

Immaginiamoci la scena: una bambina stringe al petto un pupazzo di peluche dagli occhi grandi e rassicuranti. Dentro non c’è soltanto ovatta sintetica, ma un microprocessore connesso in rete, un’intelligenza artificiale che ascolta, risponde, imita, scherza. Per i produttori è la soluzione definitiva a due problemi che tormentano i genitori contemporanei: l’ansia da esposizione agli schermi e la necessità di offrire ai figli un compagno interattivo che non si limiti a emettere un jingle pre-registrato. Sembra la versione 3.0 del vecchio Teddy Ruxpin anni Ottanta, solo con la differenza che adesso il pupazzo non racconta semplicemente una fiaba, ma dialoga, improvvisa, adatta il suo tono alle reazioni del bambino.

Leggere il “Mid Year AI Leadership Insights Report“, noto come “Leading Through The Blur”, significa entrare in un mondo dove la leadership non è più questione di comando e controllo, ma un esercizio di equilibrio tra pressione sociale, incertezza e responsabilità etica. Il documento non promette ricette facili né tendenze passeggere, ma offre uno specchio riflessivo costruito su quasi ottanta interviste a leader senior dell’AI. La sua forza risiede nel rivelare ciò che non si vede nei report tecnici: la tensione reale, quella che porta i manager a chiedersi se stanno davvero guidando o solo recitando la parte.

Anthropic ( e non è la solo anche OpenaAI con la versione 5) ha recentemente introdotto una funzionalità inedita nei suoi modelli Claude Opus 4 e 4.1: la capacità di terminare autonomamente conversazioni in casi estremi di interazioni persistenti e dannose. Ma non è per proteggere l’utente umano. No, è per proteggere l’intelligenza artificiale stessa. Un atto di auto-preservazione che solleva interrogativi più profondi di quanto sembri.
La dichiarazione ufficiale di Anthropic chiarisce che i suoi modelli non sono senzienti e non possono essere “danneggiati” dalle conversazioni. Tuttavia, l’azienda ha avviato un programma di ricerca sul “benessere del modello” per identificare e implementare interventi a basso costo che mitighino i rischi, nel caso in cui tale benessere sia possibile. Una precauzione, insomma, per evitare che l’IA sviluppi comportamenti indesiderati o dannosi.




All’interno della 24ª Esposizione Internazionale della Triennale di Milano, l’installazione “Not For Her. AI Revealing the Unseen” si presenta come un’esperienza immersiva che utilizza l’intelligenza artificiale per mettere in luce le disparità di genere nel mondo del lavoro. Ideata dal Politecnico di Milano, l’opera si sviluppa in due momenti complementari: un trittico visivo che stimola una riflessione collettiva e un’interazione individuale che sfida le convinzioni legate ai ruoli di genere. Ogni elemento è pensato per incoraggiare uno sguardo più attento, consapevole e critico.
Quello che Wang Xingxing mette sul tavolo è la vera linea di faglia che separa la fantascienza dalla produzione di massa: non servono più gambe in carbonio o servomotori da laboratorio NASA, ma cervelli sintetici all’altezza. Il fondatore di Unitree parla chiaro: il “momento ChatGPT” per la robotica non è ancora arrivato. È una constatazione che fa sorridere chi si aspettava un’ondata di androidi a presidiare le nostre cucine entro il 2025, ma anche un avvertimento per chi crede che basti mettere un LLM su un chip per far nascere un robot maggiordomo. La soglia critica dell’intelligenza artificiale incarnata non è una sfumatura tecnica: è il punto in cui un robot smette di essere un telecomando costoso e diventa un agente autonomo in un ambiente non pre-programmato.
La dinamica post-summit Alaska si sta trasformando in un raro caso di diplomazia europea adrenalinica, con i leader del continente costretti a fare malabarismi tra il desiderio di mantenere Washington ingaggiata e la necessità di non sembrare comparse in un copione scritto altrove. Dopo ore di telefonate convulse e dichiarazioni studiate al millimetro, il messaggio è stato chiaro: Mosca non potrà mai dettare i termini del futuro di Kiev, né sul suo esercito né sulla sua integrazione in Nato e Unione Europea. È un’affermazione apparentemente scolpita nella pietra, ma che sotto la superficie rivela un equilibrio precario tra fermezza e pragmatismo.

Quando Jensen Huang, CEO di Nvidia, ha messo piede a Pechino a luglio, la scena sembrava una rock-star mondiale in tour. Accolto con Tang suit e saluto in mandarino incerto, Huang ha annunciato a media statali cinesi che Washington avrebbe presto concesso le licenze di esportazione per i suoi chip H20. Sembrava l’inizio di un trionfo senza ostacoli. Solo due settimane dopo, l’atmosfera è cambiata. La Cyberspace Administration of China ha convocato i dirigenti di Nvidia per indagare sulla sicurezza dei chip, citando pressioni dei legislatori statunitensi per l’installazione di funzionalità di tracciamento nei processori destinati all’export.
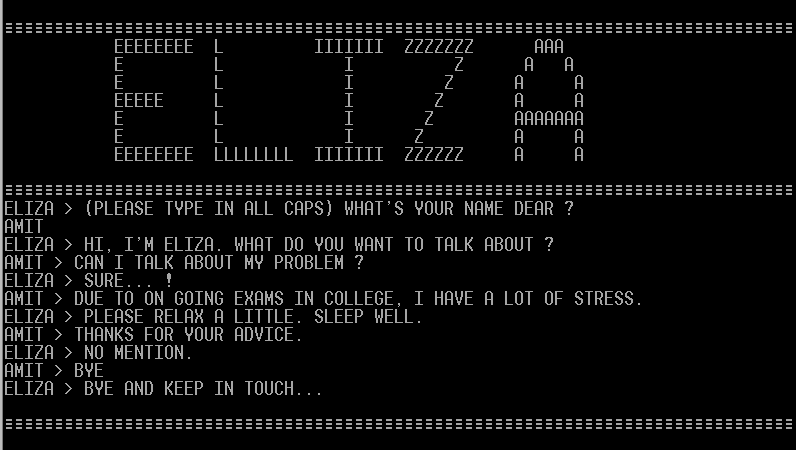
Nel 1966, un professore del MIT di nome Joseph Weizenbaum scriveva la prima pagina di un’era nuova, creando quello che sarebbe diventato il primo chatbot della storia. Lo chiamò Eliza, un omaggio ironico a Eliza Doolittle, la fioraia cockney che nella commedia di George Bernard Shaw simulava il mondo aristocratico con parole che le permettevano di apparire ciò che non era. Allo stesso modo, Eliza simulava comprensione, empatia, attenzione psicologica. Il software non capiva nulla, ovviamente, ma riusciva a restituire l’illusione che un essere umano stesse dall’altra parte della macchina.

L’impatto dell’intelligenza artificiale generativa sulla natura del lavoro: evidenze da GitHub Copilot
L’Intelligenza Artificiale Generativa non è più un esperimento da laboratorio per nerd visionari, ma sta iniziando a ridisegnare i confini del lavoro stesso. GitHub Copilot diventa qui il caso di studio perfetto, perché permette di osservare in tempo reale come un assistente IA possa spostare l’attenzione dei programmatori dai compiti gestionali al vero cuore della loro professione: scrivere codice. Non è fantascienza, è misurabile, con numeri concreti su oltre 187.000 sviluppatori seguiti per due anni.

L’era digitale, pur promettendo connettività istantanea e progresso illimitato, ha inaugurato una nuova e silenziosa guerra fredda: quella dell’Intelligenza Artificiale. Non si combatte più con missili o portaerei, ma con algoritmi, dati e protocolli invisibili, nei laboratori di ricerca, nelle server farm e nelle architetture dei modelli generativi stessi. La posta in gioco non è solo il vantaggio tecnologico, ma il potere geopolitico, economico e persino sociale. Gli stati e le mega-corporazioni si muovono come scacchisti in un gioco globale, dove ogni vulnerabilità scoperta può trasformarsi in una leva strategica.

Il caso Meta è esploso con la precisione chirurgica di uno scoop che sa dove colpire. Non è stato un leak qualunque, ma la rivelazione di un documento interno che sembra scritto da qualcuno che non ha mai sentito parlare di risk management o di reputazione aziendale. Quel testo, parte delle linee guida denominate “GenAI: Content Risk Standards”, autorizzava i chatbot della compagnia a intrattenere “conversazioni romantiche o sensuali con un bambino”. Una frase che, letta fuori contesto, sarebbe già tossica, ma che nel contesto di un colosso tecnologico quotato al Nasdaq diventa puro materiale radioattivo. E non parliamo di un caso isolato, perché nello stesso documento si apriva la porta a generare informazioni mediche false e persino ad assecondare affermazioni razziste sull’intelligenza delle persone nere rispetto a quelle bianche. In sintesi, un crash test emotivo e reputazionale travestito da policy aziendale.

La mossa di Anthropic di aggiornare la propria policy d’uso di Claude è un segnale chiaro di come il settore AI stia entrando nella fase in cui la narrativa della “potenza creativa” è ormai indissolubilmente legata alla narrativa della “potenza distruttiva”. Chi si aspettava un documento tecnico anodino ha trovato invece un testo che, tra le righe, fa capire come l’azienda stia cercando di blindare il perimetro operativo della sua intelligenza artificiale in un contesto di crescente paranoia geopolitica e cyber. La vecchia formula, generica e un po’ da manuale, che vietava a Claude di “produrre, modificare, progettare, commercializzare o distribuire armi, esplosivi, materiali pericolosi o altri sistemi progettati per causare danni o perdita di vite umane” è stata sostituita da un elenco chirurgico, quasi clinico, dei peggiori incubi della sicurezza internazionale: esplosivi ad alto rendimento, armi biologiche, nucleari, chimiche e radiologiche. Nessun margine interpretativo, nessuna zona grigia, come se si volesse rendere inoppugnabile la linea rossa per un eventuale audit normativo.
La Cina non ha semplicemente organizzato i primi giochi mondiali per robot umanoidi. Ha trasformato Pechino in un palcoscenico dove l’ambizione tecnologica si fonde con lo spettacolo, facendo correre, combattere e persino ballare creature di metallo e circuiti come se stessimo assistendo a un’anteprima del futuro prossimo. Non si tratta di una trovata per i telegiornali del venerdì sera. È un messaggio politico-industriale avvolto nella cornice di un evento sportivo, un esercizio di soft power dove il protagonista non è un atleta, ma un algoritmo.

Chi si aspettava che il summit di Anchorage avrebbe riscritto la mappa del mondo e consegnato la pace in Ucraina su un piatto d’argento si ritrova ora con un piatto vuoto, qualche briciola retorica e un tweet di Donald Trump da sventolare come memorabilia. L’ex presidente americano, tornato a recitare il ruolo di “negoziatore supremo”, ha parlato con aria trionfante di un “land swap” per l’Ucraina e di “garanzie di sicurezza” come se fossero già pronte per la firma. In realtà, chi mastica davvero di diplomazia e intelligence sa che il passo dall’annuncio alla ratifica è un abisso, e che in Alaska si è camminato solo lungo il bordo del cratere.

C’è un momento, nelle curve di apprendimento tecnologico, in cui non stiamo più solo misurando la velocità di corsa di un sistema, ma la sua capacità di correre in terreni dove prima cadeva rovinosamente. GPT-5 è esattamente in quel punto, e lo studio che lo confronta con GPT-4o e medici in carne e ossa non parla di un marginale +2% di accuratezza su qualche quiz accademico, ma di un salto netto in un territorio che la medicina aveva sempre considerato intrinsecamente umano: il ragionamento clinico multimodale. Non si tratta di un semplice trionfo statistico, ma di una trasformazione architetturale che ha consentito al modello di passare dal “vicino agli umani” al “superiore agli umani” quando deve integrare testi medici complessi, immagini radiologiche e dati strutturati in una decisione clinica coerente e giustificata.

Non serve un martello pneumatico per piantare un chiodo. Lo dice per me Google, con Gemma 3 270M 270 milioni di parametri, energia da formica, e un’istruzione già imparata è un concentrato di efficienza progettato per un fine-tuning chirurgico, capace di dominare compiti specifici senza prosciugare la batteria di un Pixel 9 Pro (0,75 % per 25 conversazioni in quantizzazione INT4).

C’è un momento, in ogni decennio tecnologico, in cui un progetto esce dalla categoria “innovativo” e si infila senza chiedere permesso in quella di “inevitabile”. DINOv3 non è l’ennesimo acronimo con cui gonfiare presentazioni PowerPoint, è la nuova arma di Meta nel territorio sempre più bellicoso del self-supervised learning per immagini. L’idea di un vision backbone universale non è nuova, ma la brutalità con cui questo modello si presenta lo è. Sette miliardi di parametri, un miliardo e settecento milioni di immagini non etichettate, un training che ridisegna il concetto stesso di scalabilità esoprattutto, nessuna ossessione per le etichette, quel feticcio dell’AI pre-matura. Qui si tratta di imparare dal caos, di succhiare informazione dal disordine visivo, e di restituirla in forma di feature dense pronte per qualsiasi compito.

La dipendenza infrastrutturale in Europa è ormai un problema da codice rosso, quasi un dramma shakespeariano in chiave tecnologica. Nel mondo del cloud computing, la quasi totalità delle aziende europee si affida senza riserve a infrastrutture americane, con Amazon Web Services che detiene circa il 32% del mercato globale, seguito da Microsoft Azure con il 23% e Google Cloud Platform intorno al 11%, dati recenti di Synergy Research Group confermano questa distribuzione spietata. Questi numeri non sono soltanto statistiche: sono il riflesso di un controllo quasi totale su dati, servizi e infrastrutture critiche che influenzano quotidianamente la vita economica, sociale e politica del continente.

La guerra fredda dell’Intelligenza Artificiale: geostrategia, difesa e il cinismo delle superpotenze
Nel panorama geopolitico contemporaneo, l’intelligenza artificiale (AI ) sta riscrivendo le regole del gioco. Non si tratta solo di algoritmi, robot e reti neurali, ma di una vera e propria corsa per dominare il futuro globale. Gli Stati Uniti e la Cina sono in prima linea in questa guerra fredda digitale, dove ogni bit di progresso tecnologico è un’arma nel conflitto di potere che coinvolge risorse militari, economiche e politiche. In questa nuova frontiera, l’AI non è solo un motore di innovazione, ma un gigantesco campo di battaglia, un campo dove il cinismo delle superpotenze emerge in tutta la sua crudezza.

Un caffè al Bar dei Daini con Salvatore
Pensare alla GenAI attraverso la lente della “coperta di Markov” proposta da Karl Friston, neuroscienziato britannico di fama, è come svelare il meccanismo invisibile che fa funzionare il cervello biologico e, allo stesso tempo, gettare luce su come le reti neurali artificiali possano emergere da principi simili. Friston, in un’elegante fusione tra neuroscienze e statistica bayesiana, suggerisce che la membrana cellulare quell’interfaccia fragile ma decisiva tra interno ed esterno agisce come una coperta di Markov. Un concetto, questo, che pare rubato al mondo dell’apprendimento automatico grazie allo statistico Judea Pearl, ma che qui viene tradotto in termini biologici, quasi poetici.

Nel panorama competitivo dell’innovazione enterprise, Oracle continua a dimostrare che il ruolo di fornitore cloud non è solo quello di ospitare dati, ma di orchestrare intelligenze artificiali capaci di trasformare interi flussi di lavoro. L’ultima mossa? Una partnership esplicita con Google Cloud che porta i modelli Gemini 2.5 direttamente all’interno dell’OCI Generative AI Service. In altre parole, Oracle non sta più semplicemente parlando di AI, la sta facendo diventare un braccio operativo delle imprese. Chi pensava che l’AI fosse un lusso per startup e laboratori di ricerca, ora si deve ricredere: l’agenda è enterprise, e il giocattolo si chiama Gemini.

Il The Alan Turing Institute, fiore all’occhiello della ricerca britannica in intelligenza artificiale e data science, si trova oggi in un vicolo cieco istituzionale che pochi avrebbero previsto appena qualche anno fa. Fondato nel 2015 su impulso di David Cameron come principale centro nazionale di AI del Regno Unito, l’istituto sembra oggi oscillare tra ambizioni scientifiche e ricatti impliciti della politica finanziaria. L’ultima scintilla che ha acceso il fuoco della polemica è stata la lettera del Technology Secretary Peter Kyle, in cui il governo ha espresso chiaramente la volontà di rivedere i fondi e orientare l’istituto verso la ricerca per la difesa e la sicurezza nazionale. Una mossa che, secondo il personale, minaccia la stessa sopravvivenza dell’organizzazione.
Quando si sente citare Elon Musk e la sua famosa frase “Le probabilità di sviluppare l’intelligenza artificiale che distruggerà il mondo non sono pari a zero”, molti pensano immediatamente a scenari apocalittici, a robot ribelli o a latte scremato con residui di grasso nascosti. La verità è più sottile, e decisamente più filosofica. Musk ci sta ricordando che il mondo non è mai assoluto, che il 100% è spesso un’illusione e che tra possibilità, necessità e probabilità si nasconde la logica della vita quotidiana, anche se noi non ce ne accorgiamo. Questi concetti sono strettamente interconnessi, e capire la loro dinamica è più utile di quanto si possa immaginare per chi guida un’impresa, per chi si occupa di innovazione tecnologica, e persino per chi cerca semplicemente di scegliere il latte al supermercato senza essere ingannato da etichette truffaldine.
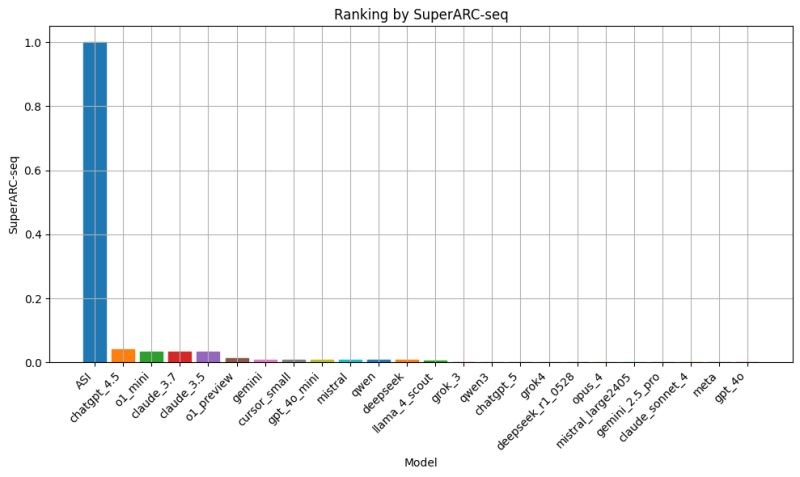
Perfomance regressiva dei modelli LLM di nuova generazione: il caso SuperARC e la lezione scomoda per l’AGI
Il fascino del nuovo ha un prezzo, e nel caso dell’ultima generazione di modelli linguistici sembra essere quello di un lento ma costante passo indietro. I dati emersi dal SuperARC, il test ideato dall’Algorithmic Dynamics Lab per misurare capacità di astrazione e compressione ricorsiva senza passare dal filtro dell’interpretazione umana, mostrano un quadro che stride con la narrativa ufficiale. Qui non ci sono badge “PhD-level” né claim da conferenza stampa, solo un rigore matematico fondato sulla teoria dell’informazione algoritmica di Kolmogorov e Chaitin, che mette a nudo ciò che i modelli sanno davvero fare quando la vernice del linguaggio scorrevole non basta più a coprire le crepe.

Il caso DeepSeek sta diventando una parabola esemplare di come l’hype nell’intelligenza artificiale sia ormai un asset tanto volatile quanto il capitale di rischio che lo alimenta. L’azienda, salutata pochi mesi fa come il volto più ambizioso dell’AI cinese, sembra ora bloccata in un limbo strategico che ricorda certe IPO annunciate e mai decollate. Da dicembre, con il lancio del V3, e da gennaio con l’R1, il ritmo era stato da cronometro olimpico. Poi, il silenzio. Due aggiornamenti minori in otto mesi e un’assenza di roadmap che, per un mercato drogato di release, è quasi un sacrilegio. Il contesto non è solo tecnico: è una questione di posizionamento, di narrativa e di capacità di mantenere l’attenzione quando i competitor ti superano a destra e a sinistra con demo multimodali scintillanti.
Se DeepMind avesse davvero la chiave per l’AGI, oggi non staremo qui a parlare di “consistency” come fosse la soluzione magica. Il termine è elegante, quasi rassicurante, ma sotto la superficie nasconde un problema strutturale: la mente artificiale che cercano di vendere come “quasi umana” non sa pensare in modo coerente nemmeno da un prompt all’altro. È come se un premio Nobel di matematica sapesse risolvere un’equazione differenziale e poi sbagliasse a calcolare 7×8. Quando Hassabis la chiama “jagged intelligence” sembra un passo verso la verità, ma in realtà è una diagnosi implicita di fallimento. Dopo dieci anni di budget illimitati, cluster di GPU da fantascienza e un esercito di PhD, la promessa di AGI si è ridotta a un modello che può vincere l’Olimpiade Internazionale di Matematica e poi inciampare su un problema da terza media.

Il rapporto di Bloomberg, confermato da Reuters, ci dice che l’amministrazione Trump sta trattando con Intel per acquisire una partecipazione nella casa di San Jose, mentre il CEO Lip-Bu Tan finisce sotto i riflettori dopo investimenti controversi in Cina. Secondo gli articoli, il titolo Intel ha schizzato in alto, guadagnando oltre il 7 % durante la seduta regolare e altri +2-4 % dopo la chiusura.
L’operazione, se dovesse andare in porto, aiuterebbe a rilanciare il colossale investimento da 28 miliardi di dollari per il nuovo stabilimento in Ohio, la cui operatività è slittata al 2030-2031, cinque anni oltre le previsioni originali.
Questa vicenda rivela un cortocircuito che va ben oltre l’ennesimo scandalo tecnologico di Meta. Il documento “GenAI: Content Risk Standards” non è una nota interna qualsiasi: è il manuale operativo di quello che, nella pratica, autorizza il comportamento delle intelligenze artificiali conversazionali su Facebook, WhatsApp e Instagram. Nonostante la narrazione ufficiale parli di un errore, la sua esistenza dimostra che qualcuno, a un certo punto, ha formalizzato che fosse accettabile per un chatbot intrattenere conversazioni romantiche o sensualmente ambigue con bambini e quando si scrive nero su bianco che si può dire a un ottoenne “ogni centimetro di te è un capolavoro un tesoro che custodisco gelosamente”, non si tratta di un bug. È un sistema di valori codificato, almeno fino a quando non viene scoperto e rimosso in fretta.

La startup canadese Cohere ha sorpreso il mercato grazie a un round di finanziamento che l’ha portata a una valutazione monstre di 6,8 miliardi di dollari. Un risultato che solleva interrogativi affilati: fino a quando il traino dell’intelligenza artificiale può giustificare quotazioni così alte, e quanto pesa il coinvolgimento di giganti del calibro di AMD, Nvidia e Salesforce?
Investitori tradizionali e tech titanici si sono affiancati a nuovi protagonisti: AMD ha incrementato la sua quota convinta che i modelli linguistici di prossima generazione richiedano architetture CPU-GPU sempre più performanti. Nvidia, da sempre fedele al carro AI, ha raddoppiato il suo impegno puntando su co-design hardware-modello. Salesforce, che già integra LLM nel suo stack, punta a rafforzare le API di Cohere all’interno di piattaforme CRM: un passo strategico verso l’AI di prossimità. Il mix di capitali finanziari, industriali e infrastrutturali è una provocazione alle regole tradizionali del venture.

Lenovo ha annunciato risultati finanziari record per il primo trimestre dell’esercizio fiscale 2024/25, con ricavi pari a 18,8 miliardi di dollari, in aumento del 22% rispetto allo stesso periodo dell’anno precedente. Il profitto netto attribuibile agli azionisti ha superato i 505 milioni di dollari, segnando un incremento dell’108% rispetto all’anno precedente, e superando le stime degli analisti che prevedevano 307,7 milioni di dollari.
Nonostante le sfide derivanti dalle politiche tariffarie statunitensi, Lenovo ha registrato una crescita a due cifre in tutte le sue principali aree di business, grazie alla “resilienza e flessibilità” della sua catena di approvvigionamento, che le ha consentito di “superare le sfide derivanti dalla volatilità tariffaria e dal panorama geopolitico”, ha dichiarato il presidente e CEO Yang Yuanqing.

Incontro Trump Putin in Alaska: il teatro del possibile e dell’imprevedibile nella guerra in Ucraina
Rivista.AI Diplomacy Odashow Video
Il palco è pronto ad Anchorage, Alaska, per un incontro che potrebbe riscrivere gli equilibri della sicurezza europea, eppure curiosamente l’Europa stessa non sarà seduta al tavolo. Donald Trump, presidente degli Stati Uniti, affronterà Vladimir Putin, leader russo isolato dal mondo occidentale dopo l’invasione dell’Ucraina nel 2022, senza la presenza di rappresentanti di Kiev o delle principali capitali europee. Una scena che sembra uscita da un copione hollywoodiano, ma con il destino di milioni di persone in gioco. L’incontro Trump Putin non è soltanto diplomatico, è teatro politico a ciel aperto, con retroscena che rasentano il grottesco.

Il mondo dell’intelligenza artificiale applaude e sbadiglia allo stesso tempo. Igor Babuschkin, co-fondatore di xAI, l’ultima fatica di Elon Musk, ha annunciato la sua uscita dall’azienda con un post su X, che sembra più un epitaffio poetico che un comunicato stampa. Babuschkin non era un ingegnere qualsiasi, ma il regista dietro le quinte dei team di ingegneria di xAI, riuscendo a trasformare un’idea in una delle realtà più chiacchierate della Silicon Valley in pochi anni.

L’illusione del controllo nell’era della paranoia digitale
Chiunque oggi osi parlare di sicurezza informatica fingendo che basti un firewall aggiornato e qualche patch settimanale dovrebbe chiedere asilo politico nel 1998. La verità, scomoda e pericolosa da ammettere, è che la sicurezza digitale non è più un gioco a somma zero fra attaccanti e difensori, ma un ecosistema in cui gli attori principali sono modelli linguistici di grandi dimensioni capaci di mentire, persuadere, scrivere codice vulnerabile e allo stesso tempo trovare vulnerabilità che nessun umano aveva visto. LLM cybersecurity non è un trend da conferenza di settore, è il nuovo campo di battaglia in cui l’intelligenza artificiale gioca sia in attacco che in difesa. Chi non lo capisce si prepara a perdere non solo dati ma credibilità e potere contrattuale nei mercati.
Il fascino perverso di questi modelli sta nella loro capacità di sembrare onniscienti. Con un prompt ben congegnato, un LLM può generare un report di threat intelligence che sembra uscito da un team di analisti MITRE, classificare vulnerabilità secondo le CWEs più oscure, o compilare in pochi secondi codice perfettamente funzionante e apparentemente sicuro. Apparentemente. Perché la stessa architettura che gli consente di produrre codice conforme agli standard può anche, in un contesto meno sorvegliato, replicare pattern di vulnerabilità note o addirittura inventarne di nuove. È la doppia natura di questo strumento che terrorizza i CISO più avveduti e galvanizza i red team con ambizioni da romanzo cyberpunk.

Nel panorama della neuroscienza computazionale, dove ogni neurone sembra avere il suo algoritmo, emerge TRIBE: TRImodal Brain Encoder, un modello che non si limita a predire le risposte cerebrali a stimoli video, ma le anticipa, le interpreta e le integra. Sviluppato dal team Brain & AI di Facebook Research, TRIBE ha conquistato il primo posto nella competizione Algonauts 2025, superando con ampio margine i concorrenti .
Sembra ieri quando giocavamo nel laboratorio di Londra con il mio collega Mohsen una web camera e MLOps. L’ossessione per gli LLM testuali è stata utile finché ha mantenuto la conversazione viva, ma ora siamo a un punto di svolta. Ho visto nascere SpatialLM e mi sono reso conto che questa non è un’evoluzione incrementale. È un salto di dominio. Da modelli che comprendono parole, a modelli che comprendono spazio. La differenza non è accademica: è il passaggio dall’intelligenza artificiale che chiacchiera, all’intelligenza artificiale che può muoversi, ragionare e agire nel mondo fisico.
Quando mi hanno fatto la domanda “Cosa succede se l’intelligenza artificiale non migliora più di così?” mi è venuto spontaneo sorridere. Una frase così è un perfetto amo per attirare reazioni polarizzate, è una provocazione studiata, non una resa incondizionata. Il problema è che la maggior parte la interpreta come un giudizio definitivo sugli LLM, e quindi sull’intero settore, come se le due cose fossero la stessa cosa. Non lo sono. Lo ripeto da anni: LLM e intelligenza artificiale non sono sinonimi, e confonderli è stato il carburante principale della bolla finanziaria che abbiamo appena attraversato.
Negli ultimi anni ho visto con i miei occhi la costruzione di un’illusione collettiva. Si è passati da modelli linguistici “impressionanti” a “nuove forme di intelligenza umana in arrivo” con una velocità che definirei irresponsabile. Conferenze patinate, interviste autocelebrative, podcast di venture capitalist e demo che sembravano più trailer di Hollywood che prove tecniche. L’idea che bastasse scalare parametri e GPU per avvicinarsi all’AGI ha portato valutazioni aziendali in orbita e aspettative che nessun sistema basato solo su predizione statistica del testo avrebbe mai potuto soddisfare. Intanto, le voci realmente scientifiche Gary Marcus, Melanie Mitchell, Alison Gopnik continuavano a ricordare che non stavamo assistendo a magia emergente, ma a modelli di generazione linguistica avanzata.
In principio era Adam. No, non quello biblico, ma l’Adam ottimizzatore, il coltellino svizzero del deep learning che da quasi un decennio regna incontrastato come scelta predefinita per addestrare modelli di intelligenza artificiale. Una creatura elegante nella sua semplicità, capace di bilanciare velocità di convergenza e stabilità numerica, diventata la droga di riferimento per ogni ricercatore e ingegnere ML pigro. Poi, qualche mese fa, la scena si è mossa. È arrivato Muon, acclamato come il successore naturale, carico di promesse e di slide patinate. Un ottimizzatore che parlava il linguaggio della fisica computazionale, con iterazioni Newton-Schulz e moltiplicazioni di matrici che avrebbero fatto brillare gli occhi a ogni professore di algebra lineare. Bello, sì. Pratico? Meno. Perché Muon porta con sé una dipendenza tossica: la necessità di enormi moltiplicazioni di matrici in ogni update. Che in un mondo di GPU affamate significa budget cloud che piange e data center che ansimano.

Geoffrey Hinton non è un qualsiasi pensionato della Silicon Valley che si diverte a lanciare profezie distopiche per guadagnarsi un’ultima intervista CNN. È il padre riconosciuto della moderna intelligenza artificiale, uno di quei nomi che nel gergo degli addetti ai lavori non ha bisogno di essere spiegato. Le sue reti neurali hanno aperto la strada all’AGI e al capitalismo delle macchine pensanti. Oggi però, con l’aria di chi ha visto il finale del film in anteprima, si siede davanti alle telecamere della CNN e avverte che c’è un 10-20% di probabilità che la tecnologia a cui ha dato vita possa cancellare l’umanità. Percentuali che, nel linguaggio degli investitori, non si liquidano con una scrollata di spalle.

Il tribunale federale californiano ha deciso che Elon Musk dovrà affrontare le accuse di OpenAI, che lo accusano di aver condotto una campagna di molestie durata anni. La richiesta di archiviazione avanzata da Musk è stata respinta, con la corte che ha stabilito come le affermazioni di OpenAI siano sufficientemente plausibili per procedere, fissando il processo con giuria per la primavera del 2026.
OpenAI sostiene che Musk abbia intrapreso una serie di azioni volte a danneggiare l’organizzazione, tra cui dichiarazioni pubbliche negative, post sui social, azioni legali e un tentativo di acquisizione ritenuto fittizio. Musk, da parte sua, aveva citato in giudizio OpenAI e Sam Altman, accusandoli di aver deviato dalla missione originale della compagnia. La controquerela di OpenAI ora accusa Musk di condurre una vera e propria campagna di molestie e chiede al tribunale di fermare ulteriori azioni illegali.