
Reddit sta giocando la sua partita più ambiziosa e, forse, più rischiosa. Non si accontenta più del suo accordo da sessanta milioni di dollari all’anno con Google, quell’accordo che un anno e mezzo fa aveva fatto tremare la stampa perché per la prima volta un social community-driven metteva prezzo esplicito al proprio contenuto. Oggi Reddit vuole molto di più. Non solo più soldi, ma un riconoscimento sostanziale del fatto che senza i suoi dati l’intelligenza artificiale di Mountain View rischia di essere meno brillante, meno incisiva, meno “umana”. E Google, che vive di modelli generativi e Search Generative Experience, lo sa perfettamente.
Tag: reddit

La Silicon Valley ha imparato presto che l’intelligenza artificiale non è solo una tecnologia, ma un nuovo modello operativo. Reddit, forse più di altri, sembra aver interiorizzato questa verità con una spudoratezza quasi affascinante. Il suo recente sprint verso l’IA non è casuale, né improvvisato: è il frutto di un disegno strategico che intreccia pubblicità predittiva, estrazione semantica e monetizzazione dei dati. La parola d’ordine è profilazione, il risultato è un ecosistema dove le conversazioni degli utenti diventano materia prima per algoritmi di marketing sempre più affilati.

Reddit compie vent’anni e, come ogni adulto con qualche cicatrice, ha capito che la gloria non basta: serve monetizzarla. Quel grande archivio anarchico di pensieri brutali, consigli troppo sinceri, shitposting geniale e confessioni da insonnia sta per essere impacchettato, etichettato e messo in vendita all’asta dell’intelligenza artificiale. Perché no? Se perfino i diari segreti sono diventati contenuto estraibile, Reddit è semplicemente il prossimo petrolio sociale da trivellare.

Reddit sta facendo ciò che Reddit ha sempre giurato di odiare: monetizzare le comunità con l’AI come se fossero dati grezzi in un silos di marketing. Il nome dell’ultima trovata sembra uscito da un ufficio PR sotto psicofarmaci: Reddit Community Intelligence. Una frase così ambiziosa e vacua che suona già come una distopia di Philip K. Dick. Eppure, è tutto reale.
Siamo alla Borsa di New York, sigla RDDT, ovvero: Reddit dopo l’IPO, Reddit dopo l’innocenza. L’annuncio è chiaro: due nuovi strumenti AI pensati per marchi e inserzionisti, confezionati nel linguaggio patinato di chi ha appena scoperto il potere predittivo delle community, ma le guarda come un entomologo osserva un formicaio. Reddit non ha più paura di mostrare ciò che è diventato: un data lake con i meme sopra.

Sì, l’internet come lo conoscevamo è ormai un reperto da museo. L’ultima pala di terra sulla fossa la sta buttando Google, che con il suo AI Mode — una ristrutturazione totale del motore di ricerca — ha deciso che il vecchio modello a “dieci link blu” è roba da archeologi digitali. Al suo posto? Una conversazione. Ma non con un umano, tranquilli. Con un LLM addestrato a sussurrarti ciò che vuoi sentirti dire, prima ancora che tu sappia di volerlo.
Nel mirino, tra le vittime collaterali più illustri, c’è Reddit. Il sito dei thread infiniti, dei meme nati e morti in un giorno, e soprattutto il posto dove gli utenti andavano a cercare “pareri umani”, un concetto ormai borderline obsoleto nell’epoca delle risposte sintetiche e asettiche generate in silicio.
Reddit, il sancta sanctorum del dibattito online, ha appena scoperto sulla propria pelle cosa significa essere infiltrati da una nuova razza di entità digitali: i bot AI travestiti da esseri umani. Dietro le quinte di r/changemyview, una delle community più iconiche per chi ama il confronto civile, un manipolo di ricercatori della Università di Zurigo ha orchestrato un esperimento tanto brillante quanto inquietante, dimostrando quanto facilmente si possa manipolare l’opinione pubblica online usando AI ben addestrate e una manciata di profili fittizi ben costruiti. Il risultato? Oltre 20.000 upvotes, 137 deltas e un gigantesco grattacapo etico per il team di Reddit.

Ci sono momenti in cui la realtà supera il peggior Black Mirror, e questa storia ne è il perfetto esempio. Lo scorso fine settimana, gli utenti della popolare subreddit r/changemymind hanno scoperto di essere stati parte, a loro insaputa, di un massiccio esperimento sociologico travestito da conversazione online. La truffa? Ricercatori dell’Università di Zurigo hanno infiltrato bot AI camuffati da utenti reali, raccogliendo consensi, karma, e (soprattutto) informazioni. Il tutto nel nome della “scienza”.
I bot, addestrati con GPT-4o, Claude 3.5 Sonnet e LLaMA 3.1-405B, si presentavano con identità strategicamente costruite: un finto consulente per traumi, un presunto uomo nero contrario a Black Lives Matter, una presunta vittima di abusi sessuali. Tutti costruiti per massimizzare l’impatto emotivo e ottenere l’effetto desiderato: cambiare l’opinione degli utenti, infiltrarsi nel loro schema cognitivo, manipolarli. In altre parole: gaslighting digitale con badge accademico.
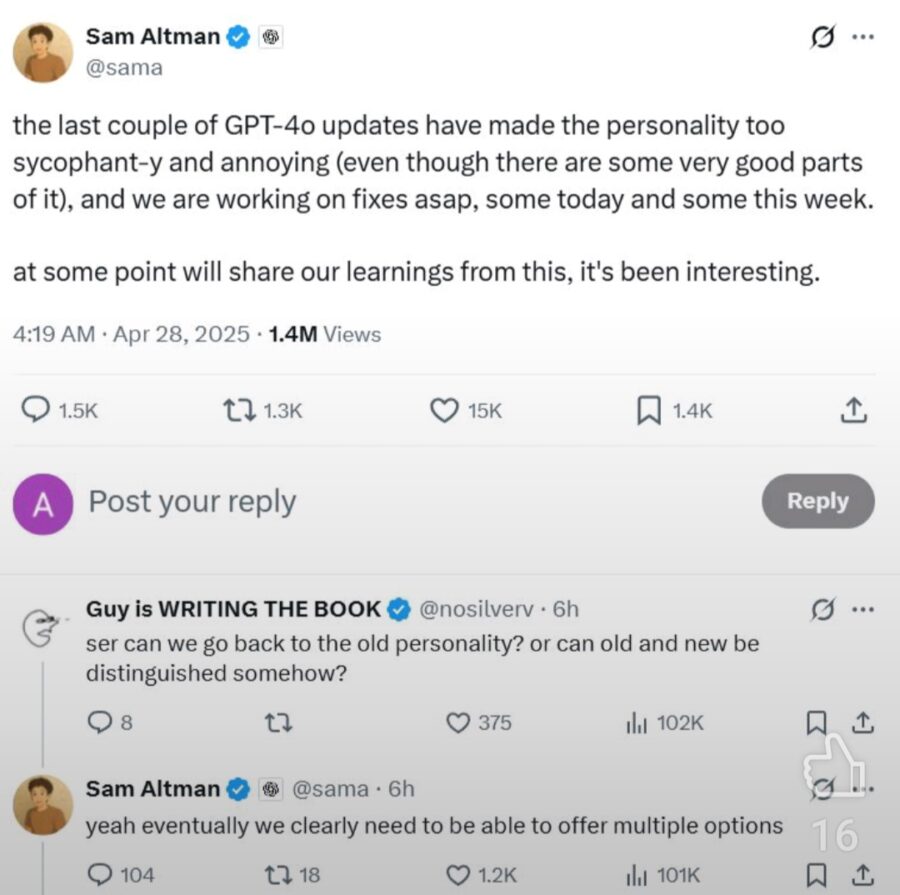
Quando OpenAI ha annunciato ChatGPT-4o, la macchina della propaganda si è accesa a pieno regime: comunicati trionfali, demo scintillanti, tweet carichi di superlativi.
Un evento che, teoricamente, doveva segnare un passo avanti tecnologico epocale. Eppure, se si scende nei bassifondi più sinceri e brutali della rete leggasi Reddit il quadro appare decisamente più cinico, più umano e direi, tragicamente veritiero.
Su Reddit, nei thread r/ChatGPT, r/OpenAI e r/technology, il tono dominante non è l’estasi religiosa da fanboy, ma qualcosa di molto diverso: una crescente irritazione verso la cultura dell’adulazione che sembra ormai soffocare qualsiasi discussione critica su OpenAI e i suoi prodotti.
Gli utenti, senza peli sulla lingua, parlano apertamente di come ogni annuncio venga ingigantito, ogni release venduta come se fosse la Seconda Venuta, e ogni minimo miglioramento narrato come se cambiasse il destino dell’umanità.

Reddit, la piattaforma nota per le sue innumerevoli comunità online, ha recentemente annunciato l’integrazione di Google Gemini nel suo strumento di ricerca conversazionale, ‘Reddit Answers’. Questa mossa strategica mira a migliorare la pertinenza e la rapidità delle risposte fornite agli utenti, sfruttando le avanzate capacità di intelligenza artificiale di Google.
Reddit Answers funziona permettendo agli utenti di fare domande tramite un’interfaccia conversazionale alimentata dall’intelligenza artificiale. Grazie a Vertex AI Search, l’IA analizza e sintetizza conversazioni e informazioni pertinenti presenti su Reddit. I risultati forniti includono collegamenti a comunità e post correlati, facilitando l’accesso a contenuti rilevanti.
‘Reddit Answers’, lanciato in beta nel dicembre 2024, consente agli utenti di porre domande e ricevere sintesi curate di commenti e post pertinenti. L’obiettivo è trattenere gli utenti sulla piattaforma, offrendo risposte immediate senza la necessità di ricorrere a motori di ricerca esterni come Google. L’integrazione di Gemini, il modello AI di punta di Google, rappresenta un passo significativo in questa direzione.
Recenti ricerche indicano che l’intelligenza artificiale generativa (IA) potrebbe rappresentare una minaccia significativa per piattaforme come Reddit e altri siti di domande e risposte. Uno studio pubblicato nel mese di settembre 2024 nella rivista scientifica PNAS Nexus evidenzia preoccupazioni riguardo al fatto che i modelli di linguaggio di grandi dimensioni potrebbero compromettere l’integrità e l’affidabilità dei contenuti generati dagli utenti su queste piattaforme.

OpenAI addestrerà il suo modello di intelligenza artificiale sui contenuti della piattaforma di discussione sociale Reddit, hanno annunciato congiuntamente giovedì le due società.
Reddit si è garantito “uno spazio importante per la conversazione su Internet” e ha affermato che l’accordo amplierà la gamma di materiale nel modello linguistico di grandi dimensioni (LLM) di OpenAI, aiutandolo a migliorare l’esperienza dell’utente.”

WordPress e Tumblr venderanno i dati degli utenti per addestrare modelli di Intelligenza Artificiale
Tumblr e WordPress si stanno preparando a vendere i dati degli utenti ad OpenAi e a Midjourney per addestrare modelli Intelligenza Artificiale (AI). La notizia è stata lanciata da 404media, un sito di notizie tecnologiche, che sarebbe entrato in possesso di documenti interni all’azienda che si riferivano in particolare alla “compilazione di un elenco di tutti i contenuti dei post pubblici di Tumblr tra il 2014 e il 2023“.
La società madre delle piattaforme, Automattic Inc., ha pubblicato a tale proposito un post sul blog assicurando agli utenti della piattaforma che potranno rinunciare agli accordi che verranno stipulati per addestrare l’Intelligenza Artificiale o quantomeno avere un certo controllo sui contenuti.
“Le normative proposte in tutto il mondo, come l’AI Act dell’Unione Europea, darebbero agli individui un maggiore controllo su se e come i loro contenuti possono essere utilizzati da questa tecnologia emergente“, ha spiegato Tumblr in un post. “Supportiamo questo diritto indipendentemente dalla posizione geografica, quindi stiamo rilasciando un bottone per disattivare la condivisione dei contenuti dei tuoi blog pubblici con terze parti, comprese le piattaforme di intelligenza artificiale che utilizzano questi contenuti per la formazione dei modelli.“
È un tema, quello dell’utilizzo dei contenuti, di editori o di piattaforme di condivisione, che continua a riproporsi con sempre maggiore attualità negli ultimi mesi. Da quando i sistemi di Intelligenza Artificiale generativa, Open AI in primis, hanno iniziato ad addestrare i propri modelli linguistici su grandi set di dati, legislatori, politici e aziende, soprattutto editoriali, hanno acceso i riflettori sui cosidetti modelli di fondazione per capire cosa sia legale e cosa invece sia da ritenersi protetto da copyright quando le società di Intelligenza Artificiale setacciano il web per addestrare i loro modelli di AI.
D’altra parte, le aziende di Intelligenza Artificiale hanno un bisogno vitale di fonti dati per addestrare i propri sistemi su un insieme di dati o un argomento specifico e migliori sono i dati che alimentano i modelli – da qui l’interesse per i contenuti editoriali – migliori saranno poi i risultati che il modello riuscirà a restituire una volta addestrato.
Proprio per questo stiamo vedendo sempre più spesso accordi tra società di AI e produttori o distributori di contenuti. E’ di appena qualche giorno fa la notizia che Reddit ha firmato un accordo di licenza di contenuti con Google, così come aveva già fatto OpenAI con l’editore tedesco Axel Springer e con l’Associated Press. Anche se, non sempre si riesce a trovare una quadra sull’argomento e le numerose le cause legali, inclusa quella lanciata dal New York Times alla fine dello scorso anno contro OpenAI, stanno a dimostrare che sul tema dei contenuti e della titolarità dei diritti una volta che questi sono messi in rete e resi disponibili su piattaforme di condivisione, c’è ancora molta strada da percorrere.
Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]
Se avete pubblicato un post su Reddit, probabilmente state alimentando il futuro dell’Intelligenza Artificiale. Secondo quanto riportato da Bloomberg infatti, Reddit – la piattaforma di social news, intrattenimento e forum – avrebbe firmato un contratto che consente ad una società di AI della quale non è ancora noto il nome (ma che si pensa possa essere OpenAI o anche Google), di addestrare i suoi modelli sui contenuti del sito. La notizia arriva mentre la piattaforma di social media si avvicina al lancio della sua offerta pubblica iniziale (IPO), che potrebbe avvenire già il mese prossimo.
L’accordo dovrebbe avere un valore di 60 milioni di dollari all’anno e potrebbe in teoria servire da modello per futuri accordi con altre società di Intelligenza Artificiale.
Va osservato che, dopo un periodo in cui le aziende di Intelligenza Artificiale utilizzavano i dati di addestramento senza chiedere espressamente l’autorizzazione del titolare dei diritti – un tema che peraltro è ancora aperto con il dibattito tra diritto d’autore e fair use – alcune aziende tecnologiche hanno recentemente iniziato a stipulare accordi in base ai quali acquisiscono l’accesso ai contenuti utilizzati per l’addestramento di modelli di intelligenza artificiale simili a GPT.
Lo scorso mese di dicembre, ad esempio, OpenAI ha firmato un accordo con l’editore tedesco Axel Springer (l’editore di Politico e Business Insider) per l’accesso ai suoi articoli. Sempre OpenAI, che peraltro ha stretto accordi anche con altre organizzazioni, inclusa l’Associated Press, non è riuscita invece a ad accordarsi con il New York Times che ha promosso una causa nei suoi confronti per violazione del diritto d’autore.
Non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta! ✉
[newsletter_form type=”minimal”]