basate su IA. Sebbene i modelli LLM alimentino una vasta gamma di applicazioni, il monitoraggio delle loro performance, dei costi e dei comportamenti rimane una sfida significativa. Gli strumenti di osservabilità esistenti spesso non forniscono approfondimenti completi, rendendo difficile la risoluzione dei problemi e il miglioramento continuo. Inoltre, il mantenimento della privacy dei dati e la conformità alle normative aumentano ulteriormente la complessità di queste operazioni.
Categoria: Tech Pagina 4 di 22
L’intelligenza artificiale (AI) nel suo senso piu’ ampio e l’intelligenza esibita dai sistemi informatici (Machine)
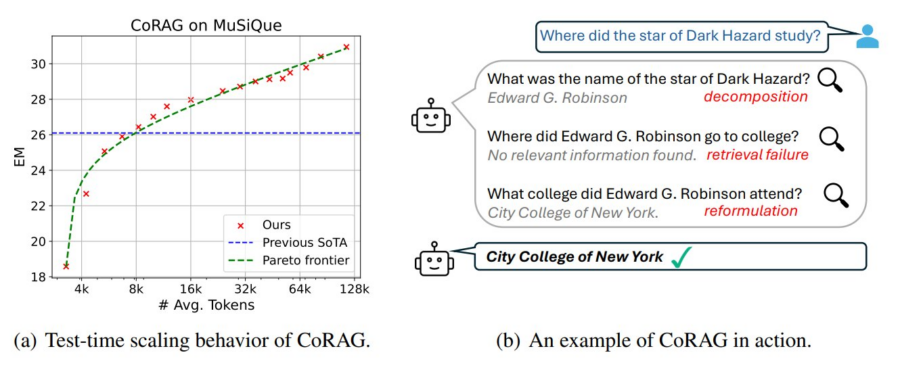
La generazione aumentata dal recupero delle informazioni (Retrieval-Augmented Generation, RAG) si evolve con l’introduzione del Chain-of-Retrieval Augmented Generation (CoRAG), che combina il potere del recupero iterativo con modelli di ragionamento Chain-of-Thought (CoT). Questo approccio consente di affrontare domande complesse suddividendo il processo in passaggi successivi, recuperando informazioni rilevanti e ragionando su di esse prima di generare una risposta finale.
Cos’è il CoRAG?
Il CoRAG migliora il tradizionale RAG integrando un ragionamento passo-passo, emulando il modo in cui un essere umano affronta domande a più livelli (multi-hop). Questo approccio si rivela cruciale in contesti dove una semplice pipeline “query-risposta” non è sufficiente, come nei task di domande complesse o nei problemi che richiedono più passaggi logici per essere risolti.

DeepSeek AI ha presentato DeepSeek-R1, un modello open source che si pone come un diretto concorrente del noto OpenAI-o1 nei compiti di ragionamento complesso. Questo traguardo è stato raggiunto grazie all’introduzione di un algoritmo innovativo chiamato Group Relative Policy Optimization (GRPO) e a un approccio multi-stage basato sul reinforcement learning (RL). La combinazione di queste tecniche ha consentito di superare molte delle limitazioni tradizionali nei modelli di intelligenza artificiale per il ragionamento avanzato.

Con il rilascio di Janus Pro, il laboratorio cinese DeepSeek ha lanciato una sfida diretta a DALL-E 3, il modello generativo di immagini di punta di OpenAI. Janus Pro si distingue per essere un modello open-source che offre prestazioni superiori in benchmark chiave come GenEval e DPG-Bench, una mossa che potrebbe ridefinire gli equilibri tra i leader dell’intelligenza artificiale multimodale.
Con l’avanzare dell’Intelligenza Artificiale, il mercato sta richiedendo sempre più applicazioni capaci di comprendere non solo il comportamento degli utenti, ma anche l’ambiente in cui operano. Tuttavia, gli strumenti esistenti per sviluppare tali applicazioni lasciano spesso a desiderare, costringendo gli sviluppatori a gestire API frammentate e soluzioni basate sul cloud che introducono complessità, rischi per la privacy e inefficienze infrastrutturali. Qui entra in gioco ScreenPipe, una piattaforma open-source progettata per trasformare il modo in cui si sviluppano, distribuiscono e monetizzano applicazioni AI con contesto completo, tutto in locale.

Meta ha annunciato un’espansione significativa delle capacità del suo chatbot AI, che ora sarà in grado di “ricordare” dettagli personali degli utenti, come preferenze alimentari o interessi, migliorando così le interazioni e rendendo le raccomandazioni più pertinenti. Questa nuova funzione, spiegata in un post sul blog aziendale, rappresenta un ulteriore passo nella personalizzazione dell’esperienza utente, utilizzando non solo le conversazioni precedenti, ma anche informazioni provenienti dagli account Facebook e Instagram degli utenti.

La società cinese DeepSeek, già al centro dell’attenzione per il rilascio del modello open-source R1, ha lanciato un secondo modello multimodale open-source, Janus Pro-7B, che promette di ridefinire gli standard nell’intelligenza artificiale. Il modello è stato reso disponibile su Hugging Face, una piattaforma leader per l’IA, con l’obiettivo dichiarato di offrire comprensione e generazione unificata. Secondo DeepSeek, il Janus Pro-7B supera i precedenti modelli multimodali unificati e compete, se non addirittura eccelle, rispetto alle prestazioni dei modelli specifici per singoli compiti. Questo lo rende un forte candidato per le applicazioni di prossima generazione nel campo multimodale.
DeepSeek says its newest AI model, Janus-Pro can outperform Stable Diffusion and DALL-E 3.
Already riding a wave of hype over its R1 “reasoning” AI that is atop the app store charts and shifting the stock market, Chinese startup DeepSeek has released another new open-source AI model: Janus-Pro.
Può analizzare o produrre solo immagini piccole a una risoluzione di 384×384, ma l’azienda afferma che la versione più grande, Janus-Pro-7b, ha superato modelli comparabili in due test di riferimento per l’IA.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25848993/Clipboard_01_27_2025_01.jpg)
Image: DeepSeek
Nel panorama tecnologico moderno, l’estrazione di dati da siti web è diventata una necessità fondamentale per alimentare motori di ricerca, raccogliere informazioni e alimentare intelligenze artificiali. Tradizionalmente, questo processo ha richiesto l’uso di molteplici strumenti e framework, ognuno dei quali era specializzato in una parte del flusso di lavoro, che includeva il crawling, lo scraping e l’estrazione di contenuti. Tuttavia, l’evoluzione delle esigenze e delle soluzioni ha portato all’emergere di strumenti avanzati che semplificano tutto il processo. Firecrawl è una di queste innovazioni rivoluzionarie, che offre una soluzione all-in-one per la raccolta e l’elaborazione dei dati da qualsiasi sito web.
Firecrawl è un’API open-source progettata per ottimizzare l’estrazione dei dati da pagine web, permettendo di ottenere informazioni strutturate e pulite pronte per essere utilizzate in applicazioni di intelligenza artificiale, tra cui modelli di linguaggio di grandi dimensioni (LLM). Questa API è capace di combinare scraping, crawling e l’estrazione dei dati in un unico pacchetto, riducendo drasticamente la complessità per chi sviluppa applicazioni basate sull’elaborazione di dati web.
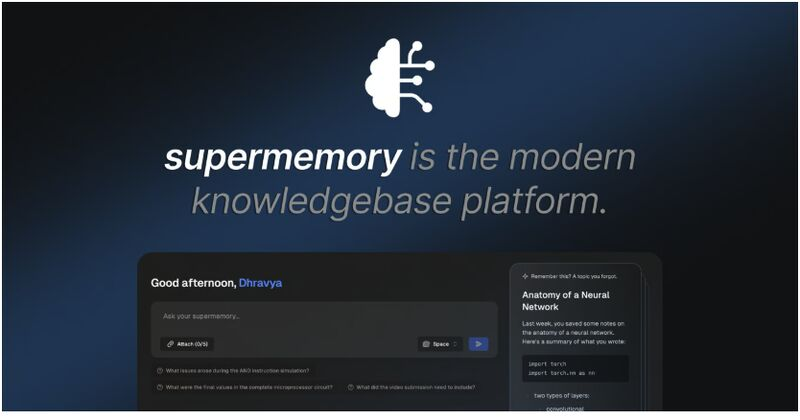
Nel mondo iperconnesso e saturo di informazioni in cui viviamo, la capacità di gestire, recuperare e organizzare i dati pertinenti è diventata una delle sfide più grandi per chiunque sia coinvolto nella tecnologia, nel business o anche nella vita quotidiana. Tra segnalibri, tweet salvati, contenuti web e note sparse, l’efficienza del nostro lavoro e la nostra produttività tendono a calare inesorabilmente. In questo marasma, si fa sempre più difficile trovare le informazioni giuste al momento giusto.
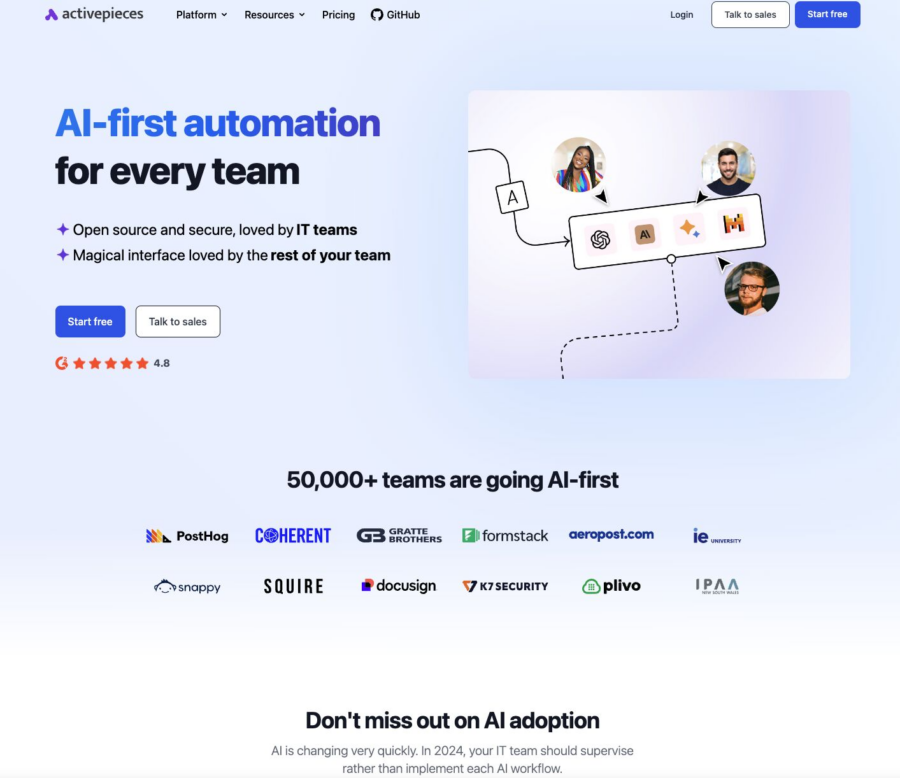
Nel panorama in rapida evoluzione dell’automazione, le soluzioni di workflow stanno diventando sempre più essenziali per ottimizzare i processi aziendali e risparmiare tempo. Strumenti noti come Zapier e Make.com dominano il settore, offrendo potenti funzionalità di automazione, ma con costi che possono crescere rapidamente. Tuttavia, per le aziende o i singoli che cercano un’alternativa economica, flessibile e, soprattutto, open-source, 𝗔𝗰𝘁𝗶𝘃𝗲𝗽𝗶𝗲𝗰𝗲𝘀 potrebbe rappresentare la soluzione ideale. Questo strumento non solo permette di automatizzare flussi di lavoro, ma è anche progettato per essere altamente personalizzabile e facile da estendere, grazie alla sua architettura basata su TypeScript.
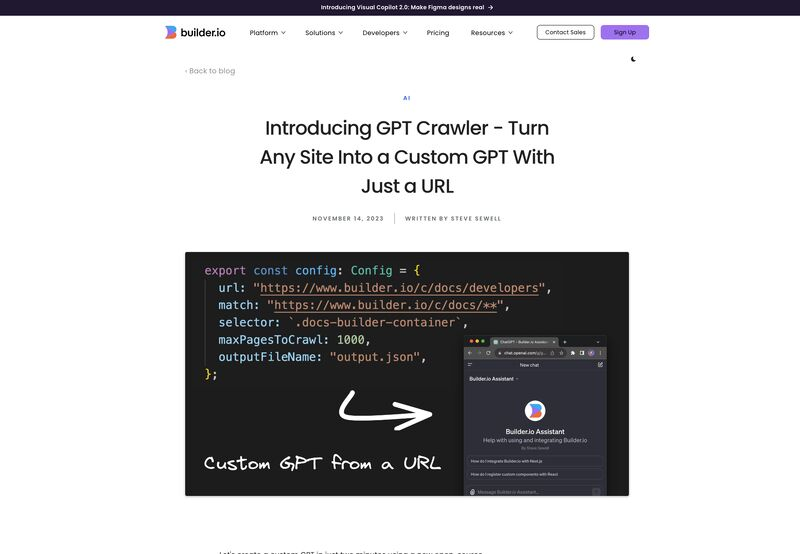
Nell’era attuale, la conoscenza è facilmente accessibile; la troviamo nei nostri documenti, database, e online. Tuttavia, se si desidera trasformare siti web in una base per creare GPT personalizzati e di valore, la strada da percorrere non è così semplice. L’approccio tradizionale di crawling manuale, raccolta di dati, e organizzazione accurata può essere un processo laborioso, soggetto ad errori e costoso in termini di tempo. Per non parlare della gestione di dataset di grandi dimensioni che richiedono strumenti robusti e una competenza tecnica non indifferente.

Nel panorama tecnologico in continua evoluzione, un cambiamento significativo, seppur sottile, sta avvenendo sotto i nostri occhi: la rapida ascesa degli agenti AI. Questi agenti rappresentano una perfetta fusione tra Intelligenza Artificiale (AI) e Automazione, un binomio che promette di ridefinire il modo in cui operiamo in molti settori. Sebbene il concetto possa sembrare semplice – AI combinata con automazione – la sua implementazione è molto più complessa di quanto sembri. I sistemi di automazione tradizionali, seppur ampiamente utilizzati, mancano di quell’intelligenza avanzata necessaria per gestire compiti più sofisticati. Gli agenti AI, invece, promettono di colmare questa lacuna.

Nel panorama tecnologico attuale, l’intelligenza artificiale generativa è diventata una parte essenziale di molte applicazioni aziendali e prodotti, trasformando radicalmente il modo in cui le aziende interagiscono con i loro utenti e migliorano i loro processi. Dalla creazione automatica di contenuti al miglioramento dell’efficienza operativa, le potenzialità di queste tecnologie sono enormi. Tuttavia, nonostante la sua diffusione, integrare efficacemente l’IA generativa in applicazioni pratiche rimane una sfida significativa, soprattutto quando si tratta di monitorare e migliorare continuamente la qualità delle risposte generate.
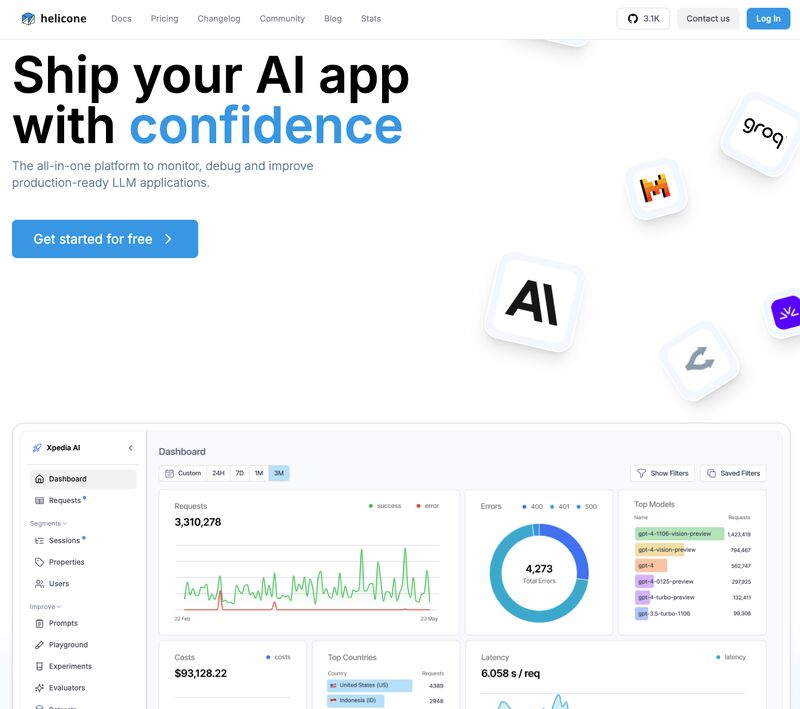
Gestire e ottimizzare i modelli linguistici di grandi dimensioni (LLM) è diventato uno dei pilastri fondamentali per il successo di molte applicazioni basate sull’intelligenza artificiale. Tuttavia, la sfida di monitorare prestazioni, costi e comportamenti degli LLM rimane un punto dolente per molte aziende e sviluppatori. Spesso, gli strumenti di osservabilità tradizionali si dimostrano inadeguati, offrendo una visione limitata e rendendo difficile l’identificazione dei problemi o l’ottimizzazione delle prestazioni.
Nel mondo frenetico dell’intelligenza artificiale, la gestione dei dati è uno degli aspetti più critici e allo stesso tempo complessi. L’elaborazione dei dati implica una vasta gamma di attività, dalla comprensione alla trasformazione, e tutto ciò si traduce nell’estrazione di informazioni da fonti non strutturate come immagini, documenti e altri formati complessi. Per molti, questo processo è notoriamente difficile e costoso, soprattutto quando si cerca di integrare dati provenienti da fonti eterogenee. Ecco perché nasce Sparrow, un’innovativa soluzione open-source che promette di semplificare e rendere più efficiente questo processo attraverso l’uso di tecnologie avanzate come Machine Learning (ML), Large Language Models (LLM), e Vision LLM.

In una mossa che fonde sport e tecnologia, la Cina si prepara a ospitare una delle competizioni più strane mai viste: una mezza maratona dove 12.000 umani sfideranno un esercito di robot umanoidi. La gara, lunga 21 chilometri, avrà luogo nel distretto di Beijing’s Daxing e non sarà un semplice esperimento tecnologico. Con oltre 20 aziende in campo, i robot parteciperanno per veri premi in denaro destinati ai primi tre classificati, indipendentemente dal fatto che siano fatti di carne o di metallo.
Nel mondo in continua evoluzione dell’intelligenza artificiale, lo sviluppo di agenti AI autonomi è da sempre una sfida complessa e dispendiosa in termini di risorse. Gli sviluppatori devono affrontare una miriade di configurazioni intricate, esigenze di programmazione e gestione continua per dare vita a questi agenti. Sebbene il mercato sia inondato da strumenti, framework e linee guida per supportare questo processo, la complessità può risultare travolgente, rallentando i tempi di sviluppo e rendendo difficile il dispiegamento di agenti affidabili ed efficienti. Per le aziende e gli sviluppatori, questo ha spesso significato dedicare più tempo alla costruzione dell’infrastruttura degli agenti piuttosto che concentrarsi sul reale valore che intendono offrire.
Ma cosa succederebbe se esistesse un modo per trasformare completamente questo processo, semplificando la creazione, la configurazione e il dispiegamento degli agenti AI autonomi in un modo talmente semplice da sembrare una normale navigazione web? Ecco che arriva AgentGPT, un progetto open-source pensato per rivoluzionare il modo in cui gli sviluppatori lavorano con gli agenti AI.

La gestione e l’analisi dei dati stanno affrontando una trasformazione epocale. Le organizzazioni si trovano spesso a gestire dati frammentati in database, data warehouse e data lake, con la difficoltà di integrarli e sfruttarli appieno per l’intelligenza artificiale e il machine learning. Questa frammentazione rappresenta una barriera all’innovazione e rallenta i processi basati sui dati.
MindsDB emerge come soluzione innovativa a questo problema. Si tratta di una piattaforma open-source che consente di costruire soluzioni AI capaci di apprendere dai dati e rispondere a domande complesse sfruttando un approccio federato. L’idea di base è quella di un motore di query federato che permette di connettere, analizzare e trasformare dati provenienti da fonti eterogenee in modo rapido e intuitivo.
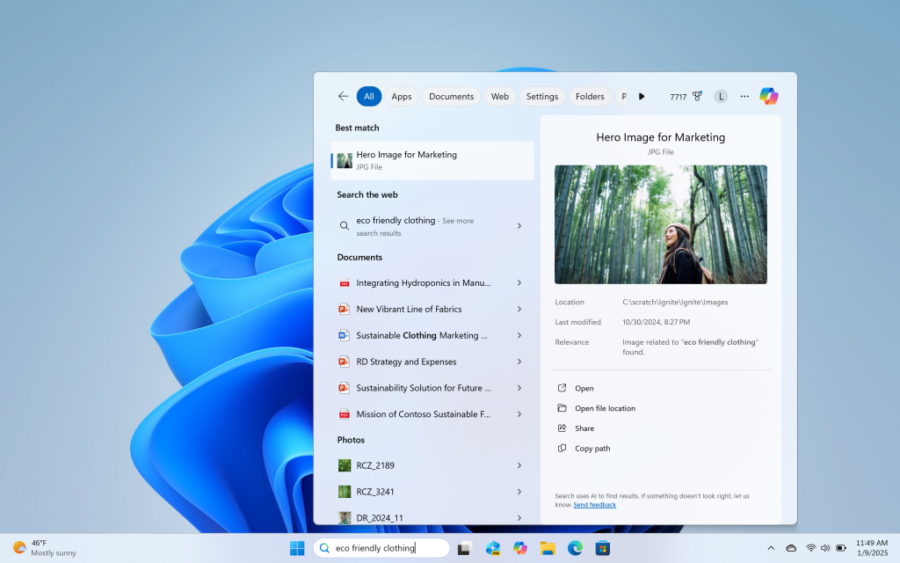
Microsoft ha recentemente avviato una fase di test per una delle novità più promettenti della prossima versione di Windows 11, introducendo una funzionalità di ricerca alimentata dall’intelligenza artificiale. L’innovativa ricerca semantica, annunciata a ottobre, è ora disponibile per gli utenti Insider su build dedicate, e promette di semplificare l’esperienza di ricerca dei file locali, rendendola più intuitiva grazie all’uso di linguaggio naturale.
L’innovazione si inserisce nel contesto di una costante evoluzione delle funzionalità AI di Microsoft, che mirano a rendere l’interazione con il sistema operativo sempre più fluida e naturale. A differenza dei tradizionali motori di ricerca che richiedono comandi o parole chiave specifiche, questa nuova funzionalità consente agli utenti di esprimere ricerche più casuali e colloquiali, come se stessero chiedendo aiuto a un assistente virtuale.

Il processo di ricerca del lavoro può risultare schiacciante e dispendioso in termini di tempo. Le numerose domande da compilare, le opportunità che scivolano via e la necessità di seguire meticolosamente ogni applicazione portano spesso a un esaurimento mentale, con il rischio di perdere occasioni promettenti. Questo è un problema comune per chi cerca lavoro oggi, dove il tempo e le risorse sono risorse sempre più limitate.
La tradizionale ricerca di lavoro prevede l’invio manuale di centinaia di CV, lettere di presentazione personalizzate per ogni posizione, e una costante attività di follow-up che può facilmente sfociare nella frustrazione. Eppure, nel 2025, siamo finalmente pronti a sfruttare le potenzialità dell’intelligenza artificiale per ridurre la fatica e migliorare i risultati.
Ecco dove entra in gioco 𝗔𝗜𝗛𝗮𝘄𝗸 (𝗝𝗼𝗯𝘀_𝗔𝗽𝗽𝗹𝗶𝗲𝗿_𝗔𝗜_𝗔𝗴𝗲𝗻𝘁)—un agente open-source alimentato da intelligenza artificiale che semplifica e ottimizza il processo di candidatura. Grazie all’adozione di algoritmi avanzati, 𝗔𝗜𝗛𝗮𝘄𝗸 aiuta gli utenti a inviare candidature per decine o centinaia di lavori in modo rapido ed efficiente, aumentando significativamente le possibilità di ottenere il lavoro dei propri sogni.
Nel panorama in rapida evoluzione della tecnologia AI, gli agenti autonomi rappresentano una delle innovazioni più intriganti e complesse. Tuttavia, affrontare la sfida di costruire e gestire questi agenti può sembrare scoraggiante, specialmente per chi non dispone di una profonda esperienza tecnica o risorse significative. Progettare sistemi scalabili, sicuri ed efficienti richiede un approccio strutturato, e molti sviluppatori si trovano sopraffatti dall’enorme complessità dell’ecosistema.
In questo contesto, emerge SuperAGI, una piattaforma open-source progettata per semplificare il processo di creazione e gestione di agenti AI autonomi. SuperAGI si posiziona come uno strumento dev-first, pensato per offrire soluzioni concrete a sviluppatori e organizzazioni che desiderano entrare nel mondo degli agenti autonomi senza perdersi nei dettagli tecnici.ù

Negli ultimi anni, i transformers hanno rappresentato il punto di riferimento per i modelli di intelligenza artificiale, dalla traduzione automatica alla modellazione linguistica, fino al riconoscimento delle immagini. Tuttavia, la loro egemonia potrebbe essere messa in discussione da due innovazioni che promettono di ridefinire il panorama dell’AI: le architetture “Titans” di Google e “Transformer Squared” sviluppata dalla startup giapponese Sakana. Questi nuovi modelli, ispirati al funzionamento del cervello umano, puntano a superare i limiti dei transformer tradizionali, rendendo i sistemi più efficienti, flessibili e intelligenti.
I transformers hanno trasformato l’AI grazie al meccanismo di attention, che consente di valutare il contesto di ogni elemento in una sequenza. Questa tecnologia ha introdotto la possibilità di elaborare dati in parallelo, rendendo obsoleti i recurrent neural networks (RNN), che lavoravano in modo sequenziale. Tuttavia, i transformers tradizionali hanno mostrato notevoli limiti in termini di scalabilità, adattabilità e memoria a lungo termine. Una volta addestrati, migliorare il loro funzionamento richiede enormi risorse computazionali o l’uso di strumenti esterni come i modelli LoRA o RAG.

L’intelligenza artificiale (AI) sta rivoluzionando il campo dell’ingegneria del software, non sostituendo gli ingegneri, ma amplificando enormemente le loro capacità. Un esempio notevole di questa sinergia è rappresentato da “screenshot-to-code”, uno strumento open-source che converte screenshot, mockup e design da Figma in codice pulito e funzionale utilizzando l’AI.
Questo strumento supporta vari stack tecnologici, tra cui HTML con Tailwind o CSS, React con Tailwind, Vue con Tailwind, Bootstrap, Ionic con Tailwind e persino SVG. Inoltre, offre un supporto sperimentale per la conversione di video o registrazioni dello schermo in prototipi funzionali, ampliando le possibilità per sviluppatori e designer.

Nel panorama tecnologico odierno, l’automazione dei flussi di lavoro basati su browser rappresenta una sfida significativa per molte aziende. Le soluzioni tradizionali, come Selenium, spesso richiedono script personalizzati che si basano su selettori statici come gli XPath, vulnerabili a qualsiasi modifica del layout del sito web. Questo comporta un notevole dispendio di tempo e risorse per la manutenzione e l’aggiornamento dei processi automatizzati.
Skyvern emerge come una soluzione innovativa a queste problematiche. Si tratta di una piattaforma open-source che sfrutta modelli linguistici di grandi dimensioni (LLM) e tecniche di visione artificiale per automatizzare i flussi di lavoro basati su browser in modo dinamico e resiliente. A differenza degli strumenti tradizionali, Skyvern è in grado di comprendere e interagire con le pagine web in maniera simile a un essere umano, adattandosi ai cambiamenti del layout senza la necessità di interventi manuali.

Immagina di poter creare una nuova interfaccia utente semplicemente descrivendola nel tuo linguaggio naturale. Sembra incredibile, vero? Eppure, con OpenUI, questo è ora possibile.
La creazione di componenti UI richiede tempo ed energia. Sebbene lo sviluppo delle interfacce utente sia diventato più semplice rispetto a dieci anni fa, progettare, codificare e iterare rimane un processo laborioso. Per sviluppatori e team, ciò può comportare un notevole dispendio di risorse, rallentare l’innovazione e creare ostacoli alla sperimentazione.
Come può l’intelligenza artificiale ridurre questo sforzo, mantenendo alta la creatività e la possibilità di sperimentare?
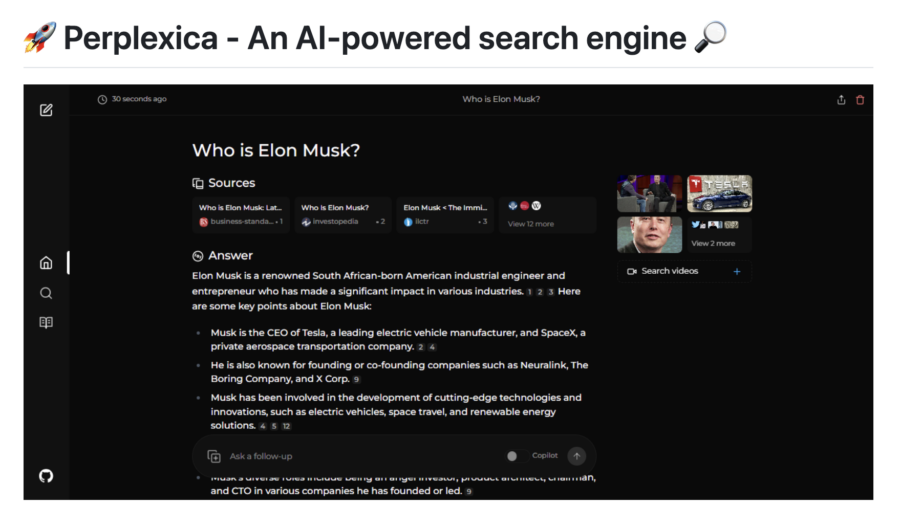
Nel panorama digitale contemporaneo, la ricerca di informazioni rapide e precise è diventata una necessità fondamentale. Tuttavia, molti strumenti di ricerca tradizionali si affidano a tecnologie obsolete o pratiche invasive di raccolta dati, lasciando gli utenti in una posizione di vulnerabilità e spesso insoddisfatti. È proprio in questo contesto che nasce Perplexica, un motore di ricerca open-source e alimentato dall’intelligenza artificiale, progettato per offrire un’esperienza avanzata, sicura e personalizzabile.
Perplexica rappresenta una svolta nell’ambito della ricerca intelligente, combinando algoritmi avanzati di machine learning con modelli di linguaggio naturale per fornire risposte dettagliate, pertinenti e supportate da fonti affidabili. La sua architettura open-source e il focus sulla privacy lo rendono una scelta ideale per chi cerca un’alternativa più etica ed efficace rispetto ai tradizionali motori di ricerca.

Nel mondo moderno, la quantità di informazioni che dobbiamo gestire ogni giorno è davvero abnorme. Con il continuo aumento di dati e compiti da svolgere, l’idea di avere un assistente personale che possa alleviare questa pressione mentale suona quasi come un sogno. E se questo assistente fosse un’Intelligenza Artificiale che potesse non solo organizzare il nostro lavoro, ma anche adattarsi alle nostre necessità e rispettare la nostra privacy? Questo sogno è ora realtà con l’introduzione di Khoj.
Khoj è un’applicazione di intelligenza artificiale open-source e auto-ospitabile che funziona come una sorta di “secondo cervello” personale, in grado di integrare diversi modelli di linguaggio di grandi dimensioni (LLM) per creare un assistente AI altamente personalizzato. La bellezza di Khoj sta nel fatto che, a differenza di altre soluzioni basate sul cloud, questa piattaforma permette di mantenere il controllo completo sui propri dati, ospitandola localmente e proteggendo la privacy dell’utente.
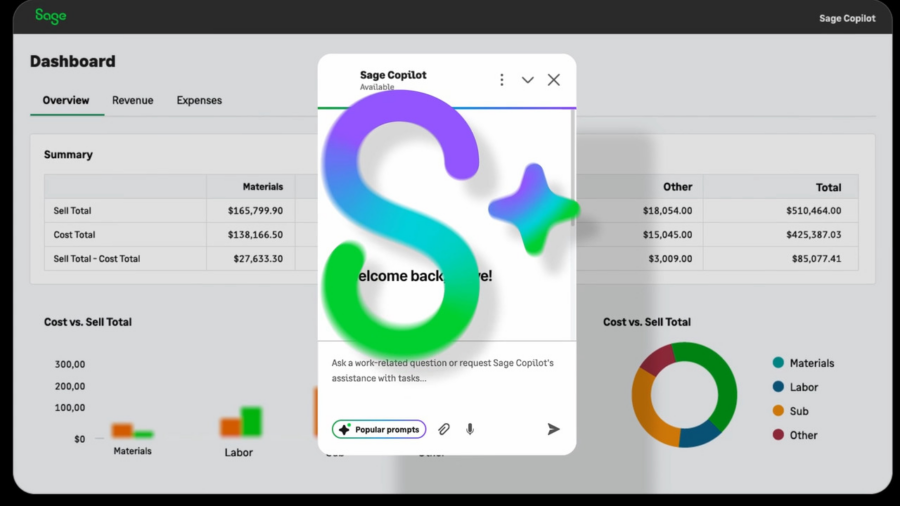
Nell’ambito della programmazione e dello sviluppo, il tempo è una risorsa tanto preziosa quanto limitata. Gli sviluppatori e gli ingegneri software spesso si trovano di fronte a uno dei compiti più ardui e dispendiosi: comprendere e integrarsi rapidamente con grandi codebase. Che si tratti di un nuovo progetto, di un’implementazione di librerie o di collaborazione con altri team, il tempo dedicato alla lettura e alla navigazione tra file e documentazione può ridurre notevolmente la produttività, rallentando il progresso del lavoro e l’efficienza operativa.
Nel contesto odierno, in cui le tecnologie e i framework evolvono rapidamente, l’adozione di soluzioni che riducano questo onere diventa fondamentale. Ecco dove entra in gioco Sage, uno strumento open-source progettato per rivoluzionare il modo in cui gli sviluppatori interagiscono con il codice e ottimizzare il tempo dedicato alla comprensione di progetti complessi.

Nel panorama in rapida evoluzione dell’intelligenza artificiale, la capacità di adattare modelli linguistici di grandi dimensioni (LLM) alle esigenze specifiche di un’organizzazione rappresenta un vantaggio competitivo significativo. Tuttavia, il processo di fine-tuning di questi modelli può risultare complesso e oneroso, richiedendo risorse computazionali elevate e tempi prolungati.È qui che entra in gioco Unsloth, una piattaforma open-source progettata per ottimizzare e accelerare il fine-tuning degli LLM, rendendo questo processo più accessibile ed efficiente.
Unsloth si distingue per la sua capacità di ridurre significativamente il consumo di memoria, permettendo l’utilizzo di fino all’80% in meno di risorse rispetto ai metodi tradizionali. Ciò consente di eseguire il training di modelli su hardware meno potente, democratizzando l’accesso a tecnologie avanzate anche per chi dispone di risorse limitate. Inoltre, la compatibilità con librerie popolari come Hugging Face Transformers, PEFT e bitsandbytes garantisce un’integrazione fluida nei flussi di lavoro esistenti, facilitando l’adozione di Unsloth senza la necessità di modifiche sostanziali alle pipeline operative.
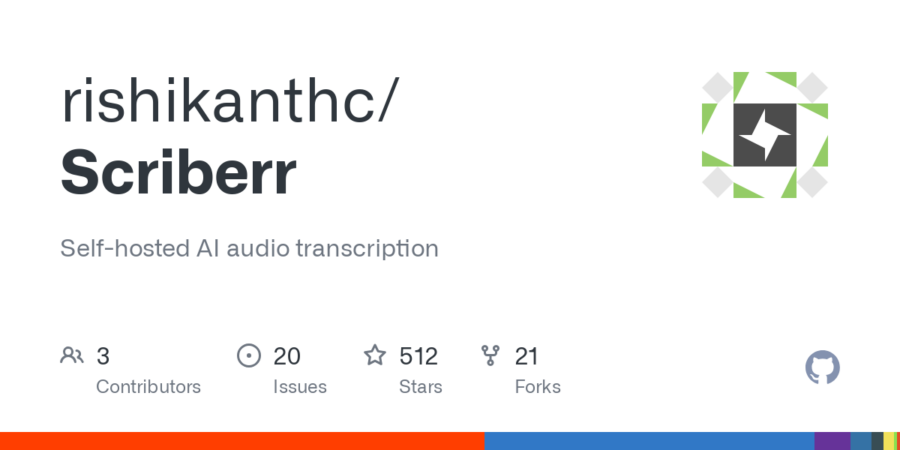
Oggi, i contenuti audio sono più diffusi che mai. Che si tratti di podcast, interviste, riunioni o conferenze, l’audio è diventato uno strumento fondamentale per comunicare informazioni. Tuttavia, la trascrizione di questi file audio in testo può essere un processo lungo e complesso, che richiede spesso l’uso di servizi di terze parti basati su cloud, sollevando preoccupazioni relative alla privacy dei dati.
Immagina di poter trascrivere i tuoi file audio in modo completamente sicuro e senza dover affidare i tuoi dati sensibili a piattaforme esterne. Questo è ciò che Scriberr, un’app di trascrizione audio basata su AI, ti permette di fare, fornendo una soluzione locale che ti garantisce privacy e controllo assoluto sui tuoi contenuti.

Sembra una barzelletta: un gruppo di studenti e consulenti dell’Università di Berkeley tira fuori un modello di intelligenza artificiale di ragionamento avanzato, e il tutto con un budget inferiore a quello di una cena elegante a San Francisco. Non c’è trucco, non c’è inganno: il modello Sky-T1-32B è qui per scompigliare le carte e rendere obsoleti i costosi abbonamenti mensili di OpenAI.
Immaginate questo: OpenAI, con le sue decine di miliardi di dollari di investimenti, giustifica il costo di $200 al mese per un abbonamento ChatGPT Pro basato sul loro modello di ragionamento più avanzato, sostenendo che “è costoso allenare e mantenere queste meraviglie tecnologiche”. Poi arriva Novasky e fa lo stesso lavoro, o meglio, con appena $450. Il modello Sky-T1, che ricorda il primo tentativo di OpenAI nel campo del ragionamento (il modello “Strawberry”), supera quest’ultimo in alcune metriche e si piazza con disinvoltura sul podio delle prestazioni.
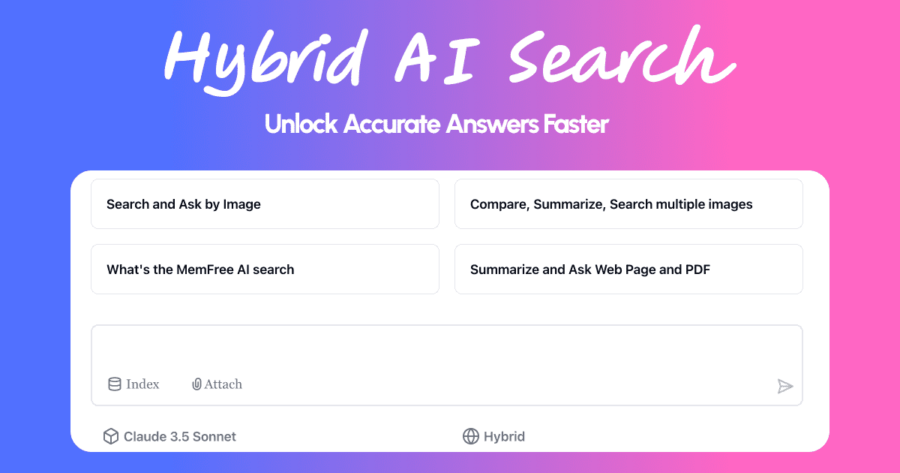
Nel mondo digitale di oggi, la gestione delle informazioni è diventata una sfida sempre più ardua. I lavoratori della conoscenza si trovano a dover fare i conti con una miriade di piattaforme e fonti da cui attingere, perdendo ore preziose a cercare tra segnalibri, note e documenti. Purtroppo, i metodi di ricerca tradizionali non sono più abbastanza rapidi ed efficienti per soddisfare le esigenze moderne.
Fortunatamente, c’è una soluzione che sta trasformando completamente il modo in cui interagiamo con le informazioni: MemFree, un motore di ricerca ibrido basato sull’Intelligenza Artificiale e un generatore di pagine web che rivoluziona il nostro approccio al lavoro quotidiano. Grazie a tecnologie avanzate, MemFree non solo semplifica la ricerca delle informazioni, ma offre anche strumenti per creare pagine web in tempo record, riducendo al minimo il tempo e l’energia spesi nella gestione di contenuti.

Il web scraping rappresenta una pratica indispensabile per l’estrazione di dati, la ricerca e l’automazione di processi. Tuttavia, i metodi tradizionali presentano spesso limiti significativi, tra cui la necessità di un’ampia conoscenza di programmazione, difficoltà nella gestione di contenuti dinamici e mancanza di scalabilità. Questi ostacoli possono tradursi in workflow inefficienti, raccolta di dati imprecisa e un carico di manutenzione oneroso.
𝗦𝗰𝗿𝗮𝗽𝗲𝗴𝗿𝗮𝗽𝗵-𝗮𝗶, uno scraper open-source basato sull’intelligenza artificiale, rappresenta una risposta rivoluzionaria a queste problematiche. Sfruttando i modelli di linguaggio di grandi dimensioni (LLM) e una logica a grafo diretta, Scrapegraph-ai semplifica la creazione di pipeline di scraping intelligenti per siti web e documenti locali, come XML, HTML, JSON e Markdown. Con una semplice configurazione, basta specificare le informazioni desiderate e Scrapegraph-ai si occupa di tutto il resto.

Google Cloud ha presentato una nuova piattaforma AI specificamente progettata per il settore automobilistico, promettendo un’esperienza di guida arricchita grazie alla capacità di mantenere conversazioni fluide e contestualizzate lungo tutto il viaggio. La prima vettura a integrare questa innovazione è la nuova Mercedes CLA, dotata del sistema operativo di nuova generazione MB.OS e di un aggiornato assistente virtuale MBUX.
Quando Mercedes ha svelato la CLA al CES 2024, non ha rivelato quale modello di Large Language Model (LLM) alimentasse il sistema, lasciando aperta la discussione sul contributo tecnologico sottostante. Nel frattempo, l’attuale sistema di assistente vocale MBUX, che gestiva circa 20 comandi attivabili con il comando “Hey Mercedes”, include ora risposte fornite da ChatGPT di OpenAI e Bing di Microsoft, pur non essendo ancora una piattaforma dialogica avanzata. Mercedes ha dichiarato di voler estendere il sistema aggiornato a “ulteriori modelli” che attualmente utilizzano l’assistente vocale di vecchia generazione, senza però specificare quali.

Illustrious, un modello di text-to-image basato su Stable Diffusion XL, ha rapidamente conquistato la comunità dell’arte AI. In soli tre mesi, Civitai, il più grande hub per modelli di arte AI, ha dovuto creare una categoria separata per gestire l’enorme ecosistema di risorse legate a Illustrious.
Il segreto del suo successo risiede in un ritorno alle basi con un tocco innovativo. Mentre modelli più recenti come SD 3.5 e Flux si affidano a descrizioni in linguaggio naturale estese, Onoma AI, gli sviluppatori di Illustrious, hanno adottato un approccio diverso, sfruttando i tag di Danbooru per aiutare il modello a comprendere i concetti senza dover reinventare complessi sistemi di didascalie.
I tag di Danbooru, utilizzati da anni come standard per la categorizzazione delle immagini tra gli appassionati di arte e anime, rappresentano elementi specifici come caratteristiche dei personaggi, abbigliamento, pose o sfondi. Questo consente un controllo preciso sulle immagini generate senza sprecare token preziosi in descrizioni lunghe. Come ha affermato un membro di Discord, “È come avere un artista che capisce esattamente cosa vuoi senza doverlo spiegare in paragrafi; devi solo conoscere i tag giusti.”
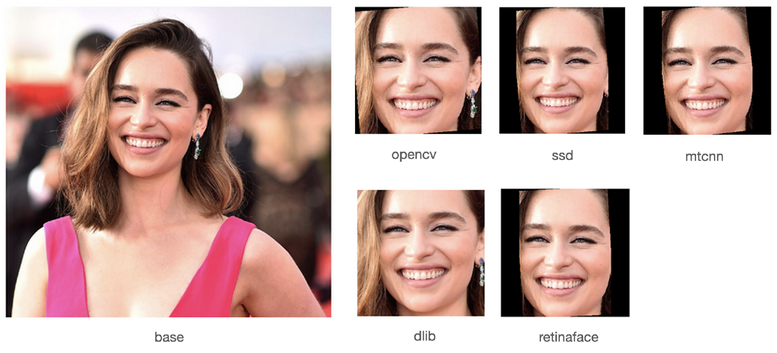
Il riconoscimento facciale ha visto un’accelerazione notevole negli ultimi anni, ma la sua implementazione rimane un campo tecnico complesso. I sviluppatori si trovano spesso di fronte a scelte difficili: le soluzioni disponibili sul mercato sono troppo elementari o richiedono costosi servizi basati su cloud. In aggiunta, la difficoltà nel trovare una soluzione locale efficace e a buon prezzo rappresenta un ulteriore ostacolo. Per i team di sviluppo e le aziende che vogliono integrare questa tecnologia nelle proprie soluzioni, la ricerca di un framework affidabile e conveniente è cruciale. Fortunatamente, DeepFace sta emergendo come un punto di svolta in questo scenario.

Il team non ha ancora rivelato una tempistica precisa per il lancio del nuovo generatore video, suggerendo che il progetto sia ancora in una fase iniziale di sviluppo. Al momento, gli sviluppatori stanno lavorando per “bilanciare velocità, costo e qualità dell’output,” come dichiarato nell’annuncio ufficiale.
Circa l’85% degli utenti preferisce le immagini create utilizzando il sistema di personalizzazione della piattaforma, che ora include mood board e profili multipli, secondo Midjourney. L’azienda prevede di ampliare ulteriormente queste funzionalità, combinando i mood board con capacità di riferimento stilistico.
La piattaforma introdurrà inoltre due modalità di generazione distinte: una opzione “in tempo reale” per risultati rapidi, simile alla funzione “imagine” di Meta, al doodle-to-image di Krea AI o al Realtime Canvas di Leonardo.
L’arte generata dall’intelligenza artificiale ha rivoluzionato il mondo della creatività, offrendo a tutti, dai principianti agli esperti, la possibilità di creare opere straordinarie. Tuttavia, nonostante il potenziale, molte persone sono frenate dalla complessità delle installazioni, dai requisiti tecnici e dai costi elevati associati a queste piattaforme. In molti casi, le piattaforme di intelligenza artificiale per la creazione artistica richiedono competenze avanzate, conoscenze tecniche specifiche e un grande impegno in fase di configurazione. Questo può scoraggiare anche i creatori più appassionati che si sentono sopraffatti dalla curva di apprendimento.

Immagina di creare un video animato di alta qualità partendo da una singola immagine di riferimento. Non è fantascienza: è HailuoAI. Questo innovativo modello di intelligenza artificiale sta rivoluzionando il panorama della generazione video, offrendo risultati accetabili con un approccio minimalista.
Negli ultimi anni, la tecnologia AI ha fatto passi da gigante nella creazione di contenuti multimediali. Strumenti come Stable Diffusion o DALL-E hanno già dimostrato come l’intelligenza artificiale possa trasformare semplici input testuali in immagini o video complessi. Ma HailuoAI si distingue per una caratteristica unica: riesce a generare video realistici e coerenti partendo da una sola immagine.
Questo approccio è un game-changer, soprattutto per chi lavora con risorse limitate. Dove altri strumenti richiedono molteplici reference o sequenze di immagini per catturare angolazioni, dettagli ed espressioni, HailuoAI punta tutto sull’efficienza, mantenendo comunque una qualità sorprendente.

Agent Laboratory è uno strumento all’avanguardia progettato per supportare i ricercatori nell’esecuzione delle loro idee di ricerca. Prende un concetto di ricerca creato dall’uomo e automatizza aspetti cruciali del processo, tra cui la revisione della letteratura, la sperimentazione e la scrittura dei report. Il sistema sfrutta agenti specializzati alimentati da modelli linguistici di grandi dimensioni (LLM) per assistere i ricercatori durante l’intero ciclo di vita della ricerca, dall’ideazione alla generazione del report finale.