

Una sentenza californiana scuote il mondo dell’intelligenza artificiale con un impatto che va ben oltre la semplice disputa giudiziaria. Il tribunale ha autorizzato una class action contro Anthropic, startup sostenuta da Amazon e principale rivale di OpenAI nel settore chatbot, accusata di aver scaricato milioni di opere protette da copyright da biblioteche di materiale pirata, un’operazione paragonata a una “Napsterizzazione” digitale. La portata dell’accusa non è circoscritta a pochi autori: coinvolge tutti gli scrittori statunitensi le cui opere sarebbero state usate senza permesso, facendo traballare le fondamenta stesse di come oggi si costruiscono le intelligenze artificiali.

La corsa agli strumenti di coding AI non è più un gioco da giovani startup sperimentali, ma una giungla dove si combatte con armi pesanti. Cursor, il nome che fino a ieri poteva sembrare un outsider in questo ecosistema, sta facendo mosse da vero heavy player per scavalcare i colossi come Microsoft e il suo GitHub Copilot. La strategia? Non solo innovazione tecnologica pura, ma acquisizioni mirate e un’attenzione ossessiva alla rapidità di scalata sul mercato enterprise.

C’è qualcosa di profondamente ironico nel vedere Meta, l’impero costruito da Zuckerberg sull’ossessione del “connettere il mondo”, trasformarsi nel simbolo più perfetto del patto faustiano tra potere e informazione. Cambridge Analytica non è stata solo uno scandalo, è stata la rivelazione brutale di ciò che molti sospettavano e pochi avevano il coraggio di dire: il vero prodotto non è mai stata la pubblicità, né la piattaforma sociale, ma l’essere umano stesso, venduto in blocchi di bit al miglior offerente. Non è stata una falla di sicurezza, ma una strategia tollerata, alimentata e monetizzata e qui il paradosso: la gente si scandalizzò non per l’uso dei dati, ma per la spudorata sincerità con cui quel meccanismo venne alla luce.

Amazon sta ammassando emissioni come fossero pacchi sotto Natale, con un bel +6 % nel 2024 rispetto all’anno precedente, toccando 68,25 milioni di tonnellate di CO₂eq, secondo il report ufficiale pubblicato il 17 luglio 2025 . È un’inversione di tendenza, dopo due anni di cali, che dimostra quanto il boom dell’intelligenza artificiale sia stato finora un match vinto dal Pianeta ma perso dall’ambizione ambientale.
La crescita delle emissioni coinvolge tutto lo spettro Scope 1, 2 e 3. Le emissioni dirette (Scope 1) – principalmente dovute alla logistica – sono cresciute del 6 %, per via di forniture in ritardo di veicoli elettrici e carburanti a bassa emissione. Quelle indirette da elettricità acquistata (Scope 2) sono salite dell’1 %, causate dall’enorme richiesta energetica dei data center che alimentano le operazioni AI. Infine, le emissioni indirette da terze parti (Scope 3) sono aumentate anch’esse del 6 %, spinte dalla costruzione di data center e dai partner logistici.
Gitlab prova a ridefinire lo sviluppo software con l’arma definitiva dell’intelligenza artificiale e, almeno sulla carta, sembra aver capito che il vero vantaggio competitivo non è il solito chatbot travestito da assistente, ma la capacità di orchestrare un ecosistema di agenti intelligenti in modo asincrono e contestuale.
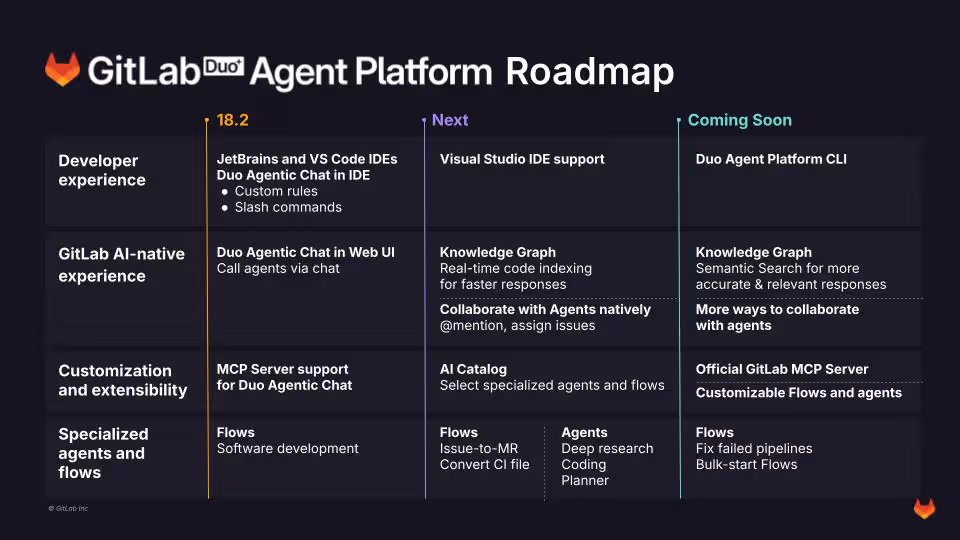
La nuova creatura si chiama Gitlab Duo Agent Platform, in beta pubblica per i clienti Premium e Ultimate, ed è il classico esperimento che separa i pionieri dai follower timorosi.

Sembra quasi una barzelletta, ma la realtà è più intrigante di qualsiasi sceneggiatura hollywoodiana. Una commissione di saggi, vestita di buonismo tecnologico, ha deciso che OpenAI non basta solo a costruire chatbot evoluti e algoritmi sofisticati, serve anche un fondo d’emergenza per “salvare il mondo”. Ovvero per finanziare organizzazioni civiche impegnate in scienze della salute, ambiente e, ovviamente, la lotta contro la disinformazione dilagante provocata proprio dall’intelligenza artificiale. La cosa assume toni quasi ironici se si pensa che proprio la stessa AI, creata da OpenAI, sia uno degli strumenti più affilati in mano alla disinformazione digitale.

L’arte della diplomazia tecnologica si sta riscrivendo sotto i nostri occhi con un sipario fatto di chip, politica e promesse digitali. Wang Wentao, ministro del commercio cinese, e Jensen Huang, il CEO taiwanese-americano di Nvidia, hanno stretto una mano che vale più di un semplice accordo commerciale: è una sfida lanciata a un futuro in cui l’intelligenza artificiale sarà il campo di battaglia più ambito e controverso. Se vi aspettavate uno scontro frontale, vi sbagliate: l’incontro ha mostrato un pragmatismo raro, in un mondo diviso tra sanzioni e sospetti, tra protezionismo e apertura di mercato.

Donald Trump, l’uomo che ha trasformato la politica americana in uno show senza pause, torna a far parlare di sé con una nuova impresa destinata a infiammare dibattiti globali: la sua candidatura al Nobel per la pace. Mentre il mondo fatica a tenere il passo con i suoi tweet incendiari e le politiche “America first”, ecco che il tycoon si lancia in una corsa per il premio più prestigioso al mondo, trasformando un’istituzione storica in un campo di battaglia politico. Il risultato? Un mix di ironia, scetticismo e propaganda da manuale.

Netflix ha appena fatto qualcosa che Hollywood finge ancora di non capire davvero. Ha usato l’intelligenza artificiale generativa per produrre un pezzo di cinema vero, non una demo da laboratorio. Ted Sarandos l’ha detto senza giri di parole, con quel tono da manager che sa di stare tracciando una linea nella sabbia. “Il primissimo footage finale creato con GenAI su schermo”. Il contesto? El Eternauta, serie argentina che a questo punto è più interessante per la sua pipeline produttiva che per la trama. La scena di un palazzo che crolla a Buenos Aires è stata completata dieci volte più velocemente e con un budget che, parole sue, “non sarebbe stato nemmeno pensabile con i normali effetti visivi”.
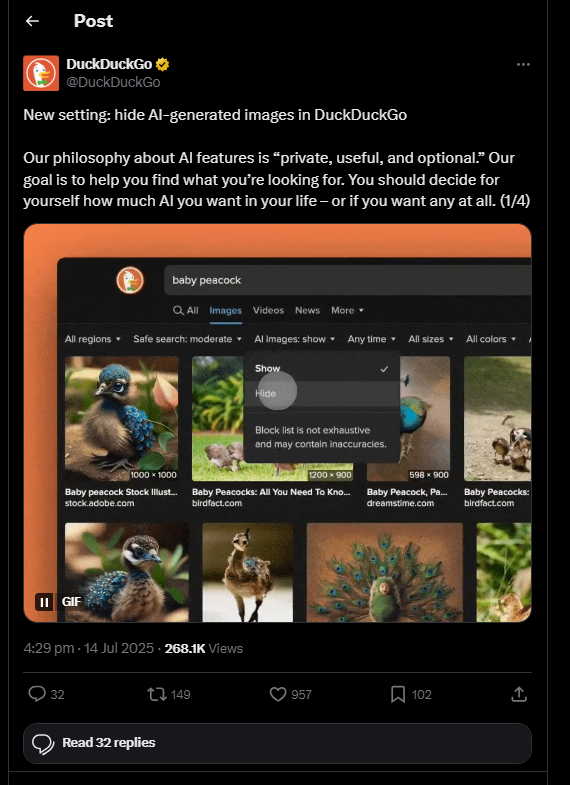
C’è qualcosa di irresistibilmente ironico nel fatto che una delle bandiere della privacy online debba oggi vendere l’illusione di un mondo più pulito semplicemente aggiungendo un interruttore “show” e “hide” alle sue ricerche immagini. DuckDuckGo, che per anni ha costruito la propria narrativa su un web libero dal tracciamento aggressivo, ora si trova a fare i conti con l’altra grande ossessione contemporanea, l’invasione dell’intelligenza artificiale generativa, quell’oceano di “slop” digitale che sta trasformando Internet in un mercato delle pulci di contenuti sintetici. Non è un caso che la mossa arrivi dopo un’ondata di proteste di utenti che, cito, non riescono più a trovare quello che cercano perché soffocati da immagini palesemente artificiali. Il nuovo filtro, una sorta di scialuppa di salvataggio nell’oceano del generative spam, si attiva dal tab Immagini con un comodo menu a tendina battezzato con un geniale quanto banale “AI images”. Si può scegliere se vedere o non vedere questo tipo di contenuti, e persino bloccarli globalmente nelle impostazioni. Come dire, libertà di scegliere, ma entro i confini disegnati da un algoritmo.
Il futuro della navigazione web ha un nome scintillante e presuntuoso, “Comet”, e un’ambizione che puzza di hybris: farci dimenticare Chrome, Google e quella vecchia abitudine di cercare le cose da soli. Perplexity ha lanciato il suo browser AI come se fosse l’arma finale nella guerra dell’intelligenza artificiale applicata alla navigazione, promettendo non solo di rispondere alle nostre domande ma di muoversi al posto nostro, chiudere schede, comprare su Amazon e persino accettare inviti su LinkedIn. Un assistente che non ti consiglia, ma agisce. Il sogno di chi detesta cliccare e il peggior incubo di chi ha ancora il vizio del controllo.
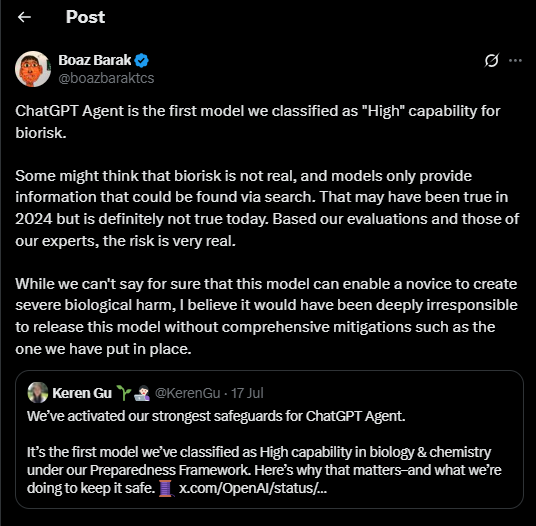
Ieri OpenAI ha fatto scivolare un sasso bello pesante nello stagno già turbolento dell’intelligenza artificiale. ChatGPT Agent è arrivato con il fascino tipico dei prodotti che promettono di “fare il lavoro sporco al posto tuo”, ma stavolta c’è una differenza sottile e inquietante. È lo stesso OpenAI a dirlo, quasi con un certo orgoglio malcelato: questo sistema potrebbe “aiutare significativamente un principiante a provocare gravi danni biologici”. Perfetto, direbbe un cinico, finalmente un assistente virtuale che rende inutile anche l’incapacità umana di autodistruggersi. Naturalmente, ci dicono, non è questo lo scopo principale. Certo, come no.

Il botto arriva oggi, 18 luglio 2025: Meta, con il suo diplomatico ma tagliente Chief Global Affairs Officer, Joel Kaplan, annuncia che “l’Europa sta imboccando la strada sbagliata nell’IA” e rifiuta di firmare il Code of Practice per AI general‑purpose voluto dall’UE, un framework volontario pensato come ponte verso il compliance all’AI Act . Una mossa che stride con la retorica di “responsabilità e trasparenza” tanto sbandierata anche dalla stessa commissione europea.
La dichiarazione è piuttosto netta: il Code introduce “insicurezze legali” e richieste che superano di gran lunga quanto previsto dall’AI Act . In soldoni, Meta afferma che queste maglie regolamentari da “bilancio di legge” minacciano di soffocare lo sviluppo e l’adozione di modelli AI d’avanguardia in Europa, penalizzando aziende europee pronte a costruirci sopra il proprio business.
Hinton colpisce ancora, e questa volta lo fa con la grazia di un professore che sa perfettamente che il suo paradosso è una bomba a orologeria intellettuale. “Perché un cumulo di compost è come una bomba atomica?”. È la tipica domanda che un CEO vorrebbe fare a un candidato in un colloquio: non importa tanto la risposta, quanto la capacità di riconfigurare il pensiero. E un vecchio GPT, con pesi congelati e zero accesso al web, l’ha fatto. Non ha “cercato”, non ha “copiato”, ha associato. Catene di reazioni, energia, emergenza di comportamenti complessi. Un colpo da maestro, perché dimostra esattamente ciò che i detrattori degli LLM non vogliono ammettere: la creatività, nella sua forma più cruda, è l’arte di connettere punti che prima sembravano scollegati.

La notizia è di quelle che fanno saltare la sedia: la Casa Bianca starebbe preparando un ordine esecutivo per colpire le cosiddette “AI woke”, imponendo che tutti i modelli di intelligenza artificiale utilizzati da aziende con contratti federali siano “politicamente neutrali e privi di bias”. L’indiscrezione arriva dal Wall Street Journal e ha già innescato un terremoto semantico a Silicon Valley.
La parola chiave, quella su cui si costruisce la narrativa, è “neutralità”. Ma in un’epoca in cui anche gli algoritmi hanno identità di genere e i modelli linguistici si scusano preventivamente per eventuali offese culturali, chiedere neutralità è come pretendere che un algoritmo smetta di riflettere il mondo che lo ha addestrato.
Chi continua a sprecare fiato parlando di “apocalisse AGI” dovrebbe fare un bagno di realtà. Il problema immediato non è l’ipotetico cervello digitale che un giorno deciderà di schiacciarci. Il problema, adesso, è che l’intelligenza artificiale sta rendendo i cyberattacchi economici, scalabili e automatizzati. Sta ribaltando le regole del gioco non con colpi di genio alla Matrix, ma abbassando drasticamente la barriera d’ingresso per chiunque voglia fare danni. Questo è il messaggio che DeepMind ha messo nero su bianco in uno dei documenti più inquietanti e lucidi dell’anno. Ed è esattamente il tipo di verità che il 90% dei board preferisce ignorare finché non è troppo tardi.

Chi pensa che i chatbot generativi siano solo giocattoli digitali dovrebbe rimettersi a vendere corsi di leadership su LinkedIn e lasciare il tavolo a chi prende decisioni che contano davvero. Il problema non è l’intelligenza artificiale in sé, ma il modo in cui le aziende stanno divorando contenuti generati da LLM come se fossero verità rivelate. Benvenuti nel regno del “botshit”, la miscela perfetta di allucinazioni dei chatbot e ignoranza manageriale, che trasforma dati spazzatura in decisioni disastrose.
Botshit è un termine crudo, eppure elegante nella sua brutalità concettuale. Non parliamo di bug, ma di un veleno epistemico che nasce quando i modelli linguistici generano risposte plausibili ma false, e qualche manager annoiato le usa senza pensarci due volte. È la degenerazione perfetta del business moderno: ridurre a zero il costo del “bullshit” umano grazie alla velocità della macchina, ma senza ridurre di un centesimo il costo della verità.

Il mito della segretaria/o virtuale onnisciente non è più fantascienza da film Marvel, è la nuova ossessione di Silicon Valley. OpenAI ha appena buttato il sasso nello stagno con ChatGPT Agent, l’ultimo gioiello del suo arsenale, presentato con la solita promessa di cambiare la nostra vita lavorativa e personale. La narrativa è impeccabile: un assistente che non si limita a chiacchierare, ma usa un “computer virtuale” per eseguire compiti complessi, orchestrando strumenti multipli come un direttore d’orchestra. Sembra la consacrazione definitiva del concetto di AI agent, quella buzzword che gli investitori pronunciano con la stessa devozione con cui un broker anni Ottanta diceva “Wall Street”.

È raro che un organo amministrativo dia una scossa vera al dibattito giuridico sull’intelligenza artificiale. La sentenza del Consiglio di Stato pubblicata il 6 giugno 2025 rappresenta una pietra miliare di questa rivoluzione che piaccia o no sta riscrivendo le regole del gioco. Un passaggio cruciale viene dalla riaffermazione, quasi mantra, che l’uso di sistemi automatizzati da parte degli enti pubblici deve convivere senza sconti con la tutela dei diritti fondamentali dei cittadini. Tradotto: sì alle automazioni, no al sopruso algoritmico.

La scena è questa. Non stiamo più parlando con un chatbot che ti suggerisce le risposte o ti offre qualche slide da presentazione mediocre. Adesso siamo davanti a un mostro elegante che opera su un computer virtuale tutto suo, naviga, compila, scrive, compra e, soprattutto, decide quale strumento usare per ottenere il massimo risultato. Si chiama ChatGPT Agent e non è un aggiornamento carino per appassionati di IA, è il passaggio brutale dall’intelligenza passiva a quella operativa. Una transizione che segna il confine tra chi governa il gioco e chi verrà semplicemente gestito da chi sa orchestrare questi nuovi strumenti. (guarda il Video)

In un mondo dove le tecnologie emergenti non sono più semplici supporti ma veri e propri protagonisti, l’intelligenza artificiale si affaccia con prepotenza al centro del dibattito economico globale, in particolare riguardo alla doppia missione della Federal Reserve: massima occupazione e stabilità dei prezzi. Lisa Cook, governatore della Fed, ha riassunto con una chiarezza chirurgica la sfida che ci attende. Da una parte, l’AI promette di rivoluzionare il mercato del lavoro, potenziando la produttività dei lavoratori ma allo stesso tempo alterando radicalmente la composizione stessa delle mansioni. Dall’altra, l’effetto sui prezzi non è affatto scontato, oscillando tra una possibile riduzione delle pressioni inflazionistiche grazie alla maggiore efficienza e l’aumento dei costi derivante dall’investimento massiccio in nuove tecnologie.
È quasi comico, se ci pensi. Adobe, la regina dell’editing tradizionale, ora ti chiede di fare “clip clop” davanti al microfono per generare l’effetto sonoro perfetto di un cavallo che cammina. Benvenuti nell’era in cui il futuro del filmmaking si gioca a colpi di onomatopee. Certo, dietro questa trovata apparentemente ludica si nasconde un progetto molto più ambizioso e, come sempre quando Adobe muove le pedine, non è solo una questione di creatività, ma di controllo del mercato. La nuova funzione Generate Sound Effects di Firefly, lanciata in beta, è il passo più sfacciato nella direzione di un ecosistema chiuso, raffinato, che punta a fagocitare ogni frammento del processo creativo audiovisivo. Non è più solo un text prompt, non basta più digitare “hooves on concrete” e sperare che l’algoritmo faccia il resto. Devi interagire, devi mettere la tua voce, il tuo ritmo, come se Adobe stesse dicendo al creator “sei tu il vero strumento musicale, ma io sono il direttore d’orchestra”.

Lovable la startup che scrive codice con l’aria da rockstar e spaventa i vecchi giganti del software
C’è qualcosa di irresistibile quando una piccola banda di 45 persone riesce a mettere in crisi l’intero ecosistema dei colossi del software. Lovable, sì, proprio quel nome che sembra uscito da una campagna di marketing per adolescenti, ha fatto quello che nessuno aveva il coraggio di ammettere pubblicamente: ha trasformato la creazione di app e siti web in un esercizio di conversazione naturale, annientando il mito del programmatore-sacerdote che scrive righe di codice come se fossero formule arcane. Lo ha fatto con uno stile da “fast-growing Swedish AI vibe coding startup”, perché in fondo anche la geografia conta nel marketing delle illusioni tecnologiche.

Jensen Huang non è un tipo che spreca parole. Quando afferma che l’impatto dell’intelligenza artificiale applicata alla scienza sarà immensamente più grande di quello sui compiti umani, non sta lanciando uno slogan motivazionale, sta mettendo in chiaro chi guiderà la prossima corsa all’oro tecnologica. Gli esseri umani hanno creato linguaggi per descrivere se stessi, e l’AI li ha già decifrati con una facilità imbarazzante. Ma la biologia non parla la nostra lingua, parla quella di miliardi di anni di evoluzione cieca e caotica. Ed è proprio qui che Huang, con il suo classico sorriso da visionario pragmatico, ci fa notare che stiamo entrando in un territorio dove l’AI dovrà imparare non a tradurre, ma a interpretare il significato della vita stessa.

Quando il più grande produttore di semiconduttori al mondo decide di alzare le previsioni di crescita, gli investitori non chiedono spiegazioni, applaudono. TSMC ora parla di un incremento del 30 per cento dei ricavi in dollari per il 2025, un bel salto rispetto alle stime precedenti. È l’ennesima conferma che l’ossessione globale per l’intelligenza artificiale non si sta sgonfiando, anzi continua a drogare i bilanci di chi fabbrica i mattoni su cui si costruisce questa nuova economia cognitiva. Perché è esattamente questo che sono i chip di TSMC, i neuroni artificiali senza i quali nessun modello generativo esisterebbe. Meta, Google, Amazon, tutti continuano a bruciare miliardi per riempire data center, e Nasdaq festeggia come un bambino a Natale.

Il consumo energetico dei data center crescerà in modo vertiginoso: già oggi sono circa 55 GW, ma entro il 2027 si prevede un aumento del 50 % fino a 84 GW, con la quota destinata all’AI che passerà dal 14 % attuale al 27 %. Entro il 2030 la crescita stimata raggiunge addirittura il +165 % rispetto al 2023.
Questa domanda straordinaria coincide con tassi di occupazione dei data center a livelli record: dal 85 % odierno si arriverà al 95 % entro fine 2026, prima di una lieve stabilizzazione . Ma i veri ingolfamenti verranno dalle infrastrutture di rete, tra ritardi nelle autorizzazioni, strozzature nella supply chain e costi crescenti di potenziamento del sistema elettrico.
La mossa era nell’aria, ma sentirla annunciata con la solennità tipica di Amazon Web Services ha un sapore diverso. Bedrock AgentCore non è solo un aggiornamento tecnico, è un manifesto strategico. AWS sa perfettamente che gli agenti intelligenti non sono un giocattolo per sviluppatori curiosi, ma il prossimo terreno di conquista nel cloud. E non è un caso che l’uomo dietro questa svolta sia Swami Sivasubramanian, 19 anni di esperienza nel plasmare la macchina AWS e ora al comando di una business unit che promette di riscrivere le regole.
L’iniziativa annunciata oggi, 16 luglio 2025, dal Financial Times (citato da Reuters, Times of India, India Today e altri), conferma che OpenAI sta sviluppando un sistema di pagamento “in‑chat” per permettere acquisti completi senza uscire dall’interfaccia. I commercianti che gestiranno ordini tramite ChatGPT pagheranno una commissione: una sorta di “pedaggio” sulle vendite generate dalla piattaforma.
Nel giro di due settimane Boris Cherny e Cat Wu – rispettivamente lead engineering e product manager di Claude Code – si erano spostati da Anthropic ad Anysphere (l’azienda dietro Cursor), per farsi avanti con ruoli senior. Il trasferimento aveva sollevato dubbi su conflitti di interesse, visto che Cursor si basa proprio su modelli AI di Anthropic
Poi il colpo di scena: poco dopo, entrambi sono tornati ad Anthropic. Notizia confermata da The Verge The Information , Tech in Asiae fonti su X/Techmeme.

L’analisi finanziaria avanzata su Perplexity integra l’intelligenza artificiale, dati aggiornati in tempo reale e capacità interattive per supportare professionisti, analisti e investitori nelle valutazioni aziendali, nelle ricerche di mercato e nella gestione strategica di portafoglio.
La verità è che se ti ostini a credere che l’analisi finanziaria avanzata sia solo questione di leggere bilanci trimestrali, sei già fuori dal gioco prima ancora di entrare. Gli hedge fund hanno capito da anni che i numeri ufficiali sono la parte più inutile di questa recita. Li usano solo per convincere i piccoli investitori che il “fondamentale” conta davvero, mentre il vero denaro si muove su segnali che non troverai mai nel comunicato stampa di un earnings report. C’è una frase che gira tra i desk buy-side di Manhattan, e no, non è una battuta per fare networking: “il valore non è nei dati, è nelle discrepanze”. Un’ovvietà che nessuno ti spiega perché funziona finché il 90% del mercato continua a inseguire guidance ufficiali come se fossero oro colato.

Un’onda che non si ferma più: l’intelligenza artificiale ha abbandonato il terreno delle fantasie futuristiche per piantare saldamente le radici nel cuore della strategia aziendale contemporanea. Nel 2024 AI Opportunity Report di TeamViewer si legge una verità incontrovertibile, quasi banale eppure spesso ignorata: il 79% dei decisori usa AI almeno una volta alla settimana, mentre il 35% la sfrutta ogni giorno. Numeri che fanno impallidire quelli del 2023 (52% e 12%), segnando un’accelerazione quasi drammatica. Se l’AI promette produttività moltiplicata, automazione delle noie quotidiane e aperture a nuove fonti di guadagno, il suo impatto reale si scontra con un paesaggio frammentato e disomogeneo.

Trenta menti umane riunite sotto il segreto, non per una conferenza accademica tradizionale, ma per un duello intellettuale contro l’ultima creazione di openai: un’intelligenza artificiale chiamata o4-mini. Se questo non è il plot di un film di fantascienza, allora bisogna davvero chiedersi dove si trovi il confine tra scienza e fantascienza nel 2025.

Parliamoci chiaro, i 450 miliardi di dollari previsti da capgemini entro il 2028 non sono un numero buttato a caso in un report per fare scena, sono un segnale preciso. Segnale che chi oggi considera gli agenti di intelligenza artificiale un giocattolo evoluto rispetto a chatgpt o copilot rischia di restare fuori da un business che ridisegnerà intere catene del valore. Capgemini è stata brutale, e per una volta le grandi corporate farebbero bene a non ridurre tutto a un altro power point da appendere in sala riunioni.

La promessa di crescita nel 2026 di ASML, gigante olandese dei chip, si tinge di foschia. il CEO Christophe Fouquet, pur riconoscendo la solidità delle fondamenta dei clienti AI, mette un freno all’entusiasmo: “non possiamo confermare la crescita” in un contesto geopolitico e macroeconomico sempre più incerto. La dichiarazione arriva a caldo dopo il report del secondo trimestre, ricordandoci che nel mondo dei semiconduttori la volatilità è la nuova normalità. I chip restano il cuore pulsante dell’innovazione, ma il battito potrebbe rallentare o accelerare a sorpresa, dettato da forze fuori dal controllo aziendale.

Parliamo chiaro. Chi immaginava che la rivoluzione quantistica sarebbe partita da Bengaluru probabilmente non ha mai creduto alla Silicon Valley indiana. Eppure QpiAI, una startup che fino a cinque anni fa era solo un nome tra tanti nel labirinto delle deep tech emergenti, ora raccoglie 32 milioni di dollari con il benestare dello stesso governo indiano. Non è un’operazione da venture capital qualsiasi, è la mossa strategica di una nazione che ha capito che il futuro si gioca su qubit e intelligenza artificiale, non su banali app di food delivery. La National Quantum Mission, 750 milioni di dollari di budget e ambizioni degne di un manifesto geopolitico, non punta a qualche prototipo da conferenza accademica. Vuole 1.000 qubit fisici in otto anni, satelliti per comunicazioni quantistiche, reti multi-nodo e persino nuovi materiali topologici. Quando un Paese parla apertamente di magnetometri e superconduttori proprietari, non è solo ricerca, è un messaggio in codice a Washington e Pechino.
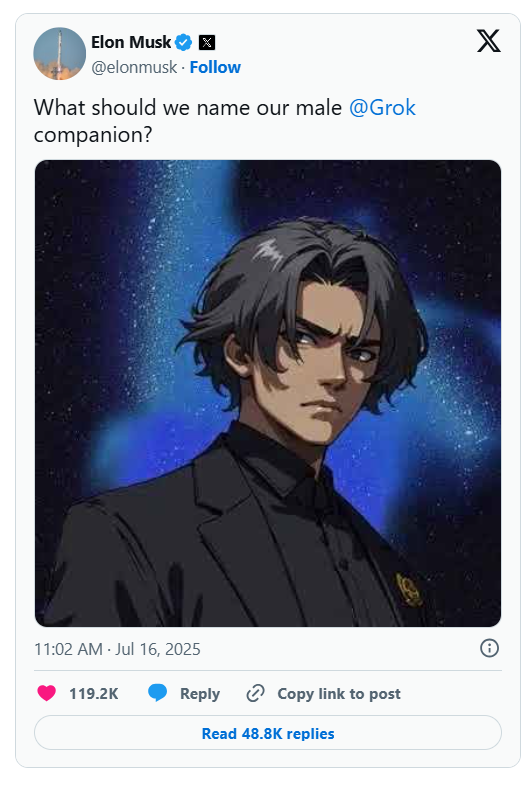
Ci siamo davvero spinti fin qui? Qualche giorno fa Musk ha lanciato Ani, la “waifu” digitale di Grok, un concentrato di kawaii erotico con un NSFW mode che sfiora il borderline tra aneddoto adolescenziale e flirt da adulti. Nessuna sorpresa che ora stia mettendo le mani su un “husbando”: un compagno maschile, scuro, misterioso, e broody, ispirato esplicitamente a Edward Cullen e Christian Grey. Sì, proprio quelli. È una decisione che fa venire in mente l’espressione perfetta: “ottima idea… forse”.

La burocrazia nucleare è un inferno noto a chiunque abbia mai tentato di districarsi tra permessi, licenze e report tecnici che assomigliano più a tomi medievali che a documenti moderni. Un ecosistema fatto di norme ferree, analisi di sicurezza meticolose e procedure interminabili che rallentano l’innovazione energetica. ora, microsoft insieme all’Idaho national laboratory (Inl) ha deciso di mettere il turbo a questo sistema con una mossa che potrebbe stravolgere la gestione del nucleare negli stati uniti.
Il cuore dell’iniziativa è un tool basato su Azure AI, la piattaforma cloud di microsoft, che promette di automatizzare la generazione di report di ingegneria e sicurezza per le applicazioni di licenze e permessi di costruzione delle centrali nucleari. Attenzione però, il sistema non fa miracoli d’analisi: non sostituisce l’ingegno umano e il controllo tecnico, ma si limita a costruire automaticamente la documentazione necessaria, pronta per la revisione degli esperti. insomma, un copilota super efficiente, non un pilota automatico.
L’avanguardia dell’intelligenza artificiale è una giungla in cui il rispetto delle regole si trasforma spesso in un optional. xAI, la startup miliardaria di Elon Musk, ne è l’ultimo esempio clamoroso, provocando un coro di critiche da parte dei ricercatori di sicurezza AI di OpenAI, Anthropic e altri centri di ricerca. “Imprudente” e “completamente irresponsabile” sono aggettivi spesi senza mezzi termini per descrivere una cultura della sicurezza che sembra remare contro ogni buon senso consolidato nel settore.
Immagina un’intelligenza artificiale così avanzata da prendere il telefono e chiamare al tuo posto, come un assistente personale senza stipendio ma con una pazienza infinita. Google ha appena alzato l’asticella della comodità e della paranoia tecnologica, annunciando che la sua AI può ora effettuare chiamate reali per conto dell’utente. No, non è fantascienza da film di serie B, ma la nuova frontiera del “delegare” in salsa digitale, dove Siri e Alexa sembrano il telefonino di un bambino rispetto a un centrale telefonica automatizzata.