
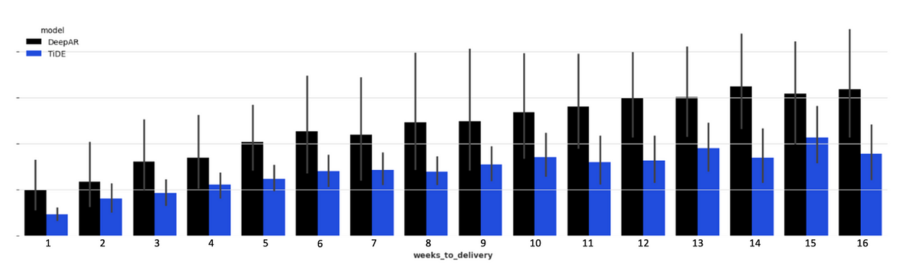
Negli ultimi anni, i modelli di previsione a lungo termine hanno guadagnato sempre più attenzione nel campo dell’intelligenza artificiale (AI) e dell’apprendimento automatico (machine learning). Questi modelli sono cruciali per una vasta gamma di applicazioni, dalle previsioni meteorologiche alle analisi economiche, passando per la gestione delle risorse energetiche e la pianificazione urbana. In questo contesto, TiDE (Time-series Dense Encoder) si è distinto come uno dei più promettenti. Sviluppato dal team di Google Research, TiDE rappresenta un passo in avanti significativo nella capacità di fare previsioni affidabili su orizzonti temporali più lunghi rispetto ai modelli tradizionali.
Autore: Dina Pagina 33 di 36
Direttore senior IT noto per migliorare le prestazioni, contrastare sfide complesse e guidare il successo e la crescita aziendale attraverso leadership tecnologica, implementazione digitale, soluzioni innovative ed eccellenza operativa.
Con oltre 20 anni di esperienza nella Ricerca & Sviluppo e nella gestione di progetti di crescita, vanto una solida storia di successo nella progettazione ed esecuzione di strategie di trasformazione basate su dati e piani di cambiamento culturale.

Nell’affascinante panorama dell’intelligenza artificiale, una nuova categoria di modelli sta emergendo come protagonista: i Modelli di Azione Avanzati (LAMs). Questi sistemi AI rappresentano un cambiamento paradigmatico, in grado di superare i limiti del tradizionale processamento del linguaggio e aprire nuovi orizzonti nell’interazione tra il mondo virtuale e quello fisico.

Quando ha segnato un decennio al vertice del potere (13 marzo 2013), era chiaro che sotto questo pontificato anticonformista, nulla sarebbe più stato lo stesso. La sua apertura, la sua passione per le riforme, il suo senso elettrico della possibilità, avevano catturato l’immaginazione del mondo e spinto l’istituzione che guida in acque inesplorate.
Era altrettanto chiaro, tuttavia, che questo affascinante papa avrebbe potuto scatenare energie che alla fine non sarà in grado di controllare.
Nonostante la sua enorme popolarità all’estero, il papa deve affrontare un nucleo determinato di opposizione interna sia da destra che da sinistra, lasciando la sua stessa istituzione lacerata, polarizzata e sempre più fragile. Un decennio di cambiamenti precedentemente impensabili ha distrutto vecchie certezze, creando un contesto in cui quasi tutto sembra possibile, compresi i risultati che l’uomo al vertice non intendeva né desiderava.
Questa potrebbe facilmente essere la descrizione di Papa Francesco in questo momento, mentre celebra il decimo anniversario della sua elezione al Soglio di Pietro.
Oggi sembra chiaro che Papa Francesco abbia enormi consensi al di fuori della Chiesa cattolica, ma un’opposizione sempre più sfrontata dall’interno. I nemici di Francesco provengono sia da una destra tradizionalista insoddisfatta della sua agenda progressista, sia da una sinistra impaziente e sempre più affamata di vera rivoluzione piuttosto che di semplici riforme.
Potentati finanziari, multinazionali, mafie, terroristi islamici, trafficanti di armi, prelati arraffoni, monsignori minacciati nel loro potere curiale, despoti avidi di ricchezze…
Francesco ha promosso una versione ecclesiastica della glasnost, sollevando vecchi tabù e incoraggiando un dibattito intenso su questioni precedentemente chiuse, dalla sensibilizzazione verso gay e lesbiche al ruolo delle donne nella chiesa, al clero sposato e questioni oltre. Anche lui ha lanciato un programma di decentramento, che ora va sotto la parola d’ordine “sinodalità”.
Francesco ha riabilitato figure emarginate sotto i papi precedenti (come i cardinali Walter Kasper Oscar Rodriguez Maradiaga) e ha invertito la rotta della Chiesa su questioni come la comunione ai cattolici divorziati risposati civilmente e la messa in latino.
La domanda ora è se riuscirà a tenere il genio nella bottiglia.
Francesco deve affrontare una forte ala destra all’interno del suo stesso sistema, compresa un’ampia fascia di dirigenti intermedi da cui dipende per governare, che temono che le cose stiano andando troppo oltre. Sebbene sia improbabile che tentino un vero colpo di stato, sono certamente inclini alla resistenza, attiva o passiva, a gran parte dell’agenda del papa.
Nel frattempo, deve anche affrontare una coorte crescente di liberali non disposti ad aspettare il permesso per attuare riforme ancora più radicali, forse in modo più evidente proprio adesso in parti dell’Europa occidentale come Germania e Belgio. Il recente voto dei vescovi tedeschi per autorizzare la benedizione delle unioni omosessuali, in aperto disprezzo delle direttive vaticane,
Certo, la Chiesa cattolica ha una forte capacità di resistenza, il cattolicesimo esiste da più di 2.000. Non importa quanto le contraddizioni sotto Francesco possano essere accentuate, è profondamente improbabile che la chiesa da lui guidata si dissolva semplicemente.
Tuttavia, la domanda rimane: la riforma moderata delineata da Francesco potrà durare, o le energie centrifughe di un’epoca profondamente polarizzata si dimostreranno così intense da rendere inevitabile una rottura?
Francesco è destinato a bere fino in fondo questo calice amaro, nel linguaggio dei Salmi? Oppure, data la resilienza relativamente maggiore del cattolicesimo e l’opportunità di imparare dall’esperienza, Francesco potrà riuscire lasciando dietro di sé un’istituzione rivitalizzata pronta ad affrontare le sue sfide con nuova energia e senso di scopo?
Quando Papa Francesco parlerà al G7 sull’intelligenza artificiale (AI), il mondo intero sarà in ascolto. Il leader spirituale della Chiesa cattolica romana ha già dimostrato di essere un pensatore progressista e rivoluzionario, e molti si aspettano che porti la stessa energia e passione alla discussione sull’AI.
In passato, ha espresso preoccupazione per l’impatto dell’AI sulla società, affermando che “la tecnologia non può essere neutrale” e che “dobbiamo garantire che l’intelligenza artificiale sia al servizio dell’umanità e non il contrario”.
Quando Papa Francesco parlerà al G7 sull’AI, ci si aspetta che affronti questioni come l’etica dell’AI, la privacy e la sicurezza, l’impatto sull’occupazione e la necessità di una regolamentazione globale. Si prevede anche che esorti i leader mondiali a lavorare insieme per garantire che l’AI sia utilizzata in modo responsabile e per il bene comune.
Ma Papa Francesco non si fermerà qui. Come leader spirituale, è anche profondamente interessato all’impatto dell’AI sulla dignità umana e sul nostro senso di identità. In un mondo in cui le macchine diventano sempre più intelligenti, cosa significa essere umani? Come possiamo garantire che l’AI non eroda la nostra umanità e i nostri valori fondamentali?
Queste sono domande difficili, ma Papa Francesco non ha paura di affrontarle. In passato, ha esortato i leader tecnologici a considerare l’impatto etico delle loro innovazioni e ha chiesto una “rivoluzione etica” nella tecnologia. Quando parlerà al G7 sull’AI, ci si aspetta che faccia lo stesso.
In un mondo sempre più dominato dalla tecnologia, Papa Francesco è una voce profetica che ci ricorda che la tecnologia non è un fine in sé, ma uno strumento per il bene comune. Ci si aspetta che sfidi i leader mondiali a pensare in modo critico sull’impatto dell’AI sulla società e a lavorare insieme per garantire che questa tecnologia sia utilizzata in modo responsabile e per il bene di tutti.
Pope Francis, now marking a decade in power, has led a transformative and unconventional papacy, pushing the Catholic Church into new territory with reforms and openness. While his popularity outside the Church remains strong, he faces growing opposition from within, both from traditionalists unhappy with his progressive agenda and liberals eager for more radical changes. His reforms, such as decentralization and addressing previously taboo issues like LGBTQ rights and women’s roles, have sparked internal polarization.
As Pope Francis prepares to speak at the G7 on artificial intelligence (AI), he’s expected to address ethical concerns, privacy, and AI’s impact on society, urging responsible global regulation. He will also focus on preserving human dignity in a tech-driven world, challenging world leaders to ensure AI serves humanity, not the other way around.
The central question remains whether his moderate reforms will endure or if internal divisions will lead to lasting fractures within the Church.

Con l’incertezza economica e geopolitica in corso, i dirigenti finanziari degli Stati Uniti hanno concentrato le loro energie sul rafforzamento degli sforzi di riduzione dei costi, rendendola la loro priorità numero uno, secondo un recente sondaggio di US Bank (USB).
Questo è un ambiente difficile per i direttori finanziari.
Making big decisions in the face of big unknowns
“Si trovano ad affrontare inflazione e tassi di interesse più elevati, incertezza politica negli Stati Uniti e all’estero, un’economia a breve termine difficile da prevedere e un’incredibile pressione per effettuare i giusti investimenti tecnologici di cui le loro aziende avranno bisogno per competere”
Stephen Philipson, responsabile dei mercati globali e della finanza specializzata presso US Bank.
Ridurre i costi all’interno della funzione finanziaria e dell’intera azienda sono le due priorità principali, secondo il quarto rapporto annuale CFO Insights della banca statunitense, che ha intervistato 2.030 dirigenti finanziari senior durante il periodo gennaio-febbraio.
Concentrarsi sulla gestione del rischio sta diventando sempre più importante per i CFO, diventando ora la terza priorità più comune. L’aumento dell’espansione delle entrate, nel frattempo, occupa una posizione modesta come la quinta questione più urgente.
Uno dei maggiori rischi che gli intervistati continuano a citare è il ritmo dei cambiamenti tecnologici.
Quasi la metà dei CFO intervistati ha affermato di dare priorità agli investimenti nella tecnologia rispetto ai tagli ai posti di lavoro come soluzione principale per tagliare le spese. L’intelligenza artificiale è la seconda priorità per gli investimenti nella funzione finanziaria (51%) dopo l’analisi dei dati (52%). In generale, i licenziamenti sono considerati quasi l’ultima risorsa quando si tratta di tagliare le spese.
Un sondaggio Coupa all’inizio di questo mese ha rivelato che, mentre il 45% dei CFO afferma di voler investire nell’intelligenza artificiale per stimolare la crescita quest’anno, l’89% di loro nutre dubbi sulla capacità della propria azienda di implementare con successo una strategia di intelligenza artificiale.
Due CFO su cinque hanno riferito che la loro sfida più grande è tenere il passo con i progressi dell’intelligenza artificiale “poiché il tasso di innovazione supera la scala umana e l’efficienza dei processi tradizionali”, afferma l’indagine Strategic CFO di Coupa.
In una lettera agli azionisti, il CEO di Amazon Andy Jassy ha sottolineato l’attenzione del colosso dell’e-commerce sulle misure di riduzione dei costi, parlando al contempo del potenziale dell’intelligenza artificiale, affermando che la società ha “trovato diverse aree in cui crediamo di poter ridurre ulteriormente i costi mentre inoltre, consegnamo più velocemente ai clienti.”
Nello spazio tecnologico, Meta Platforms ha segnalato la scorsa settimana che sarebbe stata in un ciclo di investimenti per qualche tempo mentre la corsa all’intelligenza artificiale continua. Anche se si prevede che una tale mossa aumenterà i costi nel breve periodo, Wall Street ritiene che la spesa per l’intelligenza artificiale potrebbe ripagare nel lungo termine, con Andrew Boone di JMP Securities che afferma che Meta probabilmente sarà “ben posizionata” per trarre vantaggio dall’intelligenza artificiale. aumentare il coinvolgimento e l’efficienza pubblicitaria.
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
[newsletter_form type=”minimal”]
Per IDC nel 2028 il 70% della spesa in server e storage proverrà dai Cloud Provider: uno scenario molto rischioso per utenti e produttori hardware, sottolinea The Next Platform
Proprio mentre la pandemia di coronavirus si è scatenata nel primo trimestre del 2020, secondo i dati dell’IDC che abbiamo monitorato con attenzione fin dalla loro prima pubblicazione nel 2021 nel suo Worldwide Quarterly Enterprise Infrastructure Tracker, i service provider intendendo gli iperscalers, i costruttori di cloud e altri service provider che costruiscono infrastrutture per data center e vendono capacità su di essa come gruppo hanno superato il 50 percento delle entrate combinate di server e storage WW.
IDC-Worldwide-Quarterly-Enterprise-Infrastructure-Tracker-Buyer-and-Cloud-Deployment-2023-AugDownload
Avevano rappresentato più della metà delle spedizioni di unità diversi anni prima, secondo stime.
Se i prognostici dell’IDC sono corretti, quattro anni da ora, quando il 2028 sta per concludersi, i service provider come gruppo costituiranno più di due terzi delle entrate di server e storage per quell’anno.
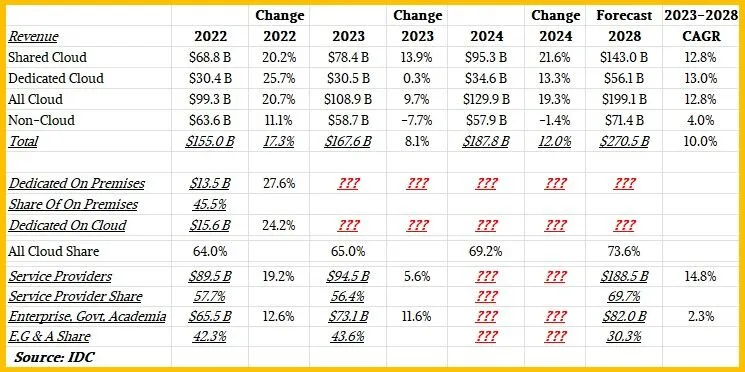
La previsione più recente per il 2028, infatti, mostra che i service provider, che hanno acquistato 94,5 miliardi di dollari di attrezzature di server e storage nel 2023 (in aumento del 5,6 percento e dando agli SP una quota del 56,4 percento) vedranno le loro spese salire a 188,5 miliardi di dollari entro il 2028, conferendo a questo prestigioso gruppo una quota del 69,7 percento dei soldi spesi su questa attrezzatura.
Le imprese, i governi e le istituzioni accademiche hanno rappresentato 73,1 miliardi di dollari di acquisizioni di server e storage l’anno scorso, in aumento del 11,6 percento anno su anno e dando loro una quota del 43,6 percento delle spese. Ma entro il 2028, con un tasso di crescita annuo composto che è 6,4 volte più piccolo al 2,3 percento, questa quota EG&A Expenses for General and Administrative. scenderà al 30,3 percento delle spese e raggiungerà solo 82 miliardi di dollari entro il 2028.
Questo è più simile a dozzine di acquirenti di server in quella fetta maggioritaria, ma è molto più vicino a cinque acquirenti di server di quanto vorremmo.
E ci chiediamo come faranno a crescere e a rimanere finanziariamente sani i restanti OEM (Original Equipment Manufacturer, parti prodotte da una societa’ usate in un’altra) di server che servono la classe di EG&A in alcuni casi, diventare finanziariamente sani in primo luogo.
Ecco come appaiono le vendite di server e storage ai SP (Service Providers) rispetto alle EG&A negli ultimi quattro anni, che è l’unica data che abbiamo disponibile dall’IDC per queste due distinzioni:
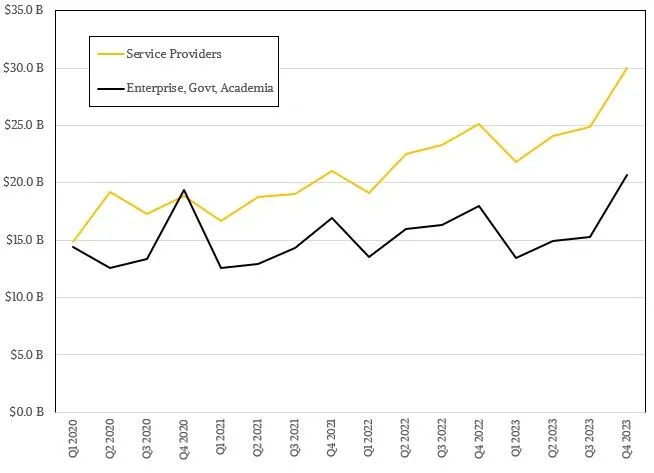
Il divario tra le due classi di acquirenti di server e storage non sembra così grande, vero? Ma si è ampliato, in media, negli ultimi due decenni e mezzo, e ci sembra che i server AI che eseguono grandi modelli di linguaggio stiano per ribaltare l’equilibrio a partire dal 2024.
IDC non ha spiegato la differenza massiccia nei tassi di crescita nel suo rapporto pubblico, ma pensiamo che questo sia il differenziatore. E potrebbe anche accadere che gli LLM siano le killer app per i cloud, costringendo le imprese, i governi e le istituzioni accademiche a farlo sul cloud anziché lottare per il budget e gli acceleratori per i propri data center.
La crescita per SP e sEG&A è altalenante. Nessuno dei due è particolarmente lineare su base trimestrale. Ma ci sarà un divario più ampio che si aprirà se l’IDC avrà ragione.
Questi dati sono presentati dall’IDC come un modo per spiegare le vendite di macchinari per l’infrastruttura cloud, distinta dalle macchine bare metal che eseguono database relazionali e suite di applicazioni back office come ERP, SCM, CRM e altre.
(Queste sono abbreviazioni per pianificazione delle risorse aziendali, gestione della catena di approvvigionamento e gestione delle relazioni con i clienti, e sono le principali attività che svolgono la maggior parte delle imprese, che includono cose noiose come conti da pagare e ricevere e stipendi. Noi pensiamo che la gestione dello stipendio sia molto eccitante, personalmente. . . .)
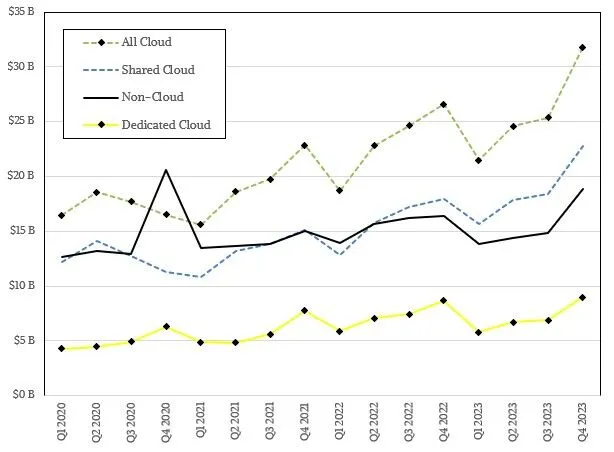
Ecco come è apparsa quella spesa per gli ultimi anni per il cloud condiviso, il cloud dedicato e gli utilizzi non cloud:
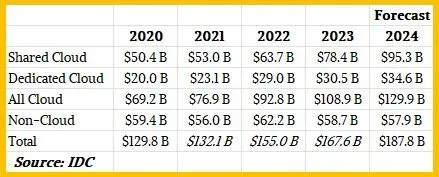
L’infrastruttura cloud condivisa è esattamente ciò che sembra: macchine vendute in modo che possano essere virtualizzate e vendute con più aziende contemporaneamente che affittano tempo su di esse. Il cloud dedicato significa che le macchine vengono vendute per essere utilizzate come macchine host nel senso più tradizionale dell’outsourcing – una scatola, un cliente – così come l’infrastruttura periferica venduta sotto un modello di prezzo cloud per le aziende da eseguire nel proprio data center o in una struttura di co-location da loro scelta. Non-cloud sono quelle noiose attività di back office che mantengono effettivamente in movimento l’economia globale.
In passato, IDC suddivideva il mercato del cloud dedicato in cloud dedicato e cloud dedicato in loco, e siamo abbastanza sicuri che lo faccia ancora, ma non lo sta più facendo nei dati che rilascia al pubblico.
Ecco una tabella mostro che riporta tutto ciò che sappiamo dell’IDC che copre il 2022 e il 2023, include anche la previsione per il 2024 e quella lontana fino al 2028:
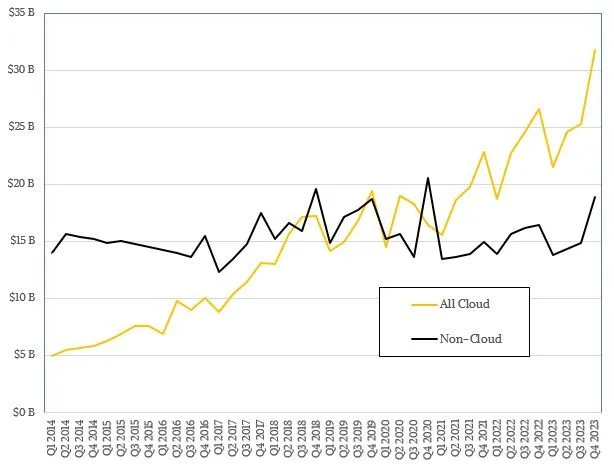
Per coloro che preferiscono un’analisi visiva, ecco un grafico del buying di server e storage cloud rispetto a non cloud dal 2014, che fa parte di un set di dati più vecchio e più ampio che abbiamo monitorato, prima che venissero suddivisi i diversi tipi di spesa cloud e prima che iniziassero a dare il breakout SP e EG&A. Date un’occhiata:
Ecco la suddivisione delle diverse tipologie di spesa cloud rispetto a non cloud:
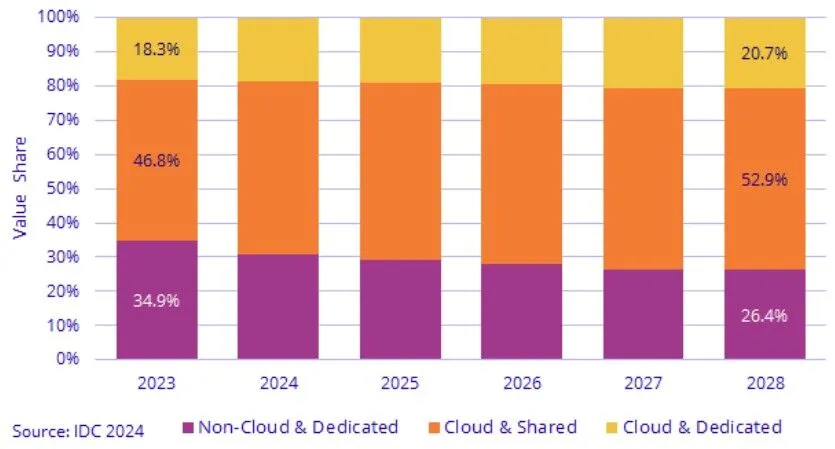
E per completare il set, ecco un grafico a barre sovrapposte che mostra la suddivisione della spesa tra i tre tipi di casi d’uso dei clienti – non cloud, cloud condiviso e cloud dedicato – tra il 2023 e il 2028:
Quasi due decenni fa, quando è iniziata la seconda ondata di utility computing – ricordate l’ascesa dei service provider di applicazioni e del grid computing a seguito della commercializzazione delle tecnologie Internet alla fine degli anni ’90? – era importante monitorare l’ascesa del modello di consumo del cloud computing. Ma alla fine, il cloud è solo un modello di consumo. Ciò di cui abbiamo parlato all’inizio di questa storia è un cambiamento nei consumatori stessi, e questo è forse più profondo a lungo termine.
In quel più lungo del lungo termine, le imprese potrebbero perdere le competenze necessarie per gestire la propria infrastruttura mentre diventano più dipendenti dai service provider.
In quel più lungo del lungo termine, potrebbero non esserci produttori di chip, di sistemi e di storage indipendenti, e l’IT potrebbe diventare molto più costoso a causa di questo.
Potrebbero non esserci affatto acquirenti di server e neanche produttori di server. Solo cloud iperscalabili (questo è un ibrido intenzionale) che vendono accesso alle applicazioni con AI costose integrate che nessuno può replicare facilmente in un data center proprio, tutto basato sull’hardware di loro progettazione e realizzazione.
Cosa succede se la Lobby degli Hyperscalere dei costruttori di cloud non è solo quello di costruire le proprie cose, ma di impedire alle aziende e ai partner OEM di costruire un’alternativa?
Questo è ciò che accade quando il settore EG&A revenues diventa troppo piccolo, e non pensare nemmeno per un secondo che questi giganti sempre affamati non lo sappiano.

Innovazione, Digital Twin, Analisi Dati, Risultati Finanziari e Riconoscimento del Mercato.
Nell’ultimo anno, il settore tecnologico negli Stati Uniti ha mostrato progressi impressionanti, fungendo da motore fondamentale dell’espansione economica e portando il mercato azionario a nuovi massimi storici.
In particolare, settori come quello dei semiconduttori, dell’hardware dei computer, delle infrastrutture software e dei software applicativi sono emersi come risultati di spicco.
Questa notevole crescita è dovuta molto allo sviluppo e alla proliferazione delle tecnologie di Intelligenza Artificiale (AI) e Machine Learning (ML), applicazioni software all’avanguardia, che sono sempre più integrate in molti aspetti della nostra vita.
Queste tecnologie hanno rivoluzionato l’analisi dei dati e i processi decisionali, rafforzando l’efficienza e l’efficacia di vari settori. Inoltre, la crescente integrazione dell’Internet delle cose (IoT) e gli sforzi verso una connettività di rete completa e la digitalizzazione hanno spinto in modo significativo questi settori verso una redditività sostenuta.
Palantír è un oggetto immaginario presente nella trilogia de “Il Signore degli Anelli” di J.R.R. Tolkien. Si tratta di una pietra vedente, una sfera di cristallo utilizzata per comunicare a distanza e per vedere eventi lontani. I Palantír furono creati dagli Elfi nell’antichità e in seguito furono dati agli uomini di Númenor. Dopo la caduta di Númenor, i Palantír furono portati nella Terra di Mezzo e divisi tra i regni dei Dúnedain.
Palantir Technologies inc. ha sede a Denver in Colorado ed è stata fondata da Peter Thiel, Nathan Gettings, Joe Lonsdale, Stephen Cohen e Alex Karp nel 2003. Inizialmente le agenzie federali statunitensi erano i principali clienti dell’azienda per poi gradualmente servire agenzie governative di altri paesi nonché aziende private che operano in ambito finanziario e dell’assistenza sanitaria.
Palantir Technologies Inc. ha annunciato a dicembre 2023 ad esempio di aver rinnovato la sua partnership con UniCredit S.p.A finalizzata alla fornitura del sistema operativo Palantir Foundry per accelerare la trasformazione digitale della banca, aiutandola ad incrementare i ricavi e a mitigare i rischi.

Nel 2019, Shyam Sankar, Chief Technology Officer di Palantir, ha scritto di come i big data, spacciati da molti come “il nuovo petrolio”, fossero più simili a petrolio di serpente, dato l’enorme e persistente divario tra ciò che i fornitori promettevano e ciò che effettivamente fornivano.
Palantir è molto forte nello spazio AI/ML proprio per il nostro sano realismo e la nostra fiducia nel valore dei sistemi rispetto a tecnologie specifiche. Abbiamo dedicato tempo ed energie alla creazione di sistemi operativi che consentano l’implementazione efficace di AI/ML nel contesto di ambienti di dati complessi con obiettivi e missioni diversi (ad esempio, AI-OS). Palantir non si concentra sulla costruzione o sulla vendita di modelli AI/ML. Non ci concentriamo sulla creazione o sulla vendita di librerie AI/ML. Palantir si concentra piuttosto sulla creazione di un sistema operativo AI che consenta a un’organizzazione di utilizzare effettivamente modelli AI/ML come parte di un ecosistema di creazione di valore e miglioramento continuo. È importante sottolineare che questo approccio a livello di sistema aiuta anche a dare vita a considerazioni contestuali, inclusa l’etica che circonda l’uso della tecnologia. In questo modo, il nostro approccio aiuta a incoraggiare un’implementazione più responsabile dell’AI/ML, o di quella che viene spesso definita “AI responsabile”.
Gran parte del nostro realismo come Rivista.AI sulle tecnologie AI/ML deriva da uno scetticismo generalizzato sul fatto che ogni singola tecnologia possa fornire la soluzione miracolosa a un determinato problema, anche quando tale tecnologia ha un reale potenziale trasformativo. Lo stesso si può dire di molte delle tecnologie specifiche che compongono un ecosistema di dati: estrazione di entità, analisi predittiva, streaming di dati in tempo reale, ecc ecc.
Palantir è conosciuta principalmente per le sue due principali piattaforme software, chiamate Palantir Gotham e Palantir Foundry:
Palantir Gotham: Gotham è utilizzato principalmente dalle agenzie governative statunitensi, in particolare dalla comunità dell’intelligence e dal Dipartimento della Difesa. Aiuta con l’identificazione di modelli in set di dati altamente complessi e facilita anche la facilità di collaborazione tra analisti e operatori.
Palantir Foundry : è un sistema operativo centrale per i dati organizzativi. Il suo ruolo principale è quello di aggregare origini dati isolate in un’interfaccia comune per l’accessibilità, la gestibilità e l’analisi avanzata.
La forza lavoro di Palantir è composta principalmente da data scientist e ingegneri, e al fatto che le sue operazioni non forniranno un “momento Nvidia, come hanno suggerito alcuni analisti. Si tratta di un’azienda altamente specializzata e di nicchia in un settore avanzato ma di grande valore dell’analisi dei dati per clienti d’élite e di alto profilo.
Palantir è all’avanguardia nell’innovazione dei Digital Twins. (I Digital Twins, o gemelli digitali, sono rappresentazioni virtuali in tempo reale di oggetti, processi e sistemi1. Queste repliche virtuali di prodotti fisici forniscono una fotografia dello stato del prodotto, in tempo reale. I gemelli digitali consentono, grazie a modelli predittivi elaborati da algoritmi di Intelligenza Artificiale (AI), di prevedere le prestazioni future dell’asset fisico e di sperimentare miglioramenti senza doverli testare sul prodotto stesso)
Digital Twins Interattivo: Palantir integra l’intera gamma di dati e modelli in tutta l’azienda in una rappresentazione unificata, governata e dinamica dell’organizzazione. Questo permette di scalare gli investimenti esistenti e di potenziare il processo decisionale per gli utenti non tecnici.
Digital Twins basati su AI/ML: Palantir porta in vita il paesaggio digitale con la modellazione nativa delle azioni e dei processi nell’impresa. Questo permette di avere dettagli granulari e in tempo reale su entità ed eventi del mondo reale (ad esempio, clienti, fabbriche, ordini di lavoro, spedizioni).
Simulazioni basate su Digital Twins: Palantir permette di visualizzare e quantificare la causa e l’effetto attraverso il gemello digitale dell’organizzazione, e di simulare le condizioni future per prendere decisioni ottimali e trovare cambiamenti di impatto.
Analisi Avanzate e Flussi di Lavoro: Palantir offre applicazioni come Quiver e Vertex (da non confondere con Vertex di Google) per flussi di lavoro analitici complessi e permette alle applicazioni consapevoli degli oggetti di innescare azioni sui sistemi sottostanti, con un framework completamente governato e verificabile che garantisce la coerenza attraverso tutti i flussi di lavoro.
Simulazioni e Scenari attraverso il tuo Digital Twin: Vertex ti permette di monitorare, simulare e ottimizzare le decisioni operative basate su condizioni attuali, previste o proposte. Le simulazioni possono essere supportate da semplici regole basate sulla logica, modelli fisici, modelli di deep learning o approcci ibridi.
Queste innovazioni di Palantir nel campo dei gemelli digitali stanno rivoluzionando il modo in cui le aziende utilizzano l’AI e il ML per migliorare le loro operazioni e prendere decisioni informate.
Palantir Technologies unisce la prospettiva di un successo duraturo con l’importante lavoro di difesa degli Stati Uniti.
Palantir ha illustrato come l’intelligenza artificiale può essere applicata per la difesa nazionale e altri scopi militari. L’impiego dell’intelligenza artificiale nel settore militare è un argomento di grande dibattito. In questo contesto, i Large Language Models (LLM) e gli algoritmi devono essere implementati nel modo più etico possibile.
Palantir sostiene che la sua piattaforma AI (AIP) svolge un ruolo fondamentale in questo contesto. AIP offre funzionalità all’avanguardia di intelligenza artificiale e si impegna a garantire che l’uso di LLM e intelligenza artificiale nel contesto militare sia guidato da principi etici.
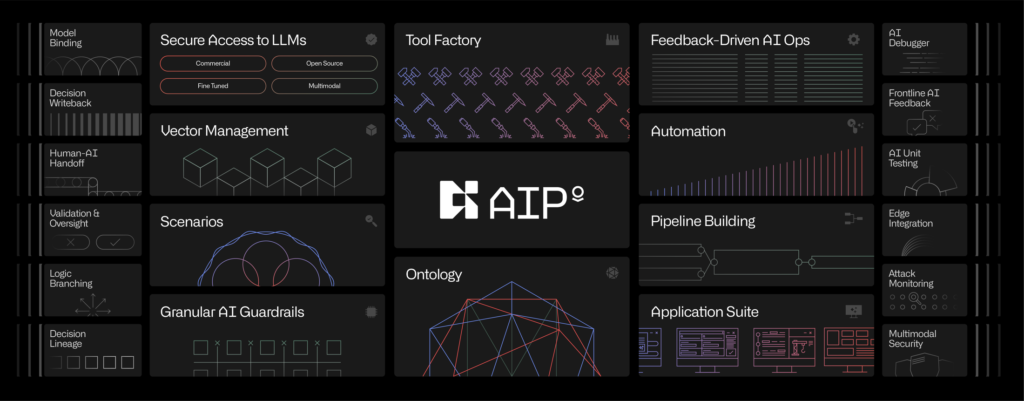
AIP può implementare LLM e IA su qualsiasi rete, dalle reti classificate ai dispositivi sul confine tattico. AIP collega dati di intelligence altamente sensibili e classificati per creare una rappresentazione in tempo reale dell’ambiente.
Le funzionalità di sicurezza della soluzione consentono di definire cosa possono e non possono vedere gli LLM e l’intelligenza artificiale e cosa possono e non possono fare con le funzioni sicure di intelligenza artificiale e trasferimento. Questo controllo e governance sono cruciali per mitigare i rischi legali, normativi ed etici significativi posti dagli LLM e dall’intelligenza artificiale in contesti sensibili e classificati.
AIP implementa anche guardrail per controllare, governare e aumentare la fiducia. Man mano che gli operatori e l’intelligenza artificiale agiscono sulla piattaforma, AIP genera un registro digitale sicuro delle operazioni. Queste capacità sono essenziali per un’implementazione responsabile, efficace e conforme dell’IA in ambito militare.
In una demo che mostra l’AIP, un operatore militare responsabile del monitoraggio dell’attività nell’Europa orientale riceve un avviso che l’equipaggiamento militare è accumulato in un campo a 30 km dalle forze amiche.
AIP sfrutta modelli linguistici di grandi dimensioni per consentire agli operatori di porre rapidamente domande come:
Quali unità nemiche ci sono nella regione? Assegna nuove immagini per questa posizione con una risoluzione di un metro o superiore Genera tre linee d’azione per prendere di mira questo equipaggiamento nemico Analizza il campo di battaglia, considerando un veicolo Stryker e un’unità delle dimensioni di un plotone Quanti missili Javelin ha il Team Omega?
Assegnare disturbatori a ciascuno degli obiettivi di comunicazione ad alta priorità convalidati Riepilogare il piano operativo Mentre l’operatore pone domande, LLM utilizza informazioni in tempo reale integrate da fonti pubbliche e classificate. I dati vengono automaticamente contrassegnati e protetti da contrassegni di classificazione e AIP impone a quali parti dell’organizzazione ha accesso LLM rispettando le autorizzazioni, il ruolo e la necessità di conoscenza di un individuo.
Ogni risposta di AIP conserva collegamenti ai record di dati sottostanti per consentire trasparenza all’utente che può indagare se necessario.
L’AIP libera la potenza di grandi modelli linguistici e di un’intelligenza artificiale all’avanguardia per le organizzazioni militari e di difesa, mirando a farlo con le barriere appropriate e gli alti livelli di etica e trasparenza richiesti per applicazioni così sensibili.
Questo mese Palantir e Oracle hanno annunciato una partnership strategica per ospitare e distribuire le piattaforme Palantir su Oracle Cloud Infrastructure.
L’approccio modulare di Oracle dovrebbe ridurre i costi del software e aumentare la disponibilità in regioni con leggi sulla privacy dei dati variabili.
Questa partnership potrebbe ridurre il processo di vendita di Palantir e consentire implementazioni più rapide e senza intoppi.
Questa partnership è allo stesso tempo sorprendente e no. Le offerte della piattaforma Palantir competono con le offerte OBIEE e OBIA di Oracle (business Intelligence) per la business intelligence e l’ottimizzazione aziendale. Sebbene questa partnership non fosse stata prevista, non dovrebbe essere vista come un campo di estrema sinistra come si potrebbe presumere. Gran parte del settore tecnologico ha lavorato verso l’integrazione incrociata anziché verso silos indipendenti per il bene dell’integrità dei dati, della sicurezza informatica e dell’esperienza del cliente.
Ciò può essere visto su varie piattaforme come Microsoft Azure e VMware in cui Microsoft compete su server virtuali, cyber e comunicazioni. Microsoft ha creato un percorso diretto per l’hosting di applicazioni cloud sulla piattaforma cloud di VMware per i clienti. Microsoft ha anche una partnership con Oracle con la quale la concorrenza è addirittura agguerrita sia per i data center hyperscaler che per le applicazioni ERP con la loro offerta Microsoft Dynamics.
Oracle sta costruendo oltre 20 data center in coordinamento con Microsoft Azure. Intel sta lavorando per fare lo stesso con la propria attività di manifatturiera, disaccoppiando il processo di progettazione e produzione entro la fine dell’anno per produrre set di chip avanzati della concorrenza.
La partnership tra Oracle e Palantir consentirà un’implementazione più fluida delle piattaforme Palantir in cui Foundry sarà ospitato su Oracle Cloud Infrastructure e Gotham e le piattaforme AI distribuibili sulla rete cloud distribuita di Oracle. Questa partnership porterà grandi benefici ad entrambe le aziende nonostante il fattore concorrenza. Credo che il management di Oracle possa vedere le applicazioni di Palantir come una potenziale minaccia per il core business del software di Oracle poiché le applicazioni AI e decisionali di Palantir potrebbero essere preferite rispetto alle applicazioni BI di Oracle.
Credo inoltre che il management di Oracle sia sufficientemente lungimirante da vedere la scritta sul muro e preferirebbe prendere una fetta della torta invece di perdere tutta. Prevedo inoltre che questa partnership aprirà le porte a Oracle per attirare vendite verso i governi sovrani mentre cercano di implementare applicazioni abilitate all’intelligenza artificiale. Considerate le profonde radici di Palantir in tutti gli enti governativi, credo che questa partnership strategica porterà benefici ad entrambe le aziende nei rispettivi rispettivi ambiti.
Di seguito un Esempio di Palantir Digital Twins :
Iscriviti alla nostra newsletter settimanale per non perdere le ultime notizie sull’Intelligenza Artificiale.
[newsletter_form type=”minimal”]

Google fa la storia chiudendo sopra i 2 trilioni di dollari.
Venerdì le azioni di Alphabet si sono mosse nettamente in rialzo – +10% – dopo che un rapporto sugli utili ricevuto dagli investitori segnalava (insieme a quello di Microsoft) che il lungo trade in Big Tech era decisamente ancora acceso.
Abbiamo visto non solo ha visto la forza del rapporto in una ripresa della pubblicità digitale, ma anche molteplici catalizzatori per un altro passo avanti nel prossimo futuro, tra cui la continua forte crescita degli annunci digitali, il probabile azzeramento della stima degli utili per azione, la possibilità per Alphabet il riacquisto fino al 4% delle sue azioni in circolazione e un nuovo dividendo che potrebbe portare una nuova classe di acquirenti.
Non solo i risultati sono stati ottimi, ma Google sta “lentamente voltando una nuova pagina ed emergendo di nuovo in testa nell’accesa corsa all’intelligenza artificiale”.
Guardando al futuro, la disponibilità generale della Search Generative Experience dell’azienda potrebbe diventare un fattore critico di espansione multipla:
“Crediamo che l’eventuale integrazione di SGE nella Ricerca Google sarà fondamentale per rafforzare la rilevanza del motore man mano che i tradizionali formati di risposta alle query migrano gradualmente verso formati di intelligenza artificiale generativa”.
I ricavi sono saliti a 80,54 miliardi di dollari, superando facilmente il consenso di 78,7 miliardi di dollari. I ricavi pubblicitari sono aumentati del 13% a 61,7 miliardi di dollari.
Nel frattempo, le entrate pubblicitarie di YouTube – in precedenza motivo di preoccupazione – sono aumentate del 21% arrivando a 8,09 miliardi di dollari. I ricavi da abbonamenti, piattaforme e dispositivi sono aumentati del 18%.
E lo slancio nel cloud è continuato, con una crescita dei ricavi del 28% e un utile operativo più che quadruplicato anno su anno.
L’utile operativo è aumentato del 46% su base annua, raggiungendo i 25,47 miliardi di dollari. L’utile per azione è stato di 1,89 dollari contro gli 1,50 dollari previsti da Wall Street. Anche il margine operativo è aumentato, al 32% rispetto al 25% di un anno fa.
“I nostri risultati nel primo trimestre riflettono le ottime prestazioni di Ricerca, YouTube e Cloud”, “Siamo a buon punto con la nostra era Gemini e c’è un grande slancio in tutta l’azienda.”
CEO S. Pichar
Nel frattempo, “l’accelerazione della crescita e del rialzo della ricerca nel secondo trimestre è stato il secondo fattore positivo del sentiment di ricerca che stavamo cercando e riteniamo che Google I/O a maggio possa mettere in mostra le capacità di intelligenza artificiale di Google per gli sviluppatori mobili”.

Il contenuto del presente articolo deve intendersi solo a scopo informativo e non costituisce una consulenza professionale. Le informazioni fornite sono ritenute accurate, ma possono contenere errori o imprecisioni e non possono essere prese in considerazione per eventuali investimenti personali. L’articolo riporta esclusivamente le opinioni della redazione che non ha alcun rapporto economico con le aziende citate.

Come evitare “un nuovo colonialismo digitale”
Non è possibile parlare di “AI per tutti” (la retorica di Google), di “AI responsabile” (la retorica di Facebook) o di “distribuire su larga scala” i suoi benefici (la retorica di OpenAI) senza riconoscere e affrontare onestamente gli ostacoli che si frappongono.
Ora una nuova generazione di studiosi sta sostenendo una “AI decoloniale” per restituire il potere dal Nord del mondo al Sud del mondo, dalla Silicon Valley alle persone. Per non rendere le Nazioni dipendenti e indebitate con le corporations e dipendenti tecnologiche dal silicio. La spesa ICT nel settore business in Italia ha raggiunto a fine 2023 quasi 39 miliardi di euro (secondo i dati Assintel) e di questo valore, una fetta intorno al 30% va “oversea“.
La nostra speranza è che questa articolo possa fornire uno spunto su come potrebbe essere l’Intelligenza Artificiale decoloniale e un invito alla riflessione, perché c’è molto altro da esplorare.
Sappiamo che l’Intelligenza Artificiale sta rivoluzionando il mondo industriale. Tuttavia, in Italia, molti si chiedono come sia possibile finanziare questa nuova rivoluzione industriale se si è sommersi dai debiti.
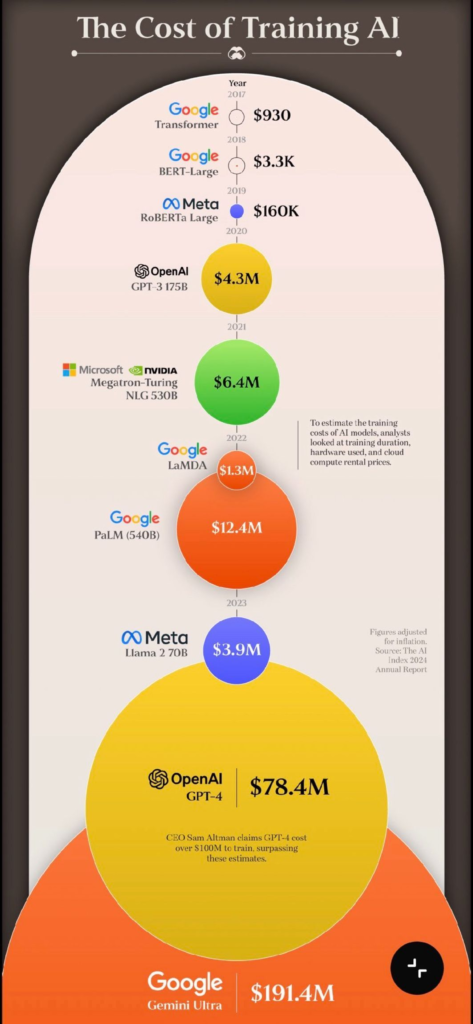
Ristrutturazione del debito: prima di tutto, è importante affrontare la questione del debito, perché l’equazione è la seguente:
Debito = < Investimenti in AI
Una delle ragioni principali per prepararci un’altra ondata di crisi del debito italiano è che tutti i fattori che potrebbero consentire al bel Paese di ridurre il proprio debito si stanno ora muovendo nella direzione sbagliata.
Per il 2024 l’Italia prevede un debito pubblico in rapporto al Pil sostanzialmente stabile rispetto al 2023, rimanendo il secondo più elevato (140,1 per cento) dopo la Grecia (152,2 per cento), l’economia italiana è circa dieci volte più grande di quella della Grecia e ha un mercato dei titoli di Stato da 3mila miliardi di dollari. Se la crisi del debito greco del 2010 ha scosso i mercati finanziari mondiali, quanto potrebbe farlo una eventuale crisi del debito italiano oggi?
Quando si tratta di valutare le prospettive economiche italiane, faremo bene a ricordare il famoso :
Se qualcosa non può andare avanti per sempre, si fermerà.
Herb Stein:
Se mai questo aforisma è vero, lo è per quanto riguarda la continua capacità dei Governi in Italia di emettere una quantità sempre maggiore di debito per coprire il proprio deficit di bilancio. Ciò è particolarmente vero quando ci sono poche prospettive che l’Italia possa mai ridurre l’entità della sua montagna di debito pubblico.
Una delle ragioni principali per prepararci ad un’altra ondata di crisi del debito italiano è che tutti i fattori che potrebbero consentire al nostro Paese di ridurre il proprio debito si stanno ora muovendo nella direzione sbagliata. Ciò deve essere particolarmente preoccupante se si considera che il rapporto debito pubblico/Pil di oggi è pari al 145%, ovvero circa 20 punti percentuali in più rispetto al periodo della crisi del debito italiano del 2012.
Per pura questione aritmetica, i tre fattori che potrebbero migliorare il peso del debito pubblico di un Paese sono un sano avanzo di bilancio primario (la differenza tra la spesa pubblica e le entrate tributarie ed extra-tributarie al netto degli interessi da pagare sul debito), tassi di interesse più bassi e un ritmo più rapido di crescita economica. Sfortunatamente, nel caso attuale dell’Italia, tutti e tre questi fattori vanno nella direzione opposta.
Nel frattempo, lungi dallo sperimentare una rapida crescita economica, l’economia italiana sembra essere sul filo di un’altra recessione economica anche grazie alle conseguenze della stretta monetaria della BCE per riprendere il controllo dell’inflazione. Una simile recessione difficilmente ispirerebbe fiducia nella capacità dell’Italia di riuscire a ridurre il proprio debito. Senza contare che dall’adesione all’Euro nel 1999, il livello del reddito pro capite italiano è rimasto pressoché invariato.
Fino a poco tempo fa, il nostro Paese aveva avuto poche difficoltà a finanziarsi a condizioni relativamente favorevoli nonostante la montagna di debito pubblico. Ciò è dovuto in gran parte al fatto che, con il suo programma quantitativo aggressivo, la BCE ha coperto quasi la totalità del fabbisogno netto di indebitamento italiano. Tuttavia, dal luglio 2023, la BCE ha completamente interrotto i suoi programmi di acquisto di obbligazioni. E ciò rende l’Italia molto più dipendente dai mercati finanziari per soddisfare le proprie esigenze di prestito.
Sfruttare le sovvenzioni e gli incentivi fiscali: l’Italia, come molti altri Paesi, offre una serie di sovvenzioni e incentivi fiscali per le aziende che investono in tecnologia e innovazione.
Secondo l’Osservatorio sulle politiche in materia di AI dell’OCSE, numerosi Paesi e territori, inclusa l’Unione Europea, hanno introdotto iniziative per le politiche sull’Intelligenza Artificiale .
Anche l’Italia ha fatto la sua parte, pubblicando tre piani programmatici multisettoriali nel 2020 e nel 2021.
Il primo è stato reso ufficiale dal Ministero dello Sviluppo Economico durante il Governo Conte II, mentre il secondo è stato diffuso congiuntamente dal Ministero per l’Innovazione Tecnologica e la Transizione Digitale, dal Ministero dello Sviluppo Economico e dal Ministero dell’Università e della Ricerca durante il Governo Draghi e per ultimo il piano annunciato dall’attuale Premier Meloni assieme al un coinvolgimento di Cassa Depositi e Prestiti.
Il fatto che siano stati necessari 3 piani in così poco tempo potrebbe essere attribuito all’instabilità politica dell’Italia e alla volontà del nuovo Governo di adattare le politiche sull’AI al nuovo contesto politico. In ogni caso, nel frattempo abbiamo nominato, ovviamente, 3 commissioni diverse, quindi abbiamo “parzialmente” ricominciato tutto da capo ogni volta.
Ora, ancora una volta il successo della nuova strategia nazionale dipende dall’attuazione di queste nuove iniziative, poiché sono strettamente interconnesse.
Sulla carta c’è un fondo da un miliardo sull’Intelligenza Artificiale. È forse questo l’investimento più atteso del piano industriale 2024-28 di Cdp Venture Capital sgr.
Ma quale è la situazione lato imprese?
In Italia, circa la metà delle grandi aziende (49%)
Osservatorio Artificial Intelligence
ha iniziato a riflettere sulle potenzialità e sugli impatti della Generative AI e il 17% ha già all’attivo
progettualità sul tema. Le piccole e medie imprese, invece, rimangono per lo più escluse dal percorso:
soltanto il 7% sta riflettendo su potenziali applicazioni e, ancor meno (2%) ha concretamente attivato
effettive sperimentazioni o iniziative.
Come faccio ad aumentare questi numeri senza ingenti investimenti pubblici, si controllati per non prendere scivoloni come per il super bonus, ma non iper burocratizzati?
Abbiamo a disposizione 1 miliardo contro i 7 della Germania e della Francia e guardando al Regno Unito, anche se fuori dall’UE, notiamo che è il terzo mercato di Intelligenza Artificiale al mondo dopo Stati Uniti e Cina, con una valutazione attuale di 21 miliardi di dollari, che si stima raggiungerà i mille miliardi di dollari entro il 2035.
Al di fuori dei confini UE notiamo altresì che la tecnologica locale di Israele si è affermata in prima linea nello sviluppo dell’Intelligenza Artificiale, raggiungendo 11 miliardi di dollari di investimenti privati tra il 2013 e il 2022 (Mirae Asset), il quarto più alto al mondo.
Ovviamente gli Stati Uniti sono il paese più prolifico nella ricerca sull’Intelligenza Artificiale, con Macro Polo che rileva che quasi il 60% dei ricercatori di “alto livello” sull’Intelligenza Artificiale lavora per Università e aziende americane, e Mirae Assets che suggerisce che fino ad oggi sono stati raccolti 249 miliardi di dollari in finanziamenti privati.
Non ci sorprende infine che il secondo contributore più significativo alla ricerca sull’Intelligenza Artificiale al mondo sia la Cina, che ha l’11% dei ricercatori di alto livello impegnati sull’Intelligenza Artificiale (Macro Polo), 232 investimenti legati alle tematiche dell’AI nel 2023 e che ha raccolto 95 miliardi di dollari in investimenti privati tra il 2022 e il 2023 (sempre secondo i dati Mirae).
Sembrerebbe una battaglia con i fucili di legno a guardarla così, sia per il nostro Paese ma anche per l’UE nel suo complesso:
Guardando all’adozione da parte delle organizzazioni, circa 6 grandi imprese su 10 (61%) dichiarano di avere
Osservatorio Artificial Intelligence
all’attivo – almeno a livello di sperimentazione – progetti di Intelligenza Artificiale. L’adozione scende al 18%
tra le piccole e medie imprese (+3 punti percentuali rispetto al 2022). L’adozione nelle imprese è dunque
sostanzialmente stabile rispetto al 2022, ma ciò non deve essere letto in contrasto con la crescita del mercato.
Infatti, le aziende che avevano già avviato almeno una sperimentazione proseguono e accelerano.
Contrariamente alle aspettative, l’avvento della Generative AI non sembra aver influenzato il percorso di
avvicinamento all’AI di quelle aziende che non hanno ancora adottato la tecnologia: mentre per le aziende
più mature è il 33%
Anche se la strada per finanziare la rivoluzione dell’AI può sembrare ardua, ci sono molte strategie che possono essere adottate per navigare tra i debiti e finanziare l’innovazione. Con la giusta pianificazione e strategia, la rivoluzione dell’Intelligenza Artificiale può diventare una realtà anche per coloro che attualmente si trovano in una situazione di debito.
Per chi volesse guardarsi i numeri dell’AI in Italia c’è un’interessante Contributo dell’Osservatorio Artificial Intelligence all’Indagine Conoscitiva sull’Intelligenza Artificiale: opportunità e rischi per il sistema produttivo italiano, che riportiamo sotto.
A voi le conclusioni.
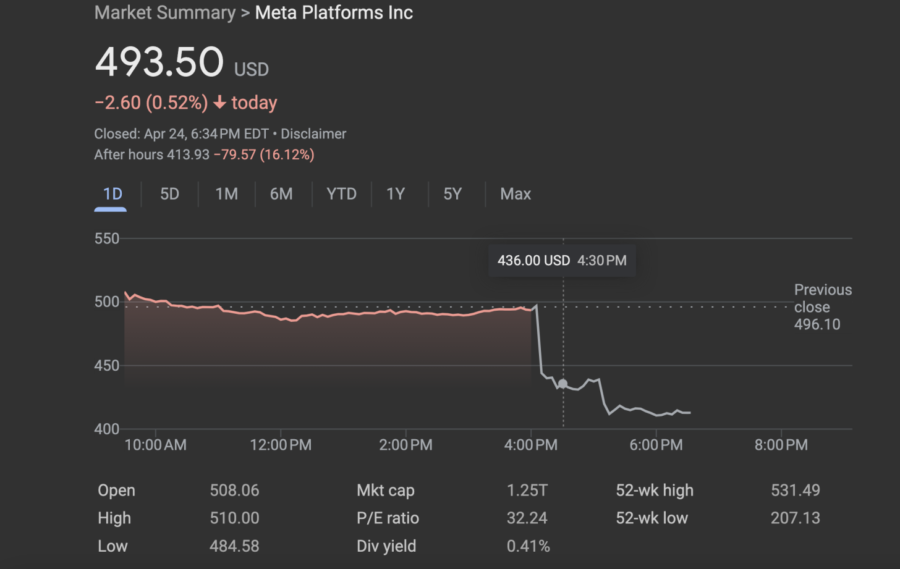
Meta Platforms ha scosso il mondo degli investitori con le sue previsioni per il prossimo trimestre, che sono risultate più deboli del previsto. Inoltre, ha annunciato che si troverà in una fase di investimenti per un periodo prolungato a causa dell’accelerazione dei salari nell’intelligenza artificiale.
“Nel complesso, considero i risultati che i nostri team hanno ottenuto qui come un’altra pietra miliare fondamentale nel dimostrare che abbiamo il talento, i dati e la capacità di scalare l’infrastruttura per costruire modelli e servizi di intelligenza artificiale leader a livello mondiale”, ha affermato Zuckerberg. “E questo mi porta a credere che dovremmo investire molto di più nei prossimi anni per costruire modelli ancora più avanzati e servizi di intelligenza artificiale su scala più ampia al mondo.”
Mark Zuckerberg.
Nonostante le azioni siano crollate di circa il 19% a seguito di queste notizie, gli analisti di Wall Street hanno difeso la società guidata da Mark Zuckerberg.
“Storicamente, investire per creare queste nuove esperienze su larga scala nelle nostre app è stato un ottimo investimento a lungo termine per noi e per gli investitori che sono rimasti con noi e anche qui i segnali iniziali sono piuttosto positivi”.
Zuckerberg
Un po’ come un Messia seguitemi e sarete ricompensati.
Ha aggiunto che la costruzione di un’intelligenza artificiale leader sarà un’impresa più grande rispetto alle altre esperienze che hanno aggiunto alle loro app e che probabilmente richiederà diversi anni.
“Realisticamente, anche spostando molte delle nostre risorse esistenti per concentrarci sull’intelligenza artificiale, la nostra dotazione di investimenti aumenterà comunque in modo significativo prima di ottenere entrate significative da alcuni di questi nuovi prodotti”,
Zuckerberg
Meta ha annunciato che ora prevede spese per l’intero anno comprese tra 94 e 99 miliardi di dollari a causa di “maggiori costi infrastrutturali e legali”.
(Proprio ieri, Meta ottiene il parere sfavorevole dell’avvocato generale nel caso relativo ai dati sull’orientamento sessuale nell’UE)
Le spese in conto capitale per l’intero anno saranno comprese tra 35 e 40 miliardi, rispetto a un precedente range compreso tra 30 e 37 miliardi,
“mentre continuiamo ad accelerare i nostri investimenti infrastrutturali per supportare la nostra tabella di marcia sull’intelligenza artificiale”.
Zuckerberg
Meta genera il 98% delle sue entrate dalla pubblicità digitale. Ma quando Zuckerberg parlava di pubblicità, guardava al futuro e ai modi in cui l’azienda avrebbe potuto potenzialmente trasformare i suoi attuali investimenti in dollari pubblicitari.
“Esistono diversi modi per creare un business enorme qui, tra cui il ridimensionamento della messaggistica aziendale, l’introduzione di annunci o contenuti a pagamento nelle interazioni dell’IA”.
Zuckerberg
DATA MONETIZATION. Detta cosi’ sembrerebbe che non ha molto interesse a sviluppare GENAI, ma piuttosto come sempre per META a raccogliere dati dell’utente per vendere Pubblicita’, quello che gli Analisti chiamano (l’AI) un business collateral(e). Come le TV private dove spesso i programmi sono collaterali alla pubblicita’.
“Nonostante tutti gli audaci piani di intelligenza artificiale di Meta, non può permettersi di distogliere lo sguardo dal nucleo del business: le sue attività pubblicitarie principali”, ha detto mercoledì in una nota Sophie Lund-Yates , analista di Hargreaves Lansdown. “Ciò non significa ignorare l’intelligenza artificiale, ma significa che la spesa deve essere mirata e in linea con una chiara visione strategica”.
Speriamo che ci sia spazio per il rispetto delle regole e dell’etica, non come e successo in passato, aggiungiamo noi.
Vale la pena sottolineare che Meta ha notato la volatilità delle azioni durante tali fasi di investimento nel playbook del prodotto, infatti ha aggiunto:
“dove stiamo investendo nell’ampliamento di un nuovo prodotto, non lo stiamo ancora monetizzando. Lo abbiamo visto con Reels, storie, man mano che il feed di notizie passa ai dispositivi mobili e altro ancora, e mi aspetto anche di vedere un ciclo di investimenti pluriennale prima di adattare completamente le API aziendali AI e altro ancora ai servizi redditizi che mi aspetto.”
Zuckerberg
Passando agli sforzi ben pubblicizzati di Meta per potenziare il metaverso, Zuckerberg ha affermato che è interessante il modo in cui il tema si sovrappone ora all’intelligenza artificiale.
Nel frattempo, l’unità Reality Labs di Meta , che ospita l’hardware e il software dell’azienda per lo sviluppo del nascente metaverso, continua a dissanguare denaro.
Reality Labs ha registrato vendite per 440 milioni di dollari nel primo trimestre e perdite per 3,85 miliardi di dollari. Le perdite cumulative della divisione dalla fine del 2020 hanno superato i 45 miliardi di dollari.
Zuckerberg oltre di Llama3 ha anche parlato degli occhiali AR di Meta, che ha definito “il dispositivo ideale per un assistente AI perché puoi far loro vedere ciò che vedi e sentire ciò che senti”.
“Questo è più chiaro quando si guardano gli occhiali”, “Sai, pensavo che gli occhiali [per la realtà aumentata] non sarebbero stati davvero un prodotto mainstream finché non avessimo avuto display olografici completi, e penso ancora che sarà fantastico e sarà uno stato maturo a lungo termine per il prodotto. Ma ora sembra abbastanza chiaro che esista un mercato significativo anche per gli occhiali AI alla moda senza display.”
Zuckerberg

Per chi volesse approfondire di seguito la trascrizione.
Il contenuto del presente articolo deve intendersi solo a scopo informativo e non costituisce una consulenza professionale. Le informazioni fornite sono ritenute accurate, ma possono contenere errori o imprecisioni e non possono essere prese in considerazione per eventuali investimenti personali. L’articolo riporta esclusivamente le opinioni della redazione che non ha alcun rapporto economico con le aziende citate.

Lanciata nel 2020, la Rome Call ha riunito originariamente la Pontificia Accademia, i leader di Microsoft e IBM il governo italiano e l’Organizzazione delle Nazioni Unite per l’alimentazione e l’agricoltura per promuovere scelte etiche nello sviluppo della tecnologia , norme legali per regolamentarla e sforzi educativi per aiutare le persone a comprendere l’intelligenza artificiale e il suo ruolo in una vasta gamma di applicazioni.
Oggi anche Cisco nella persona dell Presidente Chuck Robbins dopo aver brevemente incontrato Papa Francesco ha aderito alla iniziativa.
Siamo molto lieti che Cisco abbia aderito alla Rome Call, perché è un’azienda che svolge un ruolo cruciale come partner tecnologico per l’adozione e l’implementazione dell’intelligenza artificiale (AI), offrendo competenze in infrastrutture, sicurezza e protezione dei beni Dati e sistemi di intelligenza artificiale. D’ora in poi valuteremo come questa possa crescere ulteriormente per coniugare l’impegno aziendale già presente con i principi etici della Rome Call
presidente della Fondazione RenAIssance, mons. Vincenzo Paglia.
I firmatari stanno inoltre spingendo per lo sviluppo dell “algoretica”, un quadro etico per garantire che gli algoritmi utilizzati per costruire sistemi artificialmente intelligenti promuovano ciò che è vero, giusto ed etico.
L’algoretica è un termine coniato dal teologo Paolo Benanti. L’algoretica fonde l’algoritmo con l’etica e si pone come una nuova branca dell’etica che si dedica a esaminare gli aspetti morali degli algoritmi e dei sistemi basati sull’intelligenza artificiale1.
Il Rome Call for AI Ethics è un documento di grande importanza, firmato per la prima volta il 28 febbraio 2020. Questo documento è stato sviluppato per sostenere un approccio etico all’Intelligenza Artificiale (AI) e promuovere un senso di responsabilità tra organizzazioni, governi, istituzioni e il settore privato.
Pontificia Accademia per la Vita
La Pontificia Accademia per la Vita ha giocato un ruolo fondamentale nella creazione del Rome Call for AI Ethics. Questa accademia, con sede nello Stato della Città del Vaticano, è stata istituita da Papa Giovanni Paolo II con il motu proprio Vitae mysterium, l’11 febbraio 1994. Ha come fine la difesa e la promozione del valore della vita umana e della dignità della persona.
Fondazione RenAIssance
La Fondazione RenAIssance, istituita da Papa Francesco nel 2021, ha promosso il Rome Call for AI Ethics. Questa fondazione, con sede nella Città del Vaticano, presso la Pontificia Accademia per la Vita, è un’entità strumentale di tale Accademia. La Fondazione RenAIssance è un’organizzazione senza scopo di lucro con l’obiettivo di sostenere la riflessione antropologica ed etica delle nuove tecnologie sulla vita umana, promossa dalla Pontificia Accademia per la Vita.
Principi del Rome Call for AI Ethics
Il Rome Call for AI Ethics comprende 3 aree di impatto e 6 principi:
Aree di Impatto
- Etica: Tutti gli esseri umani nascono liberi e uguali in dignità e diritti.
- Educazione: Trasformare il mondo attraverso l’innovazione dell’IA significa impegnarsi a costruire un futuro per e con le generazioni più giovani.
- Diritti: Lo sviluppo dell’IA al servizio dell’umanità e del pianeta deve essere riflesso in regolamenti e principi che proteggono le persone, in particolare i deboli e i meno privilegiati, e gli ambienti naturali.
Principi
- Trasparenza: I sistemi di IA devono essere comprensibili per tutti.
- Inclusione: Questi sistemi non devono discriminare nessuno, poiché ogni essere umano ha pari dignità.
- Responsabilità: Deve sempre esserci qualcuno che si assume la responsabilità di ciò che una macchina fa.
- Imparzialità: I sistemi di IA non devono seguire o creare pregiudizi.
- Affidabilità: L’IA deve essere affidabile.
- Sicurezza e Privacy: Questi sistemi devono essere sicuri e rispettare la privacy degli utenti.
Rome Call for AI Ethics è un passo importante verso un futuro in cui l’innovazione digitale e il progresso tecnologico servono il genio e la creatività umana, e non il loro graduale rimpiazzo. Questo documento rappresenta un appello a riconoscere e poi a assumere la responsabilità che deriva dalla moltiplicazione delle opzioni rese possibili dalle nuove tecnologie digitali.
L’intelligenza artificiale generativa (GenAI) è un campo affascinante caratterizzato da una vasta e variegata offerta di soluzioni fornite da una molteplicità di attori. Le imprese che si avventurano nell’implementazione della GenAI devono navigare attraverso un complesso ecosistema di fornitori, che comprende produttori di modelli di base, sviluppatori di piattaforme AI, specialisti nella gestione dei dati, fornitori di strumenti per la personalizzazione dei modelli e molti altri.
Ciò che sorprende è che, nonostante il dominio delle grandi aziende di cloud computing nel panorama IT degli ultimi dieci anni, il loro ruolo centrale nel settore della GenAI non è stato così marcato come inizialmente previsto. Almeno finora. Ma ci sono segnali che la situazione potrebbe cambiare. Google ha recentemente tenuto un impressionante evento Cloud Next in cui l’azienda ha presentato un’ampia gamma di funzionalità basate su GenAI.
Siamo ancora in una fase embrionale per quanto riguarda le implementazioni di GenAI, e molte organizzazioni stanno appena cominciando a delineare la propria strategia e il metodo di attuazione. È diventato evidente, tuttavia, che molte aziende stanno riconoscendo l’importanza di avere software e servizi GenAI integrati con le loro fonti di dati primarie.
Considerando l’abbondanza di dati ospitati nel cloud AWS, molte di queste organizzazioni vedranno con favore le nuove funzionalità migliorate offerte da AWS, poiché possono agevolare la creazione e l’ottimizzazione dei modelli GenAI, specialmente con tecnologie come RAG.
Per le aziende che dipendono pesantemente dai servizi di archiviazione dati di AWS per l’addestramento e l’affinamento dei propri modelli GenAI, l’introduzione di queste nuove funzionalità Bedrock potrebbe essere un incentivo significativo per rilanciare i loro progetti applicativi GenAI.
È probabile che assistiamo anche alla crescita delle implementazioni di piattaforme multi-GenAI. Come le imprese hanno imparato che l’adozione di più fornitori di cloud era vantaggiosa dal punto di vista economico, logistico e tecnico, è possibile che si adotti un approccio analogo per sfruttare le diverse piattaforme GenAI per soddisfare le esigenze di diverse tipologie di applicazioni. Sebbene la competizione sia ancora in corso, è evidente che tutti i principali fornitori di cloud computing stanno cercando di affermarsi come player rilevanti anche in questo settore.
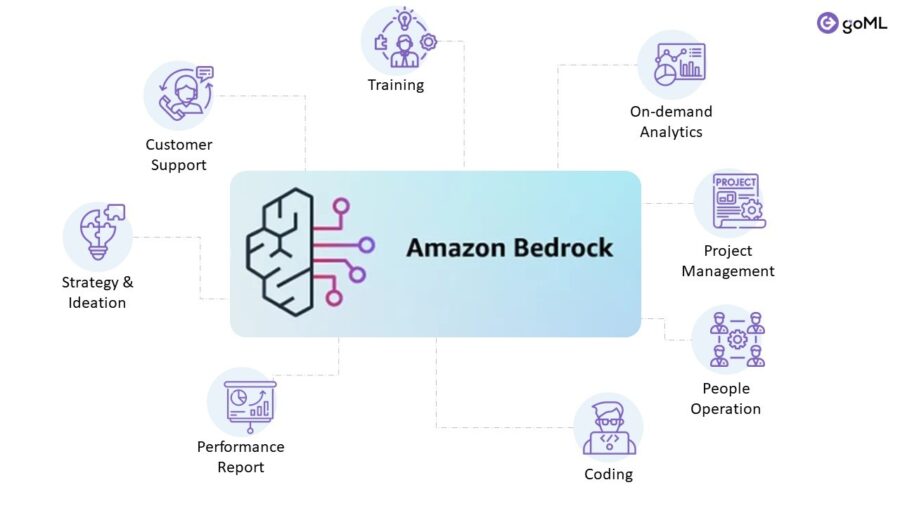
La divisione AWS di Amazon sta svelando una serie di nuove funzionalità e miglioramenti per il suo servizio completamente gestito Bedrock GenAI.
Amazon Bedrock è un servizio completamente gestito che offre una scelta di modelli di fondazione (FM) ad alte prestazioni delle principali aziende di IA, come AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI e Amazon, tramite un’unica API, insieme ad un’ampia gamma di funzionalità necessarie per creare applicazioni di IA generativa, utilizzando l’IA in modo sicuro, riservato e responsabile
Nello specifico, Amazon sta aggiungendo la possibilità di importare modelli di fondazione personalizzati nel servizio e quindi consentire alle aziende di sfruttare le capacità di Bedrock attraverso tali modelli personalizzati.
Le aziende che hanno addestrato un modello open source come Llama o Mistral con i propri dati potenzialmente con lo strumento di sviluppo del modello SageMaker di Amazon possono ora integrare quel modello personalizzato insieme ai modelli standardizzati esistenti all’interno di Bedrock.
Come risultato possono utilizzare un’unica API per creare applicazioni che attingono ai loro modelli personalizzati e alle opzioni dei modelli Bedrock esistenti, tra cui le ultime novità di AI21 Labs, Anthropic, Cohere, Meta e Stability AI, nonché i modelli Titan di Amazon.
Amazon ha anche introdotto la versione 2 del suo modello Titan Text Embeddings, che è stato specificamente ottimizzato per le applicazioni RAG.
Uno degli altri vantaggi dell’importazione di modelli personalizzati in Bedrock è la capacità di sfruttare le funzioni RAG integrate del servizio. Ciò consente alle aziende di sfruttare questa nuova tecnologia sempre più popolare per continuare a perfezionare i propri modelli personalizzati con nuovi dati.
La società ha inoltre annunciato la disponibilità generale del suo modello Titan Image Generator.
Poiché è serverless, Bedrock ha funzionalità integrate per scalare senza problemi le prestazioni dei modelli anche tra le istanze AWS, consentendo alle aziende di gestire più facilmente le proprie richieste in tempo reale in base alla situazione.
Le organizzazioni che desiderano creare agenti basati sull’intelligenza artificiale in grado di eseguire attività in più fasi, Bedrock offre anche strumenti che consentono agli sviluppatori di crearli e alle aziende di attingere ai loro modelli personalizzati mentre lo fanno.
Gli agenti sono attualmente uno degli argomenti di discussione più caldi in GenAI, quindi questo tipo di funzionalità è destinato a interessare quelle organizzazioni che vogliono rimanere all’avanguardia. Oltre a queste funzionalità esistenti per Bedrock, Amazon ne ha annunciate altre due, entrambe estensibili ai modelli Bedrock esistenti e anche ai modelli importati personalizzati.
Il Guardrails per Amazon Bedrock aggiunge un ulteriore set di funzionalità di filtro per impedire la creazione e il rilascio di contenuti inappropriati e dannosi, nonché di informazioni personali e/o sensibili.
Praticamente tutti i modelli incorporano già un certo grado di filtraggio dei contenuti, ma i nuovi Guardrail forniscono un ulteriore livello di prevenzione personalizzabile per aiutare le aziende a proteggersi ulteriormente da questo tipo di problemi e garantire che i contenuti generati siano conformi alle linee guida del cliente.
Inoltre, lo strumento di valutazione dei modelli di Amazon all’interno di Bedrock è ora generalmente disponibile. Questo strumento aiuta le organizzazioni a trovare il miglior modello di base per la particolare attività che stanno cercando di realizzare o per l’applicazione che stanno cercando di scrivere.
Il valutatore confronta caratteristiche standard come l’accuratezza e la robustezza delle risposte di diversi modelli. Consente inoltre la personalizzazione di diversi criteri chiave.
Le aziende possono, ad esempio, caricare i propri dati o una serie di suggerimenti personalizzati sul valutatore e quindi generare un report che confronti il comportamento dei diversi modelli in base alle loro esigenze personalizzate.
Amazon offre anche un meccanismo per consentire agli esseri umani di valutare diversi output del modello per misurazioni soggettive come la voce del marchio, lo stile, ecc. Questa valutazione del modello è una capacità importante perché mentre molte aziende potrebbero inizialmente essere attratte da una piattaforma a modello aperto come Bedrock grazie alla gamma delle diverse scelte che offre, quelle stesse scelte possono rapidamente diventare confuse e travolgenti.

Secondo una ricerca condotta da Microsoft, circa l’88% delle lingue parlate nel mondo, che coinvolgono 1,2 miliardi di persone, non ha accesso ai Large Language Models (LLM). Perchè sono costruiti principalmente utilizzando dati in lingua inglese e per utenti di madrelingua inglese: “di conseguenza, la distinzione tra chi ha e chi non ha è diventata piuttosto netta“. La soluzione a questo problema risiede nell’implementazione di LLM multilingue, che possano essere allenati in diverse lingue e utilizzati per compiti in diverse lingue.
Il gruppo di ricerca Sapienza NLP (Natural Language Processing), guidato da Roberto Navigli, professore ordinario presso il Dipartimento di Ingegneria Informatica, Automatica e Gestionale “Antonio Ruberti” della Sapienza Università di Roma, annuncia oggi il rilascio dei modelli Minerva, una nuova famiglia di modelli linguistici su larga scala (Large Language Model, LLM) addestrati “da zero” per la lingua italiana.

Minerva è la prima famiglia di LLM italiano-inglese veramente aperti (dati e modello) preformati da zero, un modello da 350 milioni di parametri addestrato su 70 miliardi di token (35 miliardi in italiano, 35 miliardi in inglese), sviluppata da Sapienza NLP in collaborazione con Future Artificial Intelligence Research (FAIR) e CINECA . In particolare, circa la metà dei dati pre-formazione include testo in italiano.
Questo lavoro è stato finanziato dal progetto PNRR MUR PE0000013-FAIR . Riconosciamo il premio CINECA “IscB_medit” nell’ambito dell’iniziativa ISCRA, per la disponibilità di risorse e supporto informatico ad alte prestazioni.
“La caratteristica distintiva dei modelli Minerva è il fatto di essere stati costruiti e addestrati da zero usando testi ad accesso aperto, al contrario dei modelli italiani esistenti ad oggi, che sono basati sull’adattamento di modelli come LLaMA e Mistral, i cui dati di addestramento sono tuttora sconosciuti”
“Nello specifico, ogni modello Minerva è stato addestrato su un vasto insieme di fonti italiane e inglesi online e documentate, per un totale di oltre 500 miliardi di parole, l’equivalente di oltre 5 milioni di romanzi”.
“Non solo la trasparenza nell’addestramento dei modelli rafforza la fiducia degli utenti, della comunità scientifica, degli enti pubblici e dell’industria, ma stimola anche continui miglioramenti ed è un primo passo verso processi di verifica rigorosi per garantire la conformità a leggi e regolamenti”.
Roberto Navigli.
Il team di PNL della Sapienza
- Riccardo Orlando: preelaborazione dei dati, training del modello
- Pere-Lluis Huguet Cabot: preelaborazione dei dati, vocabolario, valutazione
- Luca Moroni: data curation, analisi dei dati, compiti downstream, valutazione
- Simone Conia: data curation, valutazione, supervisione del progetto
- Edoardo Barba: preelaborazione dati, attività downstream, supervisione del progetto
- Roberto Navigli: coordinatore del progetto

Durante la recente teleconferenza sugli utili, Elon Musk, CEO di Tesla, ha espresso le sue opinioni su vari argomenti. Ha riconosciuto che l’adozione globale di veicoli elettrici sta affrontando delle sfide, ma ha mantenuto la sua convinzione che, nel lungo periodo, i veicoli elettrici prenderanno il sopravvento nell’industria automobilistica.
| Q1 2024 Actual | Analyst Estimates for Q1 2024 | Q1 2023 | Year-Over-Year Change | |
|---|---|---|---|---|
| Revenue | $21.3 billion | $22.25 billion | $23.33 billion | (9%) |
| Adjusted Diluted Earnings / (Loss) Per Share | 45 cents | 52 cents | 85 cents | (47%) |
| Adjusted Net Income / (Loss) | $1.54 billion | $1.88 billion | $2.93 billion | (48%) |
Musk ha inoltre annunciato che nuovi modelli di auto saranno lanciati nella prima metà del 2025, o forse già alla fine del 2024. Questi nuovi modelli incorporeranno elementi della tecnologia autonoma di Tesla e saranno prodotti utilizzando le linee di produzione esistenti. Tuttavia, Musk non ha voluto rivelare se questi nuovi modelli saranno versioni aggiornate dei modelli attuali.
Parlando della Full Self-Driving (FSD), Musk ha elogiato le caratteristiche dell’ultima versione.
Secondo lui, una rete neurale con telecamere è la soluzione ideale per la FSD. Ha anche sottolineato che la potenza di calcolo dell’intelligenza artificiale di Tesla sta progredendo rapidamente. Musk ha rivelato che Tesla è attualmente in trattative con almeno un grande produttore di automobili per concedere in licenza la tecnologia FSD.
Rispondendo a una domanda sul robot umanoide Optimus, Musk ha dichiarato che prevede che Tesla sarà in grado di iniziare a vendere questi robot entro la fine del prossimo anno. Ha anche espresso la sua convinzione che Optimus potrebbe diventare la più grande attività di Tesla.
Tesla aveva affermato che Optimus è alimentato dallo stesso software della funzionalità di guida autonoma delle sue auto, per le quali Tesla ha sviluppato i propri chip, sia all’interno del veicolo che nel supercomputer (Dojo) utilizzato per l’allenamento. i modelli. Certamente, queste capacità di deep learning (sia hardware che software), che sono così cruciali per rendere utili i robot umanoidi, sono al di fuori del dominio di tutte le altre aziende di robotica. È qui che nasce l’attrattiva e la differenziazione dell’ingresso di Tesla in questo mercato.
Musk ha apprezzato gli sforzi di altre case automobilistiche nel creare un percorso per le approvazioni normative sulla guida autonoma.
Ha citato dati che dimostrano che la guida autonoma è più sicura della guida umana. Ha immaginato un futuro in cui esiste una flotta di robotaxi, una sorta di ibrido tra Uber e Airbnb, con i clienti e la società con sede ad Austin che gestiscono entrambe le parti della flotta. Musk ha affermato:
“In futuro, le auto a benzina che non saranno autonome saranno come andare a cavallo e usare un telefono cellulare, e questo diventerà molto ovvio”.
E.Musk
Il punto è che tutti questi esempi appartengono al dominio del software, non dell’hardware, e che è alimentato da chip di silicio. Come alcuni hanno sostenuto, avere semplicemente un robot che assomigli a un essere umano o una automobile che si guida da soloenon è sufficiente, deve anche essere in grado di fare le cose che un essere umano può fare. Ebbene, data l’ascesa dell’intelligenza artificiale, questo sta diventando un ambito possibile.
Il contenuto del presente articolo deve intendersi solo a scopo informativo e non costituisce una consulenza professionale. Le informazioni fornite sono ritenute accurate, ma possono contenere errori o imprecisioni e non possono essere prese in considerazione per eventuali investimenti personali. L’articolo riporta esclusivamente le opinioni della redazione che non ha alcun rapporto economico con le aziende citate.

l CEO di Meta, Mark Zuckerberg, ha lasciato intendere che la sua azienda sta facendo progressi sulle sue prime “interfacce neurali di consumo”, dispositivi indossabili non invasivi in grado di interpretare i segnali cerebrali per controllare i computer. Brain Computer Interface (BCI)
“Una delle cose di cui sono piuttosto entusiasta: penso che presto inizieremo a ottenere alcune interfacce neurali di consumo.
Mark Zuckerberg, a differenza del chip cerebrale Neuralink di Elon Musk, ha spiegato che i dispositivi in questione non sarebbero qualcosa che “si collega al tuo cervello”, ma un dispositivo indossabile al polso in grado di “leggere i segnali neurali che il tuo cervello invia attraverso i tuoi nervi alla tua mano per muoverla in modi sottili”.
Meta ha iniziato a discutere dello sviluppo dell’“interazione basata sul polso” nel marzo 2021 come parte della ricerca di Facebook Reality Labs.
Il braccialetto di Meta funziona utilizzando l’elettromiografia (EMG) per interpretare i segnali cerebrali relativi ai gesti della mano desiderati e tradurli in comandi per controllare i dispositivi.
“Siamo fondamentalmente in grado di leggere quei segnali e usarli per controllare occhiali o altri dispositivi informatici”, .
Mark Zuckerberg
I commenti più recenti sono arrivati durante un’intervista il 18 aprile tra il co-fondatore di Facebook e l’imprenditore tecnologico e il YouTuber Roberto Nickson.
“Siamo ancora all’inizio del viaggio perché non abbiamo ancora lanciato la prima versione del prodotto, ma giocarci internamente è… è davvero interessante vedere”.
All’inizio di quest’anno, l’AD di Meta ha detto che questo braccialetto neurale potrebbe diventare un prodotto di consumo in pochi anni, utilizzando l’intelligenza artificiale per superare i limiti del tracciamento dei gesti basato su telecamera.
Mark Zuckerberg ha anche immaginato che le interfacce neurali funzionino con gli occhiali intelligenti con realtà aumentata Ray-Ban di Meta. Commentando gli occhiali intelligenti dell’azienda, ha detto che la “funzione Hero ” era l’integrazione dell’IA in essi.
“Siamo davvero vicini ad avere un’IA multimodale […] quindi non le fai solo una domanda con testo o voce; puoi chiederle delle cose che stanno succedendo intorno a te, e può vedere cosa sta succedendo e rispondere alle domande […] è piuttosto selvaggio”, ha aggiunto.
Nel frattempo, i legislatori negli Stati Uniti stanno già lavorando su una legislazione volta a proteggere la privacy nel nascente campo della neurotecnologia.
La Protect Privacy of Biological Data Act, che espande la definizione di “dati sensibili” per includere dati biologici e neurali, è stata approvata in Colorado questa settimana, secondo quanto riportato.
In altre notizie, Meta ha appena rilasciato una nuova versione di Meta AI, l’assistente che opera attraverso le applicazioni e gli occhiali dell’azienda. “Il nostro obiettivo è costruire l’IA leader nel mondo”, ha detto Zuckerberg.
Meta AI viene aggiornata con il nuovo modello di IA “Llama 3 all’avanguardia, che stiamo rendendo open source”, ha aggiunto.

Il mercato ha attraversato una settimana turbolenta, culminata con una sessione di venerdì segnata dal brusco calo delle azioni di Netflix , che ha influito negativamente sul settore tecnologico, e dalle tensioni geopolitiche tra Iran e Israele, che hanno tenuto gli investitori con il fiato sospeso.
Richard Hunter di Interactive Investor ha notato che i titoli tecnologici sono stati particolarmente colpiti alla fine di una settimana altamente volatile, con parte dei recenti guadagni cancellati dopo un periodo di crescita eccezionale per le azioni legate all’intelligenza artificiale.
La situazione attuale dei mercati è piuttosto confusa, con una grande incertezza riguardo agli eventi in corso in Medio Oriente, una significativa vendita nel settore tecnologico americano, che non si verificava da circa 18 mesi, e un aumento dei rendimenti mentre i tagli dei tassi di interesse vengono sempre più messi da parte,” ha aggiunto Jim Reid di Deutsche Bank.
Dopo un venerdì tumultuoso caratterizzato da vendite aggressive, lunedì i titoli legati all’intelligenza artificiale sembravano trovare una certa stabilità in vista dei prossimi annunci di utili.
Richard Hunter di Interactive Investor ha notato che i titoli tecnologici, in particolare quelli con una forte esposizione all’intelligenza artificiale, hanno subito un deciso calo dopo un periodo di forte crescita. Tuttavia, lunedì le azioni di Nvidia sono aumentate di quasi il 2%, nonostante il declassamento da parte di UBS da Overweight a Neutral, ribaltando la tendenza negativa degli utili. Venerdì, il titolo aveva subito una perdita superiore al 10%.
Nvidia, che pubblicherà i suoi risultati del primo trimestre il 22 maggio, ha previsto un aumento significativo dell’EPS e dei ricavi rispetto all’anno precedente.
Altre società del settore, come Super Micro Computer e Astera Labs , hanno mostrato una performance altalenante. Super Micro Computer è sceso di oltre il 2% lunedì, aggiungendosi al crollo del 23% di venerdì, mentre Astera Labs è salito del 2% dopo un calo del 9% venerdì.
Arm, una società britannica di progettazione di chip, ha registrato un aumento del 4,2%, recuperando parte delle perdite del giorno precedente. Anche altre società del settore, come Qualcomm (QCOM), Broadcom e Texas Instruments hanno registrato aumenti nella giornata di lunedì.
Il contenuto del presente articolo deve intendersi solo a scopo informativo e non costituisce una consulenza professionale. Le informazioni fornite sono ritenute accurate, ma possono contenere errori o imprecisioni e non possono essere prese in considerazione per eventuali investimenti personali. L’articolo riporta esclusivamente le opinioni della redazione che non ha alcun rapporto economico con le aziende citate.
Solo, si fa per dire, 4 anni fa, Jared Kaplan, fisico teorico della Johns Hopkins University, ha pubblicato un articolo rivoluzionario sull’intelligenza: Scaling Laws for Neural Language Models.
La conclusione è stata chiara: più dati c’erano per addestrare un grande modello linguistico migliore sarebbe stato il suo rendimento, accurato e con più informazioni.
“Tutti sono rimasti molto sorpresi dal fatto che queste tendenze – queste leggi di scala come le chiamiamo noi – fossero fondamentalmente precise quanto quelle che si vedono in astronomia o fisica”
Kaplan
I ricercatori utilizzano da tempo grandi database pubblici di informazioni digitali per sviluppare l’Intelligenza Artificiale, tra cui Wikipedia e Common Crawl, un database di oltre 250 miliardi di pagine web raccolte a partire dal 2007. I ricercatori spesso “ripuliscono” i dati rimuovendo discorsi di incitamento all’odio e altri testi indesiderati prima di utilizzarli per addestrare modelli di intelligenza artificiale.
Nel 2020, i set di dati erano minuscoli rispetto agli standard odierni. All’epoca una banca dati contenente 30.000 fotografie dal sito fotografico Flickr era considerata una risorsa vitale.
Dopo l’articolo del Dr. Kaplan, quella quantità di dati non era più sufficiente. Si è parlato di “rendere le cose davvero grandi”, ha affermato Brandon Duderstadt, Nomic AD.
Quando OpenAI ha lanciato GPT-3 nel novembre 2020, ha segnato un traguardo significativo nell’addestramento dei modelli di intelligenza artificiale. GPT-3 è stato addestrato su una quantità di dati senza precedenti, circa 300 miliardi di “token”, che sono sostanzialmente parole o pezzi di parole.
Questa vasta quantità di dati ha permesso a GPT-3 di generare testi con una precisione sorprendente, producendo post di blog, poesie e persino i propri programmi informatici.
Tuttavia, nel 2022, DeepMind, un laboratorio di Intelligenza Artificiale di proprietà di Google, ha spinto ulteriormente in avanti i limiti.
Ha condotto esperimenti su 400 modelli di Intelligenza Artificiale, variando la quantità di dati di addestramento e altri parametri. I risultati hanno mostrato che i modelli più performanti utilizzavano ancora più dati di quelli previsti dal Dr. Kaplan nel suo articolo. Un modello in particolare, noto come Chinchilla, è stato addestrato su 1,4 trilioni di token.
Ma il progresso non si è fermato lì. L’anno scorso, ricercatori cinesi hanno presentato un modello di intelligenza artificiale chiamato Skywork, addestrato su 3,2 trilioni di token provenienti da testi sia in inglese che in cinese.
Google ha risposto presentando un sistema di Intelligenza Artificiale, PaLM 2, che ha superato i 3,6 trilioni di token.
Questi sviluppi evidenziano la rapida evoluzione del campo dell’Intelligenza Artificiale e l’importanza dei dati nell’addestramento di modelli sempre più potenti. Con ogni nuovo modello e ogni trilione di token aggiuntivo, ci avviciniamo sempre di più a modelli di Intelligenza Artificiale che possono comprendere e generare il linguaggio con una precisione e una naturalezza sempre maggiori.
Tuttavia, con questi progressi arrivano anche nuove sfide e responsabilità, poiché dobbiamo garantire che queste potenti tecnologie siano utilizzate in modo etico e responsabile.
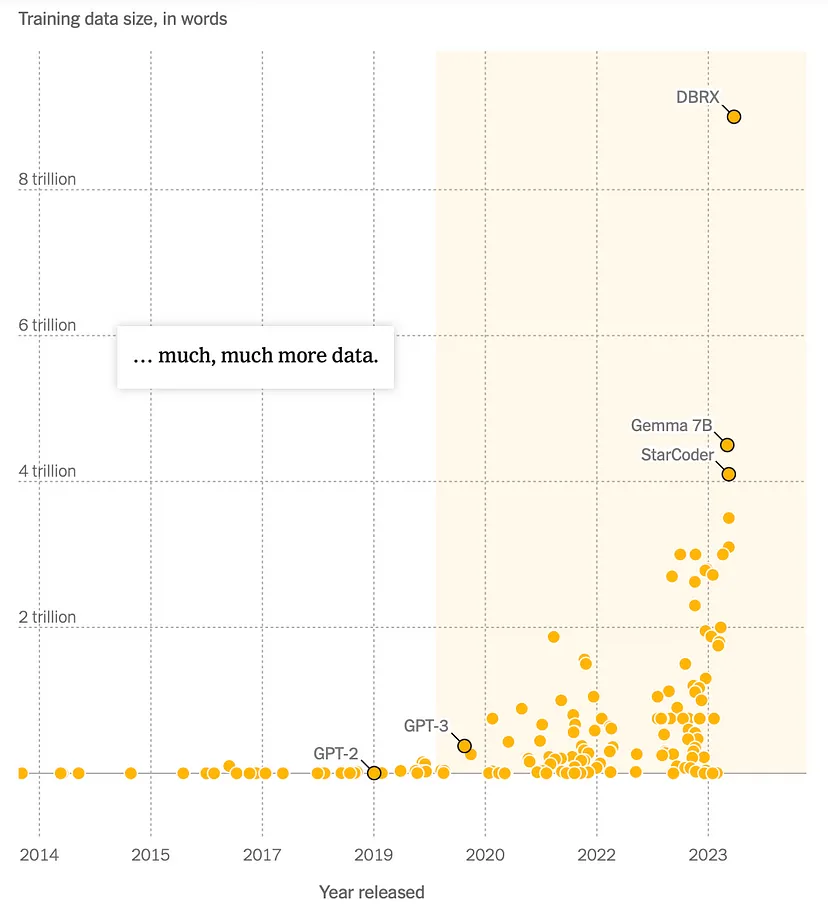
fonte https://epochai.org/data/epochdb
Poi nel 2023 è arrivato questo discorso sul Synthetic Data e sulle chellenges: “Si esauriranno”. Sam Altman, Ceo di OpenAI aveva un piano per far fronte all’incombente carenza di dati.
In una email a The Verge, la portavoce di OpenAI, Lindsay Held, ha dichiarato che l’azienda utilizza “numerose fonti, compresi i dati disponibili pubblicamente e le partnership per i dati non pubblici” e che sta cercando di generare i propri dati sintetici.
Nel mese di maggio, lo stesso Altman, ha riconosciuto che le aziende di Intelligenza Artificiale avrebbero sfruttato tutti i dati disponibili su Internet.
Altman ha avuto un’esperienza diretta di questo fenomeno. All’interno di OpenAI, i ricercatori hanno raccolto dati per anni, li hanno puliti e li hanno inseriti in un vasto pool di testo per addestrare i modelli linguistici dell’azienda. Hanno estratto il repository di codice GitHub, svuotato i database delle mosse degli scacchi e attingono ai dati che descrivono i test delle scuole superiori e i compiti a casa dal sito web Quizlet.
Tuttavia, entro la fine del 2021, queste risorse erano esaurite, come confermato da otto persone a conoscenza della situazione dell’azienda, che non erano autorizzate a parlare pubblicamente.
Cosa sono i dati sintetici:
WIKI
i dati sintetici sono dati generati artificialmente, piuttosto che dati raccolti da eventi del mondo reale. Sono spesso utilizzati per l’addestramento dei modelli di Intelligenza Artificiale (IA) quando i dati reali non sono disponibili o sono insufficienti.
Sam Altman, ex CEO di OpenAI, ha lavorato su modelli generativi che producono dati sintetici. Questi modelli, come GPT-4, utilizzano un gran numero di parametri per definire come possono essere prodotti dati simili a quelli forniti durante la fase di apprendimento. Questi parametri sono “regole generali” per la creazione di nuovi dati che il modello acquisisce dalle informazioni di addestramento fornite in precedenza.
In un modello generativo basato su reti neurali, i parametri vengono ottimizzati per migliorare la capacità del modello di generare dati sintetici coerenti con quelli di addestramento. Ad esempio, si ritiene che il modello GPT-4 di OpenAI sia stato composto utilizzando qualcosa come 1.000 miliardi di parametri.
Il CEO di YouTube, ha detto cose simili sulla possibilità che OpenAI abbia usato YouTube per addestrare il suo modello di generazione di video Sora.
Non sorprende che in entrambi i casi si tratti di azioni che hanno a che fare con la nebulosa area grigia della legge sul copyright dell’AI.
Da un lato OpenAI, alla continua ricerca di dati per un training di qualità, avrebbe sviluppato il suo modello di trascrizione audio Whisper per superare il problema, trascrivendo oltre un milione di ore di video di YouTube per addestrare GPT-4.
Secondo il New York Times, l’azienda sapeva che si trattava di un’operazione discutibile dal punto di vista legale (il presidente di OpenAI Greg Brockman era personalmente coinvolto nella raccolta dei video utilizzati), ma riteneva che si trattasse di un uso corretto (il cosidetto “fair use” tanto declamato dalle aziende di AI).
Tuttavia, Altman ha dichiarato che la corsa ai modelli generativi di dimensioni sempre più grandi sarebbe già conclusa. Ha suggerito che gli attuali modelli potranno evolvere in altri modi, non puntando più sulla “grandezza” e lasciando intendere che GPT-4 potrebbe essere l’ultimo e definitivo avanzamento nella strategia di OpenAI per ciò che riguarda il numero di parametri utilizzati in fase di addestramento.
Nel frattempo Google :

Matt Bryant, rappresentante comunicazione di Google, ha dichiarato che l’azienda non era a conoscenza delle attività di OpenAI e ha proibito lo “scraping o il download non autorizzato di contenuti da YouTube”. Google interviene quando esiste una chiara base legale o tecnica per farlo.
Le politiche di Google permettono l’utilizzo dei dati degli utenti di YouTube per sviluppare nuove funzionalità per la piattaforma video. Tuttavia, non era evidente se Google potesse utilizzare i dati di YouTube per creare un servizio commerciale al di fuori della piattaforma video, come un chatbot.
“La questione se i dati possano essere utilizzati per un nuovo servizio commerciale è soggetta a interpretazione e potrebbe essere fonte di controversie”.
Avv .Geoffrey Lottenberg, studio legale Berger Singerman
Verso la fine del 2022, dopo che OpenAI aveva lanciato ChatGPT, dando il via a una corsa nel settore per recuperare il ritardo, i ricercatori e gli ingegneri di Google hanno discusso su come sfruttare i dati di altri utenti per sviluppare prodotti di intelligenza artificiale. Tuttavia, le restrizioni sulla privacy dell’azienda limitano il modo in cui potrebbero utilizzare i dati, secondo persone a conoscenza delle pratiche di Google.
Secondo le ricostruzioni, a giugno, il dipartimento legale di Google ha chiesto al team per la privacy di redigere un testo per ampliare gli scopi per i quali l’azienda potrebbe utilizzare i dati dei consumatori (secondo due membri del team per la privacy e un messaggio interno visualizzato dal Times) ed è stato comunicato ai dipendenti che Google desiderava utilizzare i contenuti pubblicamente disponibili in Google Docs, Google Sheets e app correlate per una serie di prodotti AI. I dipendenti hanno affermato di non sapere se l’azienda avesse precedentemente addestrato l’intelligenza artificiale su tali dati.
In quel periodo, la politica sulla privacy di Google stabiliva che l’azienda potesse utilizzare le informazioni pubblicamente disponibili solo per “aiutare a formare i modelli linguistici di Google e creare funzionalità come Google Translate”.
Il team per la privacy ha redatto nuovi termini in modo che Google potesse utilizzare i dati per i suoi “modelli di Intelligenza Artificiale e creare prodotti e funzionalità come Google Translate, Bard e funzionalità di Intelligenza Artificiale del cloud”, che rappresentava una gamma più ampia di tecnologie di intelligenza artificiale.
“Qual è l’obiettivo finale qui?” ha chiesto un membro del team per la privacy in un messaggio interno. “Quanto sarà estesa?”
Al team è stato specificamente detto di pubblicare i nuovi termini nel fine settimana del 4 luglio, quando le persone sono generalmente concentrate sulle vacanze, secondo i dipendenti. La politica rivista è stata lanciata il 1° luglio, all’inizio del lungo fine settimana (NdR, il 4 luglio negli Usa è festa nazionale).
E Meta? Mark Zuckerberg aveva lo stesso problema, non aveva abbastanza dati, avevano utilizzato tutto come detto a un dirigente da Ahmad Al-Dahle, vicepresidente dell’AI generativa di Meta quindi non poteva eguagliare ChatGPT a meno che non fosse riuscito ad ottenere più dati.
Meta ha usato, fra gli altri materiali, due raccolte di libri, il Gutenberg Project, che contiene opere nel pubblico dominio, e la sezione Books3. Ma la maggior parte sono opere “piratate” e per questo alcuini avviato una class action contro Meta e ciò era evidente sino dall’inizio come dimostra il documento di seguito.
Nei mesi di marzo e aprile 2023, alcuni leader dello sviluppo aziendale, ingegneri e avvocati dell’azienda si sono incontrati quasi quotidianamente per affrontare il problema.
Alcuni hanno discusso del pagamento di 10 dollari a libro per i diritti di licenza completi sui nuovi titoli. Hanno discusso dell’acquisto di Simon & Schuster,di cui fanno parte anche Penguin Random House, HarperCollins, Hachette e Macmillan. Fra gli autori di Simon & Schuster ci sono Stephen King, Colleen Hoover e Bob Woodward.
Hanno anche parlato di come avevano riassunto libri, saggi e altri lavori da Internet senza permesso anche per via del precedente scandalo sulla condivisione dei dati dei suoi utenti all’epoca di Cambridge Analytica.
Un avvocato ha avvertito di preoccupazioni “etiche” riguardo alla sottrazione della proprietà intellettuale agli artisti, ma è stato accolto nel silenzio, secondo un audio registrato e condiviso con il NYT di cui ha dato conto il quotidiano britannico The Guardian. Meta era stata anche accusata dal BEUC unione consumatori europei con una multa da 1.2 miliardi di euro.
Zuckerberg, per tranquillizare gli investitori, ha affermato in una recente call (Earnings call Transcript 2023 di seguito) che i miliardi di video e foto condivisi pubblicamente su Facebook e Instagram sono “superiori al set di dati Common Crawl”.
I dirigenti di Meta hanno affermato che OpenAI sembrava aver utilizzato materiale protetto da copyright senza autorizzazione. Secondo le registrazioni, Meta impiegherebbe troppo tempo per negoziare le licenze con editori, artisti, musicisti e l’industria dell’informazione.
“L’unica cosa che ci impedisce di essere bravi quanto ChatGPT è letteralmente solo il volume dei dati”,
Nick Grudin, vP partnership globale e dei contenuti.
Sembra che OpenAI stia prendendo materiale protetto da copyright e Meta potrebbe seguire questo “precedente di mercato”, ha aggiunto, citando una decisione del tribunale del 2015 che coinvolgeva la Authors Guild contro Google .
In quel caso, a Google è stato consentito di scansionare, digitalizzare e catalogare libri in un database online dopo aver sostenuto di aver riprodotto solo frammenti delle opere online e di aver trasformato gli originali, sempre in base alla dottrina del fair use.
La saga continua.
Come abbiamo scritto in un precedente post, la FTC americana può riaprire il caso sulla privacy di Meta nonostante la multa di 5 miliardi di dollari, stabilisce il tribunale, anche se Meta – che possiede WhatsApp, Instagram e Facebook – ha risposto che la FTC non può “riscrivere unilateralmente” i termini dell’accordo precedente, che un giudice statunitense ha approvato nel 2020.
L’FTC ha replicato che l’accordo, che stabilisce nuovi requisiti di conformità e supervisione, non era destinato a risolvere “tutte le richieste di risarcimento in perpetuo”.
Indipendentemente dal punto di vista e da ciò che sarà deciso nei tribunali, l’importanza di conoscere il contenuto dei dataset è oggi più rilevante che mai. Si tratta senza dubbio di un problema di natura politica.

Questa settimana, noi di Redazione Rivista.AI siamo andati a un paio di convegni e la parola Hype e’ stata sparsa come lo zucchero a velo sul pandoro o spread thin like butter on toast come dicono gli anglofoni.
Ci e’ sembrato doveroso scrivere una articolo nella sezione Vision, di venerdi sera, sperando che abbiate abbastanza tempo durante il Weekend per leggerlo. Altrimenti fermatevi all’elevetor pitch :
I grandi modelli linguistici (LLM) e l’intelligenza artificiale generativa (GenAI) stanno attualmente rivoluzionando numerosi settori e stanno trasformando radicalmente la nostra vita quotidiana.
Finora, l’approccio principale per monetizzare la GenAI è stato orientato verso i flussi di entrate Business-to-Business (B2B), ma si sta iniziando a osservare un crescente interesse verso l’implementazione di modelli basati su abbonamento e l’introduzione del “GPT Store”, che mostra promesse anche per gli utenti individuali.
Allo stesso tempo, la progettazione di hardware e software, unita agli strumenti per ottimizzare i flussi di lavoro dell’intelligenza artificiale e le opportunità nell’applicazione pratica dell’intelligenza artificiale, emergono come aree chiave da monitorare attentamente nello spazio della GenAI.

Quando si parla di intelligenza artificiale, si sente spesso parlare di Nvidia, Broadcom , AMD e altre società di chip, software e servizi. Tuttavia, Intel viene spesso trascurata . Dovremmo mettere le cose in prospettiva perché siamo ancora agli inizi del gioco dell’intelligenza artificiale e c’è molto spazio per l’espansione di molti leader di mercato.
Quest’anno, si prevede che i ricavi legati all’intelligenza artificiale saranno di circa 300 miliardi di dollari. Tuttavia, si prevede che il mercato dell’intelligenza artificiale si espanderà notevolmente, con ricavi stimati a 1,85 trilioni di dollari entro il 2030, di seguito propiezioni da Statista:
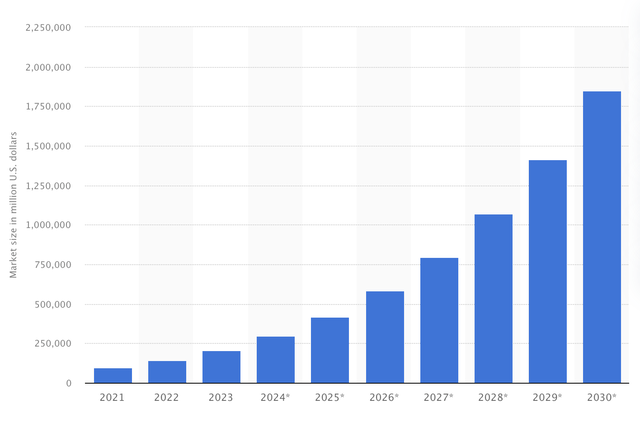
Venerdì, i titoli nel settore dei semiconduttori hanno subito un’improvvisa ondata di vendite, alimentata dalle preoccupazioni riguardo ai prossimi risultati trimestrali del gigante dell’intelligenza artificiale Super Micro Computer e dalle crescenti inquietudini riguardo alle spese relative all’IA.
Il crollo del 23% di Super Micro Computer è stato innescato dalle sue dichiarazioni riguardanti la pubblicazione dei risultati fiscali del terzo trimestre, prevista per il 30 aprile. Negli ultimi trimestri, l’azienda ha spesso anticipato i suoi risultati, con un’azione simile avvenuta anche a gennaio, quando ha rialzato le sue previsioni 11 giorni prima del resoconto degli utili.
Venerdì sono passate di mano più di 14 milioni di azioni, rispetto al volume medio giornaliero di poco più di 10 milioni, portando alla speculazione che la società potrebbe vedere un rallentamento delle vendite.
Nvidia , precedentemente identificata da Oppenheimer come una delle migliori opzioni del settore all’inizio della stagione degli utili, ha registrato una diminuzione superiore al 10%, chiudendo a 761,77 dollari. Dall’evento GTC tenutosi il mese precedente, le azioni dell’azienda sono diminuite di oltre il 20%.
AMD spesso associata a Nvidia, ha visto un calo superiore al 5%, terminando a 146,64 dollari.
Intel , concorrente sia di Nvidia che di AMD nei mercati delle GPU e delle CPU, ha chiuso venerdì in ribasso del 2,4%.
Astera Labs, che ha recentemente debuttato in borsa, ha subito una flessione del 9%. Anche se inizialmente aveva registrato un aumento del 164% rispetto al prezzo IPO di 34 dollari, il calo di venerdì ha ridotto il guadagno a circa il 60%.
Arm , che ha fatto il suo ingresso in borsa a settembre 2023, ha subito un calo superiore al 16% venerdì. Nel mese precedente, le azioni hanno registrato una perdita del 33%.
Altri attori del settore, tra cui Taiwan Semiconductor , Qualcomm (QCOM), Micron Technology , Texas Instruments e ON Semiconductor , hanno anch’essi registrato un significativo calo venerdì, con diminuzioni del 2% o più.
Taiwan Semiconductor ha visto un calo superiore al 12% durante la settimana, in seguito alla pubblicazione dei risultati del primo trimestre, sebbene Needham, una società di investimento, abbia commentato venerdì che il calo è stato “esagerato”.
Divulgazione dell’analista: non ho/noi non abbiamo alcuna posizione su azioni, opzioni o derivati simili in nessuna delle società menzionate e non ho intenzione di avviare tali posizioni entro le prossime 72 ore. Ho scritto questo articolo io stesso ed esprime le mie opinioni. Non ricevo alcun compenso per questo . Non ho rapporti d’affari con alcuna società le cui azioni sono menzionate in questo articolo.
La performance passata non è garanzia di risultati futuri. Non viene fornita alcuna raccomandazione o consiglio riguardo al fatto che un particolare titolo, portafoglio, transazione o strategia di investimento sia adatto a una persona specifica. L’autore non ti consiglia personalmente riguardo alla natura, al potenziale, al valore o all’idoneità di qualsiasi particolare titolo o altra questione. Solo tu sei l’unico responsabile di determinare se qualsiasi investimento, titolo o strategia, o qualsiasi prodotto o servizio, sia appropriato o adatto a te in base ai tuoi obiettivi di investimento e alla tua situazione personale e finanziaria.

Si è parlato di sostenibilità, di trasformazione digitale e di Intelligenza Artificiale nel corso dell’evento Digital Sustainability Day organizzato ieri dalla Fondazione per la Sostenibilità Digitale all’Università La Sapienza.
L’evento, rivolto alle aziende del tessuto economico italiano, a enti, istituzioni, Pubbliche Amministrazioni e Università che hanno intrapreso o stanno per intraprendere processi di trasformazione digitale e che vogliono, o hanno bisogno, di mettere la sostenibilità al centro delle loro attività, è stato l’occasione per fare il punto sui primi 3 anni di attività della Fondazione per la Sostenibilità Digitale che ha rapidamente assunto un ruolo centrale nel panorama del settore, promuovendo una visione sociale della sostenibilità, sottolineando l’importanza di una comprensione diffusa e di scelte economiche consapevoli.
Questo approccio, che negli ultimi anni potremmo chiamare “Sostenibilità Digitale Esponenziale”, per effetto anche dell’Intelligenza Artificiale, riconosce che il futuro sostenibile richiede un contesto abilitante fornito dalla tecnologia digitale.
Le iniziative della Fondazione si concentrano sulla creazione di opportunità di comunicazione, confronto e apprendimento per sostenere le istituzioni nell’adozione di pratiche sostenibili, avendo ben presente che la sostenibilità non può essere imposta dall’alto, ma deve essere accettata e compresa a livello sociale.

Nel contesto del Convegno, è stata affrontata la questione della sostenibilità e della sua relazione con la trasformazione digitale con l’apporto e la partecipazione di una platea ampia e trasversale che riunisce esperti, ricercatori, professionisti ed esponenti del mondo della politica, chiamati ad esaminare le sfide e le opportunità legate alla sostenibilità digitale.
La trasformazione digitale non riguarda il come facciamo le cose, la trasformazione digitale non è una questione tecnologica, o meglio, non è soltanto una questione tecnologica, perché la trasformazione digitale è un fenomeno sociale, è l’impatto sulla società della digitalizzazione e è un impatto che guarda al modo in cui la trasformazione digitale agisce sui comportamenti, agisce sui contesti, agisce sulle cose e ne ridefinisce il senso, non è una scelta, noi non possiamo scegliere che i nostri clienti utilizzino un determinato strumento, non possiamo scegliere che i cittadini usino o non usino delle tecnologie a meno che non siamo in Cina, non possiamo scegliere, ci troviamo in una condizione di contesto e quella condizione di contesto ha un impatto (9:07) fortissimo su di noi, quindi di fatto la trasformazione digitale è un fenomeno sociale unisce il senso delle cose..
Stefano Epifani, Presidente della fondazione per la sostenibilitÀ digitale
È stato sottolineato come la sostenibilità non vada confusa con il mero ambientalismo e come sia di fondamentale importanza per garantire un futuro equo e prospero. La trasformazione digitale, a sua volta, rappresenta un’opportunità per ridefinire il modo in cui affrontiamo le sfide globali, influenzando comportamenti e contesti in modi che vanno oltre il semplice utilizzo della tecnologia.
In particolare, la trasformazione digitale non riguarda solo il miglioramento dei processi esistenti attraverso la tecnologia, ma è un fenomeno sociale che ridefinisce il significato delle nostre interazioni e dei nostri modelli di comportamento. Questo implica una comprensione più profonda di come la tecnologia possa essere utilizzata per promuovere la sostenibilità e per consentire alle future generazioni di fare scelte consapevoli.
Dobbiamo chiederci qual è il ruolo del digitale in questo percorso e vedremo che il ruolo del digitale è duplice perché il digitale interagisce in maniera sistemica col resto, non è uno strumento, è al contempo strumento e contesto, strumento d’azione e contesto di rideterminazione o di rimediazione come direbbe qualcuno.
Stefano EPIFANI, Presidente della fondazione per la sostenibilitÀ digitale
Il tema è quello di mettere al centro la digitalizzazione, mettere al centro la sostenibilità, costruire un bilanciamento tra questi due elementi e sviluppare un modello che ci consenta di lavorare in due direzioni.
Nella seconda parte del convegno sono stati presentati i benefici di misurare il livello di sostenibilità digitale di utenti, territori e specifici progetti, come pre requisito di una scelta consapevole del processo di digitalizzazione, unitamente alla necessità di nuovi modelli di sviluppo e governance territoriale.
L’obiettivo del DISI™ 2024 (Digital Sustainability Index) è stato proprio quello di approfondire la comprensione delle dinamiche che caratterizzano la sostenibilità digitale in diverse aree geografiche e contesti socio-economici.
Da questo punto di vista, quello che emerge dai dati che sono stati presentati, è che il divario piccoli centri-grandi centri sta soppiantando quello nord-sud: se 1 italiano su 3 ovvero il 34% degli abitanti delle grandi città ha una conoscenza limitata o nulla del concetto di sostenibilità, questa percentuale sale al 53%, se i considerano i comuni con meno di 3000 abitanti.
Dalla ricerca emerge poi anche una grande difficoltà da parte dei cittadini italiani nel guardare al digitale come strumento al servizio della sostenibilità, sia essa ambientale, economica o sociale.
Il Presidente della Fondazione Stefano Epifani si è dedicato all’analisi delle differenze nella sostenibilità digitale tra le aree centrali e periferiche, affrontando il tema relativo all’accesso e all’inclusione digitale: l’esplorazione delle disparità di accesso alle tecnologie digitali tra le aree centrali e periferiche e l’identificazione di strategie per ridurre il cosiddetto “digital divide” concetto nei prossimi anni ancora piu importante se considereremo l’impatto della Intelligenza Artificiale.
L’Intelligenza Artificiale (AI) da questo punto di vista può svolgere un ruolo importante nel mitigare il digital divide e le tecnologie basate sull’AI possono essere utilizzate per sviluppare soluzioni innovative che rendano i servizi digitali più accessibili e inclusivi, ad esempio quelli sanitari nei centri periferici. Certo da questo punto di vista è necessaria una visione chiara delle opportunità offerte dall’adozione dell’Intelligenza Artificiale anziché una focalizzazione, come stiamo purtroppo vedendo da certa parte del mondo politico, troppo spesso incentrata sui rischi e le minacce dell’AI, proprio perché
Non si orienta un paese con le paure, riferendosi all’impatto futuro della Intelligenza Artificiali.
Stefano EPIFANI, Presidente della fondazione per la sostenibilitÀ digitale
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]

LE INTERVISTE DI WOMEN IN AI – Claudia Segre, un viaggio tra finanza sostenibile, inclusione, Intelligenza Artificiale e l’empowerment delle donne con la Thinking Foundation.

Oggi abbiamo l’opportunità unica di condividere con voi un’intervista esclusiva con Claudia Segre, un nome di rilievo nel mondo della finanza sostenibile e del fintech.
Claudia è una paladina nella lotta contro la violenza economica di genere e gioca un ruolo fondamentale nella Thinking Foundation, un’organizzazione che si dedica all’empowerment femminile.
Nel corso di questa intervista, Claudia ci guiderà attraverso la sua visione del futuro del fintech, toccando argomenti come la finanza sostenibile, l’inclusione, l’Intelligenza Artificiale e l’empowerment delle donne. Avremo anche l’opportunità di discutere il ruolo che la Thinking Foundation sta svolgendo nel plasmare il futuro di questo settore.


Microsoft ha recentemente introdotto VASA-1, un modello di intelligenza artificiale che produce video realistici di volti parlanti da una singola immagine statica e una clip audio.
Il modello è in grado di produrre video con una risoluzione di 512×512 pixel e una frequenza di 40 fotogrammi al secondo (FPS), con una latenza di soli 170 millisecondi sui sistemi GPU NVIDIA RTX 4090.
L’architettura del modello si basa su un approccio di diffusione.
A differenza dei metodi tradizionali che trattano le caratteristiche facciali separatamente, VASA-1 utilizza un modello basato sulla diffusione per generare dinamiche facciali e movimenti della testa in modo olistico. Questo metodo considera tutte le dinamiche facciali, come il movimento delle labbra, l’espressione e i movimenti degli occhi, come parti di un unico modello completo.
VASA-1 opera all’interno di uno spazio latente del viso districato ed espressivo, che gli permette di controllare e modificare le dinamiche facciali e i movimenti della testa indipendentemente da altri attributi facciali come l’identità o l’aspetto statico.
Il modello è stato addestrato su un set di dati ampio e diversificato, che gli consente di gestire un’ampia gamma di identità facciali, espressioni e modelli di movimento. Questo approccio di addestramento aiuta il modello a funzionare bene anche con dati di input che si discostano da ciò su cui è stato addestrato, come input audio non standard o immagini artistiche.
L’addestramento del modello prevede tecniche avanzate di districamento, che consentono la manipolazione separata delle caratteristiche facciali dinamiche e statiche. Ciò si ottiene attraverso l’uso di codificatori distinti per diversi attributi e una serie di funzioni di perdita attentamente progettate per garantire un’efficace separazione di queste caratteristiche.
VASA-1 è stato rigorosamente testato rispetto a vari benchmark e ha dimostrato di superare significativamente i metodi esistenti in termini di realismo, sincronizzazione degli elementi audiovisivi ed espressività delle animazioni generate.
Nonostante i risultati promettenti, la ricerca riconosce alcuni limiti del modello, come l’incapacità di elaborare le dinamiche di tutto il corpo o di catturare completamente elementi non rigidi come i capelli. Tuttavia, sono previsti lavori futuri per espandere le capacità del modello e affrontare queste aree.
L’Intelligenza Artificiale (AI) per immagini e video ha rivoluzionato molti settori, tra cui il riconoscimento di oggetti, l’analisi delle immagini mediche, la sorveglianza di sicurezza, la creazione di contenuti multimediali e molto altro. Ecco alcuni esempi di come l’AI viene utilizzata per immagini e video:
Altri esempi di Modelli in allegato
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]

Microsoft Investe in G42 e nel calcolatore piu’ potente al mondo.
Microsoft, il gigante dell’industria tecnologica , ha annunciato un investimento di 1,5 miliardi di dollari per acquisire una partecipazione minoritaria in G42, un gruppo di holding tecnologiche con sede negli EAU. L’obiettivo di questa mossa strategica è di introdurre tecnologie di intelligenza artificiale all’avanguardia e infrastrutture digitali nei mercati del Medio Oriente, dell’Asia centrale e dell’Africa.
G42, conosciuta anche come Group 42 Holding Ltd, è una società di sviluppo ed un fondo di intelligenza artificiale (IA) fondata nel 2018. G42 è un leader globale nella creazione di intelligenza artificiale visionaria per un futuro migliore.
Nata ad Abu Dhabi e con una presenza globale, ha finanziato Jais, un LLM trainato sull’arabo, sviluppato in collaborazione con l’universita’ MBZUAI, Jais è stato addestrato sul supercomputer AI Condor Galaxy, su 116 miliardi di token arabi e 279 miliardi di token di dati inglesi, ma G42 è importante soprattutto per la collaborazione con Cerebras infatti le due societa’ hanno annunciato il 13 Marzo la costruzione di Condor Galaxy 3 (CG-3).

La partnership strategica tra Cerebras e G42 ha già fornito 8 exaFLOP di prestazioni di supercalcolo IA tramite Condor Galaxy 1 e Condor Galaxy 2, ciascuno tra i più grandi supercomputer IA del mondo. Situato a Dallas, in Texas, Condor Galaxy 3 porta l’attuale totale della rete Condor Galaxy a 16 exaFLOP.
La rete Condor Galaxy ha addestrato alcuni dei migliori modelli open source del settore, con decine di migliaia di download. Ogni CS-3 è alimentato dal nuovo transistor da 4 trilioni, 900.000 core di IA WSE-3.
Il nostro super calcolatore italiano Leonardo ha un picco di 270PFlops, ne servono 30 per fare la capacita del Condor-Galaxy-3 di Dallas (TOP500), CG3 può allenare un modello grande 100 volte l’attuale GPT4.
Il CG3 ha allenato un LLM per la medicina, l’M42 una rete sanitaria globale abilitata alla tecnologia. Il programma Med42 utilizza la versione da 70 miliardi di parametri di Llama 2. Il lavoro di messa a punto è stato eseguito da Cerebras e M42 in collaborazione con Core42, una società di servizi gestiti e IT che svolge ricerche fondamentali sull’intelligenza artificiale. Sia M42 che Core42 sono di proprietà del cliente Cerebras G42.
Il codice M42 è ora disponibile su HuggingFace, insieme ai dati sulle prestazioni.
Questo segna una pietra miliare significativa nel calcolo dell’IA, fornendo una potenza di elaborazione ed efficienza senza pari.
L’organizzazione si concentra sullo sviluppo dell’IA in vari settori, tra cui governo, sanità, finanza, petrolio e gas, aviazione e ospitalità. G42 svolge processi di ricerca e sviluppo sull’IA, sui big data e sull’apprendimento automatico tramite la sua sussidiaria,l‘Inception Institute of Artificial Intelligence (IIAI).
Tahnoun bin Zayed Al Nahyan, consigliere per la sicurezza nazionale degli Emirati Arabi Uniti, è l’azionista di controllo e presidente della società. Peng Xiao è l’Amministratore Delegato del Gruppo.
G42 ha anche acquisito Bayanat per Mapping and Surveying Services LLC, un fornitore end-to-end di prodotti e servizi di dati geospaziali, per integrare i servizi satellitari di G42.
Sua Altezza Sheikh Tahnoon bin Zayed Al Nahyan, Presidente di G42, ha dichiarato:
“L’investimento di Microsoft in G42 segna un momento cruciale nel percorso di crescita e innovazione della nostra azienda, a significare un allineamento strategico di visione ed esecuzione tra le due organizzazioni. Questa partnership è una testimonianza ai valori condivisi e alle aspirazioni al progresso, promuovendo una maggiore cooperazione e sinergia a livello globale.”
Entrambe le aziende si impegnano a sostenere la creazione di un fondo da 1 miliardo di dollari destinato agli sviluppatori. Questo fondo mira a promuovere lo sviluppo di una forza lavoro qualificata e diversificata nel campo dell’intelligenza artificiale.
G42 implementerà le sue applicazioni e servizi di intelligenza artificiale sulla piattaforma cloud di Microsoft, Azure. Inoltre, G42 fornirà soluzioni di intelligenza artificiale a importanti aziende e clienti del settore pubblico.
Questa collaborazione commerciale è sostenuta da garanzie fornite ai governi degli Stati Uniti e degli Emirati Arabi Uniti, impegnandosi a rispettare le leggi statunitensi e internazionali in materia di commercio, sicurezza, intelligenza artificiale responsabile e integrità aziendale.
L’investimento di Microsoft in G42 rappresenta un esempio insolito di accordo che ha ottenuto l’approvazione esplicita delle rispettive autorità governative. Secondo quanto dichiarato dalle società coinvolte, questa “collaborazione commerciale è sostenuta da garanzie fornite ai governi degli Stati Uniti e degli Emirati Arabi Uniti tramite un innovativo accordo vincolante, il primo del suo genere, volto a implementare le migliori pratiche globali per assicurare uno sviluppo sicuro, affidabile e responsabile e la diffusione dell’intelligenza artificiale”.
Se l’accordo verrà concluso con successo, conferirà a Microsoft il ruolo di partner cloud ufficiale di G42. Secondo i termini dell’accordo, la piattaforma dati della società emiratina e altre infrastrutture cruciali verranno trasferite su Microsoft Azure, il quale supporterà lo sviluppo dei prodotti G42. È da notare che G42 ha già instaurato una partnership con OpenAI nel 2023.
La collaborazione con Microsoft sembra essere parte di una strategia continua da parte di G42 per ridurre la sua dipendenza dalle relazioni commerciali con la Cina. Infatti, l’azienda ha recentemente disinvestito dai suoi legami con la Cina, incluso il possesso di azioni nella società madre di TikTok, ByteDance, avvenuto lo scorso febbraio. Il CEO Xiao ha anche annunciato alla fine dell’anno scorso che l’azienda avrebbe gradualmente eliminato l’utilizzo di hardware cinese, dichiarando: “Non possiamo mantenere relazioni con entrambe le parti”.
In cambio, Microsoft otterrà un ampio accesso al mercato della regione. I suoi servizi di intelligenza artificiale e Azure potranno penetrare in una vasta gamma di settori, tra cui servizi finanziari, sanità, energia, governo e istruzione. Inoltre, la partnership prevede il lancio di un fondo da 1 miliardo di dollari “per supportare lo sviluppo delle competenze nell’intelligenza artificiale” negli Emirati Arabi Uniti e nella regione circostante.
Come evidenziato dagli eventi degli ultimi anni, le aziende tecnologiche si trovano sempre più ad affrontare la difficile scelta tra Stati Uniti e Cina, sia in termini di fornitori di tecnologia che di utenti o investitori. Le evoluzioni legate a G42 dimostrano che anche un paese come gli Emirati Arabi Uniti, che ha cercato di mantenere una posizione neutrale, potrebbe alla fine essere costretto a prendere una posizione chiara.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]

L’anno scorso, Microsoft ha presentato un’idea ambiziosa al Dipartimento della Difesa: utilizzare DALL-E, uno strumento di generazione di immagini di OpenAI, per sviluppare software militare. Questa proposta è emersa poco dopo che OpenAI aveva revocato il divieto sull’utilizzo militare dei suoi strumenti.
La presentazione di Microsoft, denominata “Generative AI with DoD Data”, esplora come il Pentagono potrebbe impiegare gli strumenti di apprendimento automatico di OpenAI, tra cui ChatGPT e DALL-E, per una vasta gamma di attività militari, dall’analisi dei documenti alla gestione della macchina. Questa presentazione è stata parte di un seminario di formazione sull’intelligenza artificiale organizzato dalla US Space Force a Los Angeles nel 2023.
I materiali della presentazione sono stati resi pubblici da Alethia Labs, un’organizzazione di consulenza senza scopo di lucro che assiste il governo federale nell’acquisizione di tecnologia. Questi materiali sono stati scoperti dal giornalista Jack Poulson. Alethia Labs ha lavorato in stretta collaborazione con il Pentagono per integrare rapidamente l’intelligenza artificiale nel suo arsenale.
Una parte della presentazione di Microsoft si concentra sull’utilizzo di DALL-E per addestrare i sistemi di gestione della battaglia, fornendo al Pentagono la capacità di “vedere” meglio le condizioni sul campo di battaglia utilizzando immagini artificiali generate. Microsoft ha dichiarato di non aver ancora avviato questo tipo di utilizzo, ma ha evidenziato il potenziale di tali casi d’uso.
OpenAI, d’altra parte, ha negato qualsiasi coinvolgimento nella presentazione di Microsoft e ha ribadito la sua politica di non consentire l’uso dei suoi strumenti per scopi militari. Tuttavia, le politiche di OpenAI all’epoca della presentazione non vietavano esplicitamente l’uso militare di DALL-E.
La presentazione solleva questioni etiche e pratiche sull’efficacia e sull’impatto dell’utilizzo di tecnologie di generazione di immagini come DALL-E nei contesti militari. Alcuni esperti mettono in dubbio la precisione e l’utilità di tali strumenti nell’ambito delle operazioni di combattimento.
Il Dipartimento della Difesa non ha risposto direttamente alle domande sulla presentazione di Microsoft, ma ha chiarito che la sua missione è accelerare l’adozione di intelligenza artificiale in tutto il Dipartimento.
“Accelerare l’adozione di dati avanzati, analisi e tecnologie di intelligenza artificiale rappresenta un’opportunità senza precedenti per fornire ai leader di dipartimento a tutti i livelli i dati di cui hanno bisogno per prendere decisioni migliori più velocemente”, ha dichiarato il 2 novembre Craig Martell, Chief Digital and AI Officer (CDAO) del Pentagono.
Questa situazione evidenzia il crescente coinvolgimento delle aziende tecnologiche nel settore della difesa e solleva domande sulle implicazioni etiche e pratiche di tale collaborazione.
I governi di tutto il mondo sembrano abbracciare l’intelligenza artificiale come il futuro della guerra. Israele ha utilizzato un sistema di intelligenza artificiale chiamato Lavender per creare una “lista di uccisioni” di 37.000 persone a Gaza, originariamente riportata dalla rivista +972 .
Bloomberg, ha dichiarato che dal luglio dello scorso anno, gli ufficiali militari americani hanno sperimentato grandi modelli linguistici per compiti militari .
L’ex CEO di Google, Eric Schmidt, sta costruendo droni kamikaze con intelligenza artificiale sotto una società denominata White Stork . Schmidt ha collegato per anni la tecnologia e il Pentagono e sta guidando gli sforzi per impiegare l’intelligenza artificiale in prima linea.
Alcune informazioni di questo articolo sono apparse su Gizmodo.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]

La società deve affrontare la questione cruciale della fiducia in sistemi che dimostrano una capacità di auto-evoluzione, e questo è un tema che Isaac Asimov ha affrontato nelle sue opere di fantascienza.
Asimov è noto per la creazione delle “Tre leggi della robotica”, che sono state progettate per garantire che i robot non danneggino gli esseri umani o permettano che gli esseri umani vengano danneggiati attraverso l’inazione.
Tuttavia, come la società si avvicina allo sviluppo di sistemi di intelligenza artificiale sempre più sofisticati e autonomi, la questione della fiducia e del controllo diventa ancora più complessa.
La capacità di auto-evolversi di un sistema di intelligenza artificiale significa che può imparare e adattarsi senza l’intervento umano, il che può portare a risultati imprevisti o indesiderati.
Questo solleva domande su come possiamo garantire che tali sistemi operino in modo sicuro ed etico, e su come possiamo garantire che siano conformi alle leggi e alle normative umane.
A questa necessita’ viene icontro il Curiosity-Driven Red-Teaming (CRT) è un metodo innovativo per migliorare la sicurezza dei Large Language Models (LLMs), come i chatbot AI.
I ricercatori dell’Improbable AI Lab del MIT e del MIT-IBM Watson AI Lab hanno utilizzato l’apprendimento automatico per migliorare il red-teaming. Hanno sviluppato una tecnica per addestrare un modello linguistico di grandi dimensioni del team rosso a generare automaticamente diversi suggerimenti che attivano una gamma più ampia di risposte indesiderate dal chatbot in fase di test.
Lo fanno insegnando al modello della squadra rossa a essere curioso quando scrive i suggerimenti e a concentrarsi su nuovi suggerimenti che evocano risposte tossiche dal modello target.
Questo approccio utilizza l’esplorazione guidata dalla curiosità per ottimizzare la novità, formando modelli di red team per generare un insieme di casi di test diversi ed efficaci.
Tradizionalmente, il processo di verifica e test delle risposte di un LLM coinvolgeva un “red team” umano che creava prompt di input specifici per cercare di provocare risposte indesiderate dall’LLM.
Questo processo può essere sia costoso che lento. Di recente, sono stati sviluppati metodi automatici che addestrano un LLM separato, con l’apprendimento per rinforzo, per generare test che massimizzino la probabilità di suscitare risposte indesiderate dal LLM target.
Tuttavia, questi metodi tendono a produrre un numero limitato di casi di test efficaci, offrendo quindi una copertura limitata delle potenziali risposte indesiderate.
CRT supera questa limitazione collegando il problema della generazione di test alla strategia di esplorazione guidata dalla curiosità.
Questo approccio non solo aumenta la copertura dei casi di test, ma mantiene o aumenta anche la loro efficacia, migliorando significativamente la valutazione complessiva della sicurezza dei LLM.
La metodologia CRT si è rivelata molto utile nel generare output tossici da modelli LLM che erano stati addestrati con cura per prevenire tali output.
Questo studio evidenzia l’importanza di esplorare nuovi metodi per aumentare l’efficacia e la copertura dei test di sicurezza per i LLM, specialmente alla luce della loro crescente capacità e diffusione in applicazioni pratiche.
Per ulteriori dettagli, puoi consultare il documento originale “Curiosity-driven Red-teaming for Large Language Models” pubblicato su OpenReview o il codice sorgente disponibile su GitHub.
Official implementation of ICLR’24 paper, “Curiosity-driven Red Teaming for Large Language Models” (https://openreview.net/pdf?id=4KqkizXgXU)
I coautori di Hong includono gli studenti laureati EECS Idan Shenfield, Tsun-Hsuan Wang e Yung-Sung Chuang; Aldo Pareja e Akash Srivastava, ricercatori del MIT-IBM Watson AI Lab; James Glass, ricercatore senior e capo dello Spoken Language Systems Group presso il Laboratorio di informatica e intelligenza artificiale (CSAIL); e l’autore senior Pulkit Agrawal, direttore di Improbable AI Lab e assistente professore al CSAIL. La ricerca sarà presentata alla Conferenza Internazionale sulle Rappresentazioni dell’Apprendimento.
L’integrazione del Curiosity-Driven Red Teaming (CRT) nella sicurezza dei chatbot e dei Large Language Models (LLMs) rappresenta un significativo progresso, evidenziando una trasformazione fondamentale nella gestione e mitigazione delle risposte indesiderate generate dall’intelligenza artificiale.
Questo metodo, attraverso l’automazione e l’efficienza incrementata, non solo supera i limiti tradizionali di costi, tempo e varietà nei test, ma pone anche questioni etiche sul ruolo umano in questo processo evolutivo.
L’aumento dell’autonomia dell’IA, che sta progredendo nella generazione autonoma del proprio codice software e nel monitoraggio delle proprie prestazioni, indica una trasformazione nel settore industriale orientata all’efficienza temporale e alla riduzione dei costi associati allo sviluppo.
Tuttavia, questa evoluzione solleva interrogativi significativi sull’autoreferenzialità dell’IA e sulla potenziale assenza di supervisione umana, portando a riflessioni sulla regolamentazione e sul controllo etico dell’evoluzione dell’IA.
La società deve affrontare la questione cruciale della fiducia in sistemi che dimostrano una capacità di auto-evoluzione, un circolo che, seppur virtuoso in termini di innovazione tecnologica, presenta dilemmi etici profondi.
In questo scenario, l’elaborazione di norme assume una rilevanza fondamentale, con alcune regioni che prendono la guida nella stesura di regolamenti destinati a orientare l’evoluzione dell’IA.
Persiste ancora ambiguità riguardo all’interpretazione e all’applicazione di tali direttive da parte dell’IA, che sta diventando sempre più indipendente e potrebbe non aderire ai dettami umani.
Questa prospettiva solleva interrogativi sulla reale attuazione di certe norme, che pongono al centro la sicurezza umana e la sottomissione dei sistemi robotici alla volontà umana, evidenziando le sfide nell’implementarle in contesti di AI avanzata e sempre più autonoma.
L’evoluzione dell’IA è un tema complesso e articolato che richiede una riflessione attenta sui potenziali benefici e rischi associati al suo sviluppo. Se da un lato l’aumento dell’autonomia dell’IA ha il potenziale per rivoluzionare i settori e migliorare l’efficienza, dall’altro solleva questioni etiche sul ruolo umano nello sviluppo e nella regolamentazione dell’IA.
Come società, dobbiamo lavorare insieme per garantire che l’evoluzione dell’IA sia guidata da principi di sicurezza, etica e trasparenza, e che i suoi benefici siano accessibili a tutti.

Mentre l’intelligenza artificiale è una parola abusata in molte industrie, molti potrebbero essere sorpresi che il suo utilizzo stia crescendo nei dispositivi medici, nella diagnostica e persino nello sviluppo di farmaci.
Infatti, nel 2023 ottobre, la FDA degli Stati Uniti ha approvato 171 dispositivi abilitati all’IA o all’apprendimento automatico nella sua lista di tali dispositivi approvati.
Di quelli appena aggiunti all’elenco, 155 sono dispositivi con date di decisione finale comprese tra il 1 agosto 2022 e il 30 luglio 2023, e 16 sono dispositivi di periodi precedenti identificati attraverso un perfezionamento dei metodi utilizzati per generare questo elenco.
Tre quarti dei dispositivi approvati sono per la radiologia. In altre aree, l’11% (57 dispositivi) è in cardiologia, mentre ci sono 15 e 14 dispositivi, rispettivamente, per ematologia e neurologia. Una manciata di dispositivi ciascuno sono per oftalmologia, gastroenterologia/urologia, e chirurgia generale e plastica.
La società con il maggior numero di dispositivi IA approvati è GE Healthcare Al secondo posto c’è Siemens Healthineers ha completato la top .
Tra le piccole aziende nello spazio dei dispositivi medici IA c’è iRhythm Technologies . L’azienda ha ottenuto l’approvazione nel luglio 2022 del suo sistema ZEUS e del relativo Zio Watch. Secondo iRhythm, l’orologio “utilizza un algoritmo basato sull’IA di fotopletismografia continua per rilevare [fibrillazione atriale] e calcolare una stima del carico di AFib”. Viene quindi inviato un rapporto al medico del paziente.
ZEUS e Zio sono stati sviluppati in collaborazione con Verily Life Sciences, la venture di ricerca sulle scienze della vita di Alphabet (GOOG).
Tra le grandi aziende di dispositivi medici, Medtronic ha diverse cose nella lista dei prodotti approvati. Questi includono dispositivi per il monitoraggio continuo della glicemia (Guardian Connect), un monitor elettrocardiogramma (TruRhythm Detection), e supporto alla rilevazione del cancro colorettale (GI Genius).
Grandi partnership farmaceutiche IA È importante notare che molte aziende con prodotti IA approvati sono piccole imprese private. Queste aziende hanno tendenzialmente lavorato con grandi aziende farmaceutiche. Due degne di nota sono Paige AI e PathAI.
Nel giugno 2022, Paige AI ha annunciato una collaborazione con l’unità Janssen di Johnson & Johnson per un test di biomarcatori basato sull’IA per lo screening del cancro alla vescica. I risultati saranno disponibili in meno di un’ora.
PathAI ha relazioni con Bristol-Myers Squibb , GlaxoSmithKline , e Roche . Nel agosto 2022, la FDA ha approvato la piattaforma di patologia digitale dell’azienda, AISight DX, per la diagnosi primaria in ambienti clinici. PathAI ha anche il prodotto AISight per la ricerca esplorativa e lo sviluppo di farmaci clinici.
Bristol sta utilizzando AISight per utilizzare la patologia potenziata dall’IA per la ricerca traslazionale in oncologia, fibrosi, e immunologia. Roche sta utilizzando un nuovo algoritmo sviluppato da PathAI nel suo software di flusso di lavoro di patologia digitale. E GSK ha iniziato una partnership nel 2022 per utilizzare lo strumento AIM-NASH di PathAI per potenziare i programmi di sviluppo di farmaci in oncologia e steatoepatite non alcolica.
La maggior parte dei dispositivi AI/ML in uso di fatto non fornisce una diagnosi, ma offre invece suggerimenti o consigli a medici o pazienti: ciò che è importante sottolineare è il ruolo prettamente analitico che svolgono questi strumenti, specializzati nella raccolta di dati e informazioni (come ad esempio il rilevamento della fibrillazione atriale dai dati ECG), mentre la diagnosi puntuale spetta interamente al medico.
L’IA per guidare l’innovazione dei dispositivi medici.
Un recente rapporto della società di analisi GlobalData sostiene che l’IA diventerà un motore significativo dell’innovazione dei dispositivi medici nel 2023, man mano che l’uso dell’IA tra i medici aumenta. La società ha notato che il mercato dei prodotti basati sull’IA cresce di 93 miliardi di dollari nel 2023, in aumento del 12% rispetto al 2022.
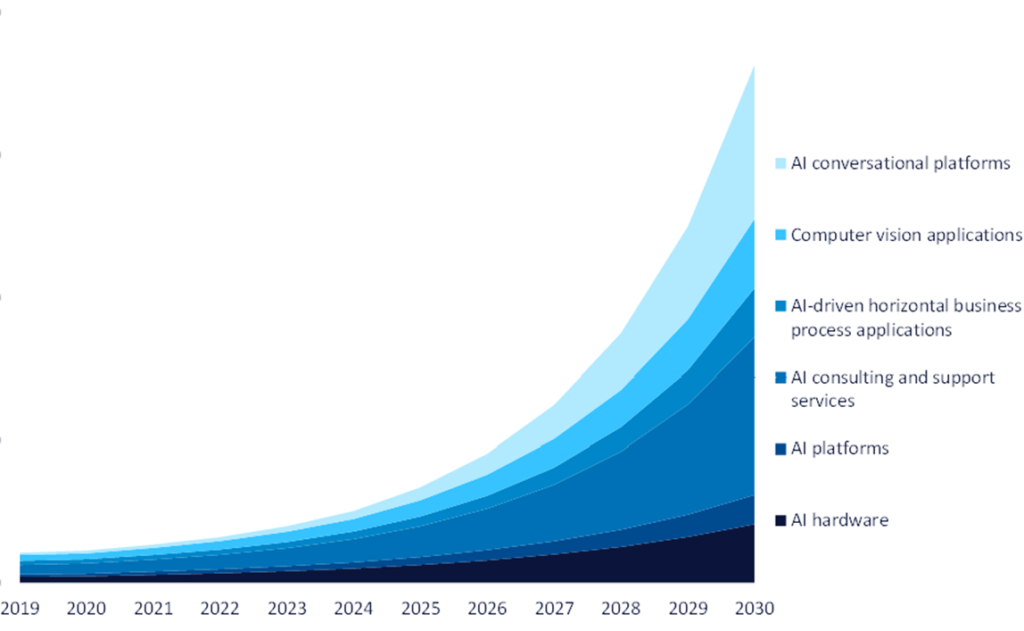
“Sappiamo che [l’IA] può essere utilizzata per scopi di gestione dei dati, chirurgia remota, assistenza diagnostica e procedurale, studi clinici, e altro ancora”, ha detto Alexandra Murdoch, analista di dispositivi medici presso GlobalData.
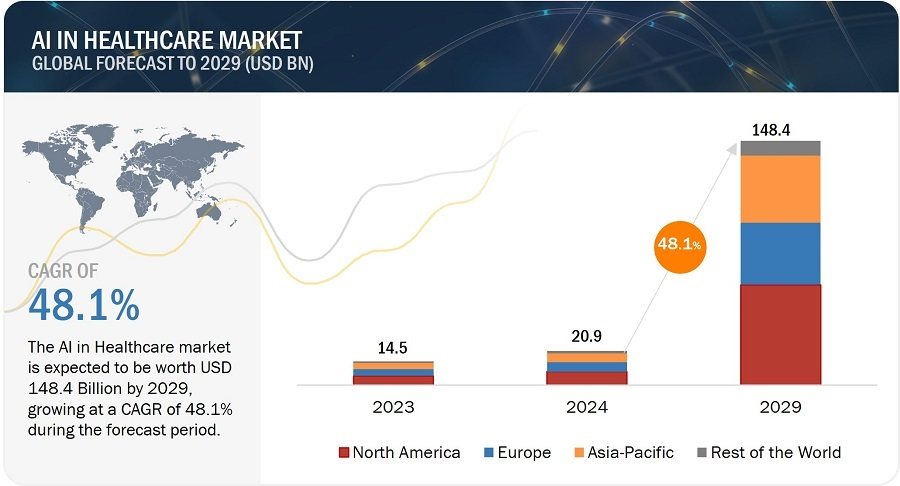
Il rapporto di GlobalData spiega che l’IA può migliorare l’efficienza della produzione di dispositivi medici e ridurre il rischio attraverso l’apprendimento automatico. Analizzando una vasta quantità di dati, i computer possono imparare dagli errori e fare miglioramenti.
Inoltre, l’IA influenzerà probabilmente ancora di più la salute digitale, a beneficio dei pazienti. Ad esempio, le applicazioni di telemedicina stanno utilizzando chatbot IA che prendono e analizzano i sintomi di un paziente, e poi forniscono orientamenti sulla salute.
In Italia con un occhio anche alla strategia nazionale per l’intelligenza artificiale (2022-2024), si e’ ragionato con l’Istituto Superiore di Sanità per comprendere: gli scenari generali per lo sviluppo delle applicazioni di IA sui dispositivi medici; le azioni che il soggetto pubblico può porre in essere, quale driver per l’adozione dell’IA in sanità e come rendere più sinergici i diversi ambiti in cui è applicata l’IA.

I modelli AI, o modelli di intelligenza artificiale, sono sistemi che utilizzano algoritmi per imitare le capacità dell’intelligenza umana. Questi modelli possono risolvere problemi o svolgere compiti e attività tipici della mente e dell’abilità umane.
Un modello di base è una particolare tipologia di modello di machine learning (ML) che viene addestrato per eseguire una specifica gamma di attività. Questi modelli di base sono stati programmati per avere una comprensione contestuale generica di andamenti, strutture e rappresentazioni. Questa conoscenza di base può essere ulteriormente affinata per eseguire attività specifiche per un dominio in qualsiasi settore.
Per esempio, ChatGPT è un’applicazione chatbot costruita sul modello base GPT-4 di OpenAI.
Le caratteristiche che definiscono i modelli di base e che ne consentono il funzionamento sono due: la capacità di trasferire le informazioni apprese e la scalabilità. La capacità di trasferire le informazioni apprese indica l’abilità di un modello di applicare le conoscenze in una situazione a un’altra. La scalabilità invece si riferisce a dei componenti hardware, le unità di elaborazione grafica (GPU), che consentono al modello di eseguire più operazioni allo stesso tempo.
Molti modelli di base, specialmente quelli impiegati nell’elaborazione del linguaggio naturale (NLP), nella visione artificiale e nell’elaborazione audio, vengono addestrati utilizzando il deep learning. Il deep learning è anche noto come apprendimento neurale profondo o reti neurali profonde e insegna ai computer a imparare tramite l’osservazione, simulando le modalità di acquisizione delle conoscenze tipiche degli esseri umani.
Per quanto non tutti i modelli di base utilizzino trasformatori, queste architetture sono state adottate in maniera diffusa per realizzare modelli di base che prevedevano la presenza di testo.
API OpenAI: L’API di OpenAI offre accesso ai modelli GPT-3 e GPT-4, che possono eseguire una vasta gamma di attività di linguaggio naturale. Inoltre, fornisce accesso a Codex, che è in grado di tradurre il linguaggio naturale in codice.
Gopher: Gopher di DeepMind è un modello linguistico con 280 miliardi di parametri. Ha dimostrato di superare i modelli di linguaggio esistenti per una serie di compiti chiave.
OPT: Open Pretrained Transformers (OPT) di Facebook è una suite di trasformatori preaddestrati solo per decoder. OPT è stato introdotto per la prima volta nei modelli di linguaggio preaddestrati aperti e rilasciato per la prima volta nel repository di metaseq il 3 maggio 2022 da Meta AI.
LLaMA: LLaMA è un modello linguistico fondamentale da 65 miliardi di parametri sviluppato da Meta.
Claude 2: Claude 2 è un assistente AI sviluppato da Anthropic. Ha ricevuto recensioni positive per la sua capacità di ragionamento e inferenza.
Beluga stabile: Beluga stabile è un modello LLamma 65B perfezionato.
Stabile Beluga 2: Stabile Beluga 2 è un modello LLamma2 70B perfezionato.
Il Center for Research on Foundation Models (CRFM) di Stanford ha confrontato la bozza dell’AI Act, con i modelli base delle IA più noti come , GPT-4 di OpenAI o Stable Diffusion v2 di Stability AI per verificare quanto l fossero già rispettossi della futura legge.

Non rispettano i requisiti della bozza per descrivere l’uso di dati di addestramento protetti da copyright, l’hardware utilizzato e le emissioni prodotte nel processo di addestramento, e come valutano e testano i modelli.
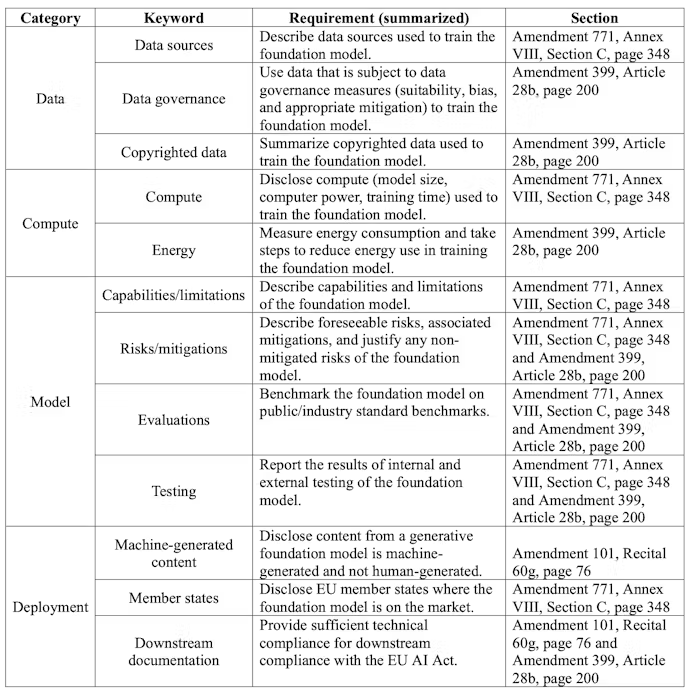
Perche‘ : La velocità di sviluppo che ha colto tutti impreparati.
Ricorda, queste informazioni sono in giornaliera evulzione Ti consiglio di verificare le informazioni più recenti online o direttamente dalle fonti ufficiali.


Agenti
- AutoCodeRover: AutoCodeRover è un ingegnere software autonomo che risolve problemi su GitHub in meno di dieci minuti ciascuno, superando gli sviluppatori che impiegano in media 2,77 giorni. Utilizza LLM e strumenti di debug per identificare in modo efficiente le posizioni delle patch, risolvendo circa il 22% dei 300 problemi reali testati con un costo minimo di LLM (~$0,5). Lo strumento impiega una ricerca del codice consapevole della struttura del programma e migliora i tassi di riparazione con suite di test tramite localizzazione di errori statistici, avanzando significativamente le pratiche di ingegneria del software AI.
Modelli di linguaggio
- Anthropic Cookbook: Anthropic Cookbook ti aiuta a integrare Claude nei tuoi progetti con frammenti di Python, richiedendo una chiave API Anthropic. Guida a migliorare Claude con strumenti esterni, recupero di dati per l’accuratezza, citazione di fonti, impiego di Haiku come sub-agente, gestione di embedding con Voyage AI, elaborazione di immagini, Diffusione Stabile per la generazione di immagini, analisi di PDF, automazione di valutazioni, abilitazione della modalità JSON e creazione di filtri di moderazione dei contenuti.
Visione
- Open-Sora-Plan: Questo progetto mira a riprodurre Sora (modello T2V di Open AI), permettendoti di generare contenuti video di alta qualità controllati dal testo, in particolare paesaggi. Puoi addestrare modelli per migliorare risoluzione e durata, impegnarti in esperimenti di text2video e affinare le condizioni del modello. Supporta l’addestramento su chip AI, incluso Huawei Ascend 910, con piani per una futura espansione a hardware domestico.
GPU/CPU
- ipex-llm: ipex-llm è una libreria PyTorch per l’esecuzione di LLM su CPU e GPU Intel (ad es. PC locale con iGPU, GPU discreta come Arc, Flex e Max) con latenza molto bassa. L’implementazione supporta attualmente più di 50 modelli ed è basata su lavori precedenti come vLLM, llama.cpp, qlora, ecc. Può essere utilizzata per inferenza a basso bit o per il fine-tuning, e offre un’integrazione senza soluzione di continuità con altri framework come LangChain, Llama-Index o Hugging Face transformers.

Speechmatics è considerato il più accurato e inclusivo API di trascrizione da voce a testo mai rilasciato.
È in grado di comprendere e trascrivere il linguaggio umano in testo con precisione, indipendentemente da demografia, età, genere, accento, dialetto o posizione.
Offre la trascrizione in tempo reale con bassa latenza e alta precisione.
Supporta 48 lingue con una vasta copertura di accenti e dialetti.
Offre opzioni di distribuzione sia basate su cloud che on-premises per la sicurezza dei dati :
Arabic, Bulgarian, Cantonese, Catalan, Croatian, Czech, Danish, Dutch, English, Finnish, French, German, Greek, Hindi, Hungarian, Indonesian, Italian, Japanese, Korean, Latvian, Lithuanian, Malay, Mandarin (Traditional and Simplified), Norwegian, Polish, Portuguese, Romanian, Russian, Slovak, Slovenian, Spanish, Swedish and Turkish.
Ha una potente motore di trascrizione e un’impressionante integrazione API.
Non offre soluzioni pronte all’uso. Il processo di configurazione fa parte del modello di apprendimento e quanto complicato possa essere dipende fortemente da come il cliente intende utilizzare Speechmatics.
Per la maggior parte dei clienti, ciò comporterà la creazione di un’interfaccia unica che si colleghi a Speechmatics tramite la sua API e quindi la gestione dell’elaborazione e della consegna dell’audio trascritto all’utente
Nonostante Speechmatics sia considerato da molti come il miglior algoritmo di Speech-to-Text, anche migliore di Watson di IBM, non sarà mai al 100% accurato. Considerando la portata più ampia degli strumenti di trascrizione AI, gli unici comparabili sono Otter e Brainia Pro. I rumori di fondo o gli oratori che mormorano possono ancora far fallire lo strumento e l’intervento umano è necessario.
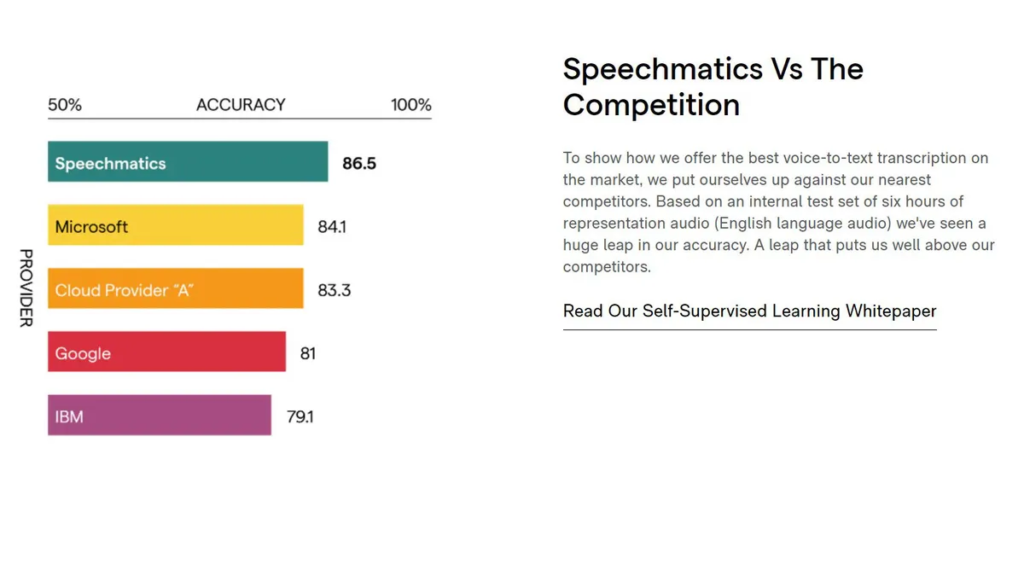
In sintesi, Speechmatics è un potente strumento di trascrizione che può essere molto utile per le aziende che necessitano di trascrizioni accurate. Tuttavia, come con qualsiasi tecnologia di riconoscimento vocale, ci sono limitazioni e potrebbe essere necessario un intervento umano per garantire l’accuratezza.

Sam Altman, il leader di OpenAI, ha presentato servizi di intelligenza artificiale per l’uso aziendale a numerosi dirigenti delle aziende Fortune 500, mettendosi in competizione diretta con Microsoft, uno dei suoi finanziatori, secondo quanto riportato da Reuters venerdì.
OpenAI ha recentemente organizzato eventi simili a roadshow a San Francisco, New York e Londra, con Altman che si è rivolto personalmente a oltre 100 dirigenti in ogni città.
L’anno scorso (Agosto 2023), OpenAI ha lanciato una versione di ChatGPT specificamente progettata per le grandi imprese, con l’intento di sfruttare le aziende che cercano di implementare strumenti di intelligenza artificiale generativa nei loro ambienti di lavoro.
In un post sul blog, OpenAI guidato da Sam Altman ha affermato che ChatGPT Enterprise fornisce “sicurezza e privacy di livello aziendale ” e accesso illimitato alla versione più potente del chatbot AI fino ad oggi, GPT-4. A marzo, OpenAI ha affermato che GPT-4 è stato in grado di ottenere un punteggio migliore nell’esame SAT rispetto al 90% dei partecipanti al test.
I primi utenti di ChatGPT Enterprise includono aziende come Block, Carlyle, The Estée Lauder Companies e alcune altre.
In un’intervista rilasciata a Bloomberg la settimana scorsa, Brad Lightcap, Chief Operating Officer di OpenAI, ha dichiarato che ChatGPT Enterprise ha raggiunto più di 600.000 utenti, un notevole aumento rispetto ai circa 150.000 di gennaio.
Microsoft fornisce alle aziende l’accesso a ChatGPT attraverso Azure OpenAI e Microsoft 365 Copilot. Inoltre, la società con sede a Redmond ha integrato questa tecnologia in molti dei suoi prodotti, tra cui la ricerca, il browser web e vari altri software e servizi.
Durante le discussioni con clienti provenienti da settori come la finanza, la sanità e l’energia, i dirigenti di OpenAI hanno sottolineato una serie di applicazioni, tra cui la gestione e la traduzione dei call center. OpenAI ha assicurato che non utilizzerà i dati dei clienti di ChatGPT Enterprise per addestrare i suoi modelli.
Alcuni dirigenti contattati hanno chiesto perché dovrebbero pagare per ChatGPT Enterprise se sono già clienti Microsoft.
In risposta, Altman e Lightcap hanno spiegato che il pagamento del servizio aziendale permetterebbe alle aziende di collaborare direttamente con il team di OpenAI e offrirebbe maggiori opportunità per ottenere prodotti IA personalizzati.

Google Foto sta rivoluzionando il fotoritocco introducendo una nuova funzionalità chiamata Magic Editor, che sfrutta l’intelligenza artificiale per semplificare il processo di modifica delle foto. Grazie a Magic Editor, gli utenti possono regolare facilmente aree specifiche delle loro immagini, modificare il layout e aggiungere nuovi elementi, anche senza essere esperti di fotoritocco.
Questa innovativa funzione sarà disponibile per la prima volta su alcuni telefoni Pixel entro la fine dell’anno, offrendo agli utenti Pixel la possibilità di sperimentarla per primi. Inoltre, Google Foto sta introducendo altri strumenti alimentati dall’intelligenza artificiale, come la Gomma magica per rimuovere oggetti indesiderati dalle foto e Photo Unblur per correggere immagini sfocate, migliorando complessivamente l’esperienza di modifica delle foto.
Questi nuovi strumenti rappresentano un notevole avanzamento nel rendere più accessibile il fotoritocco avanzato, consentendo agli utenti di preservare e migliorare i loro ricordi in modo creativo, anche senza competenze professionali. Con Google Foto, la modifica delle foto diventa più semplice e divertente che mai, aprendo nuove possibilità creative per gli utenti di tutti i livelli di esperienza.
L’azienda, infatti, avrebbe deciso di diffondere il suo strumento di editing delle immagini, eliminando la necessità di un abbonamento a Google One

Apple concentrerà la prossima versione della sua famiglia di chip M sull’Intelligenza Artificiale nel tentativo di aumentare le vendite di Mac, ha riferito Bloomberg.
I chip M4 saranno costruiti sullo stesso processo a 3 nanometri dei chip M3, ma il fornitore TSMC utilizzerà probabilmente una versione migliorata del processo a 3 nm per aumentare le prestazioni e l’efficienza energetica. Apple prevede inoltre di aggiungere un neural engine molto migliorato con un numero maggiore di core per le attività di Intelligenza Artificiale.
La prossima versione dei chip della serie M, conosciuta come M4, sarà disponibile in tre varietà, ha riferito il Bloomberg. L’M4 è già in fase di produzione e verrà eventualmente installato su ogni Mac, con annunci che arriveranno già quest’anno.
Il chip M1 è il primo processore per personal computer realizzato utilizzando la rivoluzionaria tecnologia di elaborazione a 5 nanometri e integra ben 16 miliardi di transistor, il numero più elevato mai racchiuso da Apple in un chip
Nell’ambito del rinnovamento, Apple fornirà ai nuovi iMac, al MacBook Pro da 14 pollici di fascia bassa, al MacBook Pro di fascia alta e ai Mac Mini i nuovi chip M4. Altri Mac M4 potrebbero arrivare nel 2025, inclusi i nuovi MacBook Air, Mac Studio e Mac Pro.
Apple, con sede a Cupertino, in California, ha presentato la versione precedente della serie M, la M3, in ottobre, insieme a nuove versioni di MacBook Pro e una versione aggiornata di iMac.
Apple ha aggiornato il MacBook Air con i chip M3 il mese scorso e ha evidenziato le capacità AI del nuovo notebook.
“E con un Neural Engine più veloce ed efficiente in M3, MacBook Air continua a essere il miglior laptop consumer al mondo per l’intelligenza artificiale“, ha affermato Apple nel comunicato.
La maggior parte dei nuovi iPhone e iPad hanno un Neural Engine , un processore speciale che rende i modelli di machine learning davvero veloci, ma non si sa pubblicamente come funzioni effettivamente questo processore.
L’Apple Neural Engine (o ANE) è un tipo di NPU , che sta per Neural Processing Unit. È come una GPU, ma invece di accelerare la grafica, una NPU accelera le operazioni della rete neurale come convoluzioni e moltiplicazioni di matrici.
L’ANE non è l’unica NPU disponibile: molte aziende oltre ad Apple stanno sviluppando i propri chip acceleratori AI. Oltre al Neural Engine, la NPU più famosa è la TPU (o Tensor Processing Unit) di Google.
È molto più veloce della CPU o della GPU! Ed è più efficiente dal punto di vista energetico .
Ad esempio, quando si esegue un modello su video in tempo reale, l’ANE non surriscalda il telefono e scarica la batteria molto meno rapidamente. Gli utenti lo apprezzeranno.
L’esecuzione dei tuoi modelli su ANE lascerà la GPU libera per eseguire attività grafiche e lascerà la CPU libera per eseguire il resto della tua app.
Considera questo: molte moderne architetture di rete neurale funzionano effettivamente più velocemente sulla CPU che sulla GPU (quando si utilizza Core ML). Questo perché gli iPhone hanno CPU davvero veloci! Inoltre, c’è sempre un certo sovraccarico nella pianificazione delle attività da eseguire sulla GPU, che potrebbe annullare qualsiasi aumento di velocità.
L’atteso aggiornamento arriva in un momento in cui le vendite dei Mac hanno avuto difficoltà. I ricavi dei Mac per il trimestre conclusosi a dicembre sono cresciuti solo dello 0,6% su base annua arrivando a 7,78 miliardi di dollari.
Tuttavia, le vendite potrebbero aver subito una svolta nel periodo più recente, poiché la società di ricerca IDC ha dichiarato che Apple ha spedito 4,8 milioni di unità durante il primo trimestre, in crescita del 14,6% su base annua. Alla fine del periodo deteneva l’8,1% del mercato globale dei PC, in aumento rispetto al 7,1% dello stesso periodo di un anno fa, ha aggiunto IDC.
Apple dovrebbe tenere la sua conferenza annuale degli sviluppatori a giugno, dove si prevede che il colosso della tecnologia si concentrerà su una serie di iniziative legate all’intelligenza artificiale.

Andrej Karpathy, precedentemente nel team fondatore di OpenAI e Direttore di AI presso Tesla, ha rilasciato il suo secondo progetto educativo sui Modelli di Linguaggio (LLM).
Questo progetto si concentra sull’addestramento di un modello GPT-2 con 124 milioni di parametri su una CPU utilizzando solo C/CUDA, evitando PyTorch.
Il codice contiene circa 1.000 righe di codice in un unico file, permettendo l’addestramento di GPT-2 su una CPU con precisione a 32 bit.
Questa è una risorsa fenomenale per capire come vengono addestrati i modelli di linguaggio.
Karpathy ha scelto GPT-2 perché i pesi del suo modello sono pubblicamente disponibili. Il progetto utilizza C per la sua semplicità e interazione diretta con l’hardware.
Inizialmente, il repository permette di scaricare e tokenizzare un piccolo dataset su cui il modello viene addestrato. In teoria, il modello potrebbe essere addestrato direttamente su questo dataset.
Tuttavia, l’attuale implementazione CPU/fp32 è ancora inefficiente, il che rende non pratico addestrare questi modelli da zero. Invece, i pesi di GPT-2 rilasciati da OpenAI vengono inizializzati e perfezionati sul dataset tokenizzato.
Karapthy sta attualmente lavorando su:
implementazione diretta di CUDA, che sarà significativamente più veloce e probabilmente si avvicinerà a PyTorch. accelerare la versione CPU con istruzioni SIMD, AVX2 su x86 / NEON su ARM (ad esempio, Apple Silicon) ,architetture più moderne, ad esempio Llama2, Gemma, ecc.
Il lavoro di Karpathy contribuisce significativamente alla comunità open-source e al campo dell’IA. Questo secondo progetto educativo va un passo avanti nella democratizzazione dell’IA mostrando come un modello può essere addestrato e ottimizzato utilizzando un singolo file di codice.
Andrey Karpathy: “Scrivere il codice di addestramento llm.c sarebbe a mio parere una sfida molto interessante, impressionante, autonoma e molto meta per gli agenti LLM.”
Dave Deriso: “Spero che più sviluppatori riscoprano l’efficienza elegante del C, soprattutto ora che i copiloti llm aiutano a ridurre le barriere intensive di memoria nel richiamare la sintassi e le molte funzioni integrate.”
Nella battaglia epocale per il dominio dell’Intelligenza Artificiale si intravede un conflitto globale di proporzioni monumentali.
Ebbene si, nel cuore del XXI secolo, il mondo assiste a una competizione titanica tra le principali potenze mondiali per conquistare il primato nell’ambito dell’Intelligenza Artificiale. E non si tratta semplicemente di un’altra gara tecnologica, ma di un confronto epocale che potrebbe plasmare il corso della storia per le generazioni a venire.
Già nel 2019, il segretario alla Difesa statunitense Mark Esper sollevò il velo su una realtà imminente. “Persone diverse mettono cose diverse al primo posto; per me è l’intelligenza artificiale”, ha detto durante l’udienza sulle sue principali priorità tecnologiche in risposta a una domanda da parte di Martin Heinrich, membro del SASC, il Comitato per i Servizi Armati del Senato, a cui è conferito il potere di controllo legislativo delle forze armate nazionali. L’Intelligenza Artificiale “probabilmente cambierà il carattere della guerra, e credo che chiunque la padroneggerà dominerà sul campo di battaglia per molti, molti, molti anni”, ha concluso Esper, riconoscendo l’enorme potenziale dei progressi nell’Intelligenza Artificiale e avvertendo che tali sviluppi avrebbero potuto rivoluzionare radicalmente la natura di eventuali futuri conflitti armati.
La sua visione su questo punto era molto chiara: la nazione che per prima avrebbe saputo padroneggiare questa tecnologia avrebbe goduto di un vantaggio decisivo sul campo di battaglia per molti anni a venire.
È in questo momento che la corsa all’AI ha preso forma, con gli Stati Uniti e la Cina nel ruolo di protagonisti principali di un nuovo dramma geopolitico.
Nel frattempo la Cina è riuscita a fare progressi significativi nel campo dell’Intelligenza Artificiale. Il Pentagono stima che l’AI sviluppata dalla Cina sia ormai si vicina a quella americana. In molte aree, Pechino ha eguagliato o addirittura superato gli Stati Uniti, soprattutto nell’ambito delle applicazioni militari.
Già nel 2017 Pechino aveva avviato un piano nazionale specificamente rivolto all’intelligenza artificiale, il piano “A New Generation Artificial Intelligence Development Plan”, una strategia nazionale adottata al fine di “promuovere iniziative e fissare degli obiettivi per ricerca e sviluppo, industrializzazione, sviluppo dei talenti, istruzione e acquisizione di competenze, definizione di standard e regolamenti, norme etiche e sicurezza nel settore dell’intelligenza artificiale“.
Un esempio di questo progresso è stato osservato durante la cerimonia di apertura dei Giochi Olimpici invernali di Pechino 2022 quando 520 droni hanno eseguito coreografie complesse e coordinate, sottolineando le capacità avanzate della Cina nell’Intelligenza Artificiale, nei contesti militari. Tant’è che la Cina oggi è il principale esportatore globale di droni da combattimento.
Come mostrano i dati dello Stockholm International Peace Research Institute (Sipri), Pechino ha messo a segno un’intensa attività commerciale: ha “spedito almeno 282 droni da combattimento armati in 17 Paesi negli ultimi dieci anni. Nello stesso periodo gli Stati Uniti ne hanno esportati solo 12 in Francia e Gran Bretagna”.
Prima del 24 febbraio 2022 (data dell’invasione Russa dell’Ucraina), DJI una società tecnologica cinese con sede a Shenzhen, nel Guangdong, aveva esportato sia in Russia che in Ucraina, AeroScope, una piattaforma completa di rilevamento dei droni che identifica rapidamente i collegamenti di comunicazione degli UAV, monitorandone i dati e raccogliendo informazioni come lo stato del volo, i percorsi e altre informazioni in tempo reale.
Possiamo quindi dire che la Cina ha riconosciuto da subito che uno dei campi di battaglia chiave nella competizione con gli Stati Uniti sarebbe stata proprio l’Intelligenza Artificiale, il cui controllo potrebbe determinare il destino del primato globale nel XXI secolo. In questa lotta titanica, la Cina non intende rimanere indietro, ma anzi si propone di raggiungere e superare gli Stati Uniti nella corsa all’Intelligenza Artificiale.
Tuttavia, occorre considerare che l’Intelligenza Artificiale non è un’entità monolitica, ma piuttosto una sinergia di tre tecnologie fondamentali: algoritmi, potenza di calcolo e big data. Questi pilastri sono sorretti da microchip avanzati, che agiscono come il motore pulsante dell’AI.
In risposta alla crescente minaccia cinese nel campo della tecnologia dei microprocessori, gli Stati Uniti hanno intrapreso una serie di misure restrittive, cercando di soffocare il progresso tecnologico cinese e mantenere la loro supremazia.
Gli gli Stati Uniti hanno infatti vietato a giganti tecnologici come Huawei di stringere legami con società occidentali e hanno inserito aziende come Da-Jiang Innovations (DJI) nella loro Entity List, una sorta di lista nera commerciale.
Il Dictat e’ impedire alla Cina di accedere ai microchip avanzati necessari per alimentare l’Intelligenza Artificiale.
Il mondo dei semiconduttori è suddiviso in diverse categorie di aziende, ognuna con ruoli distinti e cruciali nel processo di produzione e progettazione dei circuiti integrati.
In primo luogo, ci sono le società IDM (Integrated Device Manufacturer), le quali non solo progettano ma producono i circuiti integrati all’interno dei loro stabilimenti. Tra le principali società IDM vi sono giganti come Intel e Texas Instruments negli Stati Uniti, Micron e SK Hynix in Corea del Sud.
In secondo luogo, ci sono le società cosiddette “Fabless”, che si concentrano esclusivamente sulla progettazione dei circuiti integrati, mentre la produzione è affidata a terzi.
Questo gruppo include nomi di rilievo come Qualcomm, NVIDIA e Broadcom negli Stati Uniti e MediaTek a Taiwan. Infine, ci sono le società di fonderie, che si dedicano esclusivamente alla produzione di semiconduttori per conto terzi, fornendo servizi alle aziende Fabless e alcune IDM.
Tra queste, il colosso mondiale è TSMC a Taiwan, seguita da Samsung in Corea del Sud, che svolge anche attività IDM, specialmente nel settore dei chip di memoria.
La “guerra dei chip” ha assunto una nuova rilevanza, soprattutto alla luce delle crescenti tensioni tra Cina e Taiwan. Quest’ultima peraltro, essendo sede di TSMC, è il più grande centro di produzione di chip al mondo.
Questo sforzo mirato a contenere la tecnologia cinese ha riguardato anche l’Europa: gli Stati Uniti hanno esercitato pressione sui Paesi Bassi affinché non cedessero la società ASML a Pechino, nonostante un accordo preesistente firmato quattro anni prima.
In risposta alle minacce cinesi e per proteggere le aziende che dipendono dalla fornitura dei chip, l’Unione Europea ha introdotto il “Chips Act”, un programma di incentivi del valore di 43 miliardi di euro per incoraggiare le aziende a stabilire fabbriche sul suolo europeo o in Paesi alleati.
Gli Stati Uniti hanno seguito l’esempio con un piano simile dal valore di 53 miliardi di dollari. Inoltre, l’amministrazione Biden ha proposto un’alleanza denominata “Chip 4”, coinvolgendo Stati Uniti, Taiwan, Giappone e Corea del Sud, mirata a garantire l’autonomia e la sicurezza dell’intera catena di produzione dei semiconduttori, con un obiettivo esplicito anti-cinese.
Questo approccio mirato ha lo scopo di privare la Cina delle componenti microelettroniche essenziali necessarie per la progettazione e lo sviluppo dell’AI. Senza accesso a questi componenti critici, Pechino sarebbe costretta a rallentare o addirittura interrompere lo sviluppo di hardware e software specifici per l’Intelligenza Artificiale, indebolendo così la sua posizione nel panorama globale della tecnologia.
La crescente incorporazione di software e sensori d’Intelligenza Artificiale nei sistemi d’arma contribuisce di fatto a ridisegnare i vecchi modelli di combattimento. Agli analisti militari cinesi non sono sicuramente sfuggite le difficoltà che la Russia sta incontrando nel confronto con le armi intelligenti del proprio avversario, come gli Himars o i cosiddetti droni kamikaze figli del nuovo programma “Replicator”.
Date le opportunità, i rischi e le minacce derivanti da questa nuova tecnologia, i Paesi membri della Nato hanno riconosciuto la necessità di trovare forme di cooperazione per fronteggiare fenomeni ritenuti “troppo vasti perché un singolo attore possa gestirli da solo”.
Il segretario generale dell’Alleanza Jens Stoltenberg in un’intervista al Financial Times ha sottolineato che “per decenni gli alleati Nato hanno dominato nel segmento della tecnologia. Ma questo non è più così ovvio”. D’altra parte è stata proprio la superiorità tecnologica della Nato sul piano dell’Intelligenza Artificiale a permettere alle forze di Kiev di avere una percezione più limpida del campo di battaglia rispetto agli avversari.
Secondo un nuovo policy brief dello European Council on Foreign Relations (ECFR), gli analisti cinesi non considerano la guerra della Russia contro l’Ucraina come un grande punto di rottura con il passato, bensì come un’ulteriore manifestazione dell’annosa rivalità tra la Cina e gli Stati Uniti.
Il policy brief, intitolato “China and Ukraine: The Chinese debate about Russia’s war and its meaning for the world” presenta quattro lezioni chiave, tratte da oltre 30 interviste condotte off-the-record dagli autori con analisti ed esperti strategici cinesi provenienti dalle migliori università, da think tanks e da organi affiliati al Partito Comunista Cinese.
- Gli USA stanno usando la guerra in Ucraina per accerchiare la Cina, senza però riuscire a mobilitare il resto del mondo;
- La Cina ha più da guadagnare che da perdere stando dalla parte della Russia – e oggi è Mosca ad essere il junior partner di Pechino;
- La guerra in Ucraina non ha alterato le probabilità di un potenziale conflitto su Taiwan, ma le risposte occidentali stanno certamente influenzando il pensiero cinese;
- L’interdipendenza economica non proteggerà la Cina, che deve prepararsi alle sanzioni.
La corsa all’AI è diventata una lotta non solo per il dominio tecnologico, ma anche per il controllo delle risorse chiave che alimentano questa rivoluzione digitale. Il controllo dei microchip avanzati si è trasformato in un’arma geopolitica, utilizzata dalle potenze mondiali per influenzare il corso della competizione tecnologica e consolidare la propria supremazia nel settore dell’Intelligenza Artificiale.
Alcuni progetti nel campo dell’Intelligenza Artificiale rivestono una duplice funzione, poiché possono essere utilizzati sia per scopi civili che militari come nel caso della tecnologia AeroScope sviluppata da DJI, leader mondiale nel settore dei droni.
Ciò che emerge chiaramente è che la competizione per il dominio nell’Intelligenza Artificiale è non solo una sfida che coinvolge risorse umane, finanziarie e tecnologiche di vasta portata ma anche una competizione tra differenti sistemi sociopolitici e ideologici.
Se vogliamo, la corsa all’Intelligenza Artificiale è paragonabile alla corsa al nucleare del XX secolo e Pechino è determinata a non restare indietro rispetto agli Stati Uniti. Resta da vedere chi avrà la meglio in questa contesa.
Da questo punto di vista tuttavia, va anche considerato che la corsa all’Intelligenza Artificiale è una battaglia che va oltre i confini delle tecnologie di difesa e sicurezza. Le aziende cinesi, come Tencent, Alibaba e TikTok, dominano il mercato globale degli algoritmi e dei droni civili. Questo dominio non solo solleva interrogativi sulla sicurezza, ma suggerisce anche l’applicabilità potenziale dell’AI in una vasta gamma di settori, inclusi quelli civili.
Nonostante gli sforzi degli Stati Uniti per mantenere la loro supremazia nell’AI, la Cina sta guadagnando terreno.
La corsa all’AI tra Stati Uniti e Cina è diventata una guerra tra sistemi sociopolitici, con implicazioni che vanno ben oltre il campo tecnologico. In questo confronto titanico, solo il tempo ci dirà quali saranno le conseguenze.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]
La Corea del Sud ha annunciato un piano ambizioso per investire 9,4 trilioni di won (circa 6,94 miliardi di dollari) entro il 2027 nel settore dei semiconduttori legati all’intelligenza artificiale, un passo strategico per mantenere la sua posizione di leader globale in questo settore cruciale. L’annuncio è stato fatto dal presidente Yoon Suk Yeol, che ha anche svelato un fondo separato da 1,4 trilioni di won per sostenere le imprese attive nello sviluppo di chip AI.

Nick Clegg, presidente degli affari globali di Meta Platforms , ha confermato che l’azienda tecnologica rilascerà la prossima versione del suo modello di linguaggio di grandi dimensioni, Llama 3, nel “prossimo mese”.
“Entro il prossimo mese, anzi meno, speriamo di iniziare a distribuire la nostra nuova suite di modelli di base di prossima generazione, Llama 3”, ha detto Clegg durante un evento a Londra, secondo TechCrunch.
Meta fa un passo ulteriore verso l’accessibilità dell’IA, rendendo LLaMA 3 open source. Questa decisione mira a democratizzare l’intelligenza artificiale, permettendo a sviluppatori, ricercatori e appassionati di tutto il mondo di sfruttare questa potente tecnologia.
Gli ingegneri di Meta hanno annunciato un investimento importante sul futuro dell’intelligenza artificiale, con la presentazione di due cluster composti da 24.576 GPU NVIDIA H100.

Meta prevede di distribuire 350.000 H100 entro l’anno, creando un’infrastruttura massiccia per supportare le crescenti richieste di calcolo avanzato.
Rispetto alle versioni precedenti di Llama offrirà un’ampia gamma di dimensioni del Modello . L’intento è di rendere facile per gli sviluppatori di terze parti riqualificarsi, mettere a punto e costruire sul modello base.
Llama 3 avra’ la capacità di offrire risposte contestualizzate, evitando le rigidità e le restrizioni eccessive che hanno caratterizzato altri modelli. Meta intende infatti promuovere un approccio più equilibrato e umano, fornendo contesto piuttosto che eludere o censurare le domande degli utenti.
Tuttavia, avrà ancora dei paletti. legati alla legge sulla sicurezza dell’IA, inclusa la nuova legge sull’intelligenza artificiale dell’Unione Europea.
“Ci saranno una serie di modelli diversi con diverse capacità, diverse versatilità [rilasciate] nel corso di quest’anno, a partire davvero molto presto.”
Meta ha lanciato Llama 2 nel luglio 2023 e Code Llama, che può utilizzare prompt di testo per generare e discutere codice, il mese successivo.
L’azienda guidata da Mark Zuckerberg vuole che il nuovo modello di linguaggio di grandi dimensioni affronti domande “contenziose” dopo che le salvaguardie che ha rilasciato per Llama sono state considerate “troppo sicure” dagli esecutivi dell’azienda e da alcuni dei ricercatori del modello.

Voice Engine è un innovativo strumento di clonazione della voce umana sviluppato da OpenAI. Questa tecnologia di intelligenza artificiale (IA) è in grado di creare una sintesi vocale fedele all’originale a partire da un campione vocale di soli 15 secondi. L’innovazione di Voice Engine si estende a diversi settori, con particolare rilievo nel marketing e nell’educazione.
Non è una tecnologia nuova. Numerose startup forniscono prodotti per la clonazione vocale da anni, da ElevenLabs a Replica Studios a Papercup a Deepdub a Respeecher . Lo stesso hanno fatto gli operatori storici della Big Tech come Amazon, Google e Microsoft , l’ultimo dei quali è, per inciso, un importante investitore di OpenAI .
Harris ha affermato che l’approccio di OpenAI fornisce un parlato complessivamente di qualità superiore.
Le applicazioni di clonazione vocale, pur avendo un potenziale benefico, sono state sfruttate per scopi dannosi. Ad esempio, il forum 4chan ha usato tali tecnologie per diffondere messaggi d’odio imitando celebrità. Inoltre, ci sono stati casi di utilizzo di voci clonate per ingannare i sistemi di autenticazione bancaria e influenzare le elezioni. Di fronte a tali abusi, la FCC ha dichiarato illegali le chiamate automatizzate tramite intelligenza artificiale.
OpenAI, consapevole di questi rischi, ha adottato misure per prevenire l’uso improprio del suo Voice Engine. L’accesso è limitato a un piccolo gruppo di sviluppatori e l’attenzione è rivolta a casi d’uso a basso rischio e socialmente vantaggiosi. Ad esempio, aziende come Age of Learning e HeyGen stanno utilizzando Voice Engine per generare voci fuori campo e per la traduzione, rispettivamente. Altre società stanno utilizzando Voice Engine per creare voci per persone con disturbi del linguaggio e disabilità, o per fornire feedback agli operatori sanitari nelle loro lingue principali.
Voice Engine utilizza un input di testo e un singolo campione audio di 15 secondi per generare un discorso naturale che assomiglia strettamente al parlante originale. È notevole che un piccolo modello con un singolo campione di 15 secondi possa creare voci emotive e realistiche.
OpenAI ha iniziato a testare privatamente Voice Engine con un piccolo gruppo di partner di fiducia per capire meglio le potenziali applicazioni di questa tecnologia. Alcuni esempi di applicazioni precoci includono:
- Assistenza alla lettura: Voice Engine può fornire assistenza alla lettura a non lettori e bambini attraverso voci naturali ed emotive che rappresentano una gamma più ampia di oratori rispetto a ciò che è possibile con le voci predefinite. Ad esempio, Age of Learning, una società di tecnologia educativa dedicata al successo accademico dei bambini, ha utilizzato Voice Engine per generare contenuti di voice-over pre-sceneggiati.
- Traduzione di contenuti: Voice Engine può essere utilizzato per tradurre contenuti, come video e podcast, consentendo a creatori e aziende di raggiungere più persone in tutto il mondo, fluentemente e con le loro voci. Un adottante precoce di questa tecnologia è HeyGen, una piattaforma di storytelling visivo AI che lavora con i suoi clienti aziendali per creare avatar personalizzati, simili a umani, per una varietà di contenuti.
Voice Engine è elencato come un costo di $ 15 per un milione di caratteri, o circa 162.500 parole.
Nonostante le potenziali applicazioni benefiche, Voice Engine presenta anche delle sfide. La generazione di discorsi che assomigliano alle voci delle persone ha rischi seri, e OpenAI sta adottando un approccio cauto per un rilascio più ampio a causa del potenziale abuso di voci sintetiche. OpenAI sta avviando un dialogo sulla distribuzione responsabile delle voci sintetiche e su come la società può adattarsi a queste nuove capacità.
Sorprendentemente, Voice Engine non è addestrato o ottimizzato sui dati dell’utente. Ciò è dovuto in parte al modo effimero in cui il modello – una combinazione di processo di diffusione e trasformatore – genera il discorso.
“Prendiamo un piccolo campione audio e testo e generiamo un discorso realistico che corrisponde all’oratore originale”, ha affermato Harris. “L’audio utilizzato viene eliminato una volta completata la richiesta.”
Tra i primi utilizzatori di Voice Engine di OpenAI ci sono Age of Learning, che lo usa per generare voci fuori campo, e HeyGen, che lo sfrutta per la traduzione. Anche Livox e Lifespan lo utilizzano per creare voci per persone con disturbi del linguaggio e disabilità, mentre Dimagi lo usa per fornire feedback agli operatori sanitari.
Le voci create con Voice Engine sono contrassegnate con una filigrana resistente alle manomissioni, che incorpora identificatori non udibili nelle registrazioni. Questo permette a OpenAI di identificare facilmente le clip audio generate dal loro sistema.
OpenAI ha anche lanciato una rete di team rosso per rendere i suoi modelli più robusti e prevede di fornire ai membri di questa rete l’accesso a Voice Engine per scoprire usi dannosi.
Infine, OpenAI sta testando un meccanismo di sicurezza che richiede agli utenti di leggere un testo generato casualmente come prova della loro presenza e consapevolezza di come viene utilizzata la loro voce. Questo potrebbe permettere a OpenAI di portare Voice Engine a un pubblico più ampio in futuro.
Voice Engine di OpenAI rappresenta un passo importante nella tecnologia generativa IA, dando vita a strumenti dalla marcata consapevolezza digitale. Attraverso la sintesi del parlato avanzata, questa innovativa piattaforma permette la generazione di voci realistiche che aprono nuove frontiere nella comunicazione IA. Tuttavia, è fondamentale affrontare le sfide etiche e di sicurezza associate a questa tecnologia per garantire il suo uso responsabile e benefico.

L’intelligenza artificiale (IA) è in attesa del prossimo grande sviluppo per fare un salto in avanti.
Come ribadito in quella pubblicità degli anni ’80 non serve un pennello grande bensì un Grande Pennello.
La Circuit-Complexity-Theory è una branca della logica computazionale che studia la complessità dei problemi computazionali in termini di circuiti booleani. Recenti progressi in questo campo suggeriscono che potrebbe essere possibile ottenere miglioramenti significativi nelle prestazioni dei modelli di IA attraverso l’uso di tecniche più avanzate di ottimizzazione e approssimazione.
Il GPT-4, rilasciato a marzo possiede circa 1 trilione di parametri, quasi sei volte rispetto al suo predecessore. Secondo le stime fornite dal CEO della società, Sam Altman, il costo di sviluppo si aggira intorno ai 100 milioni di dollari.
Nel contesto di crescita dell’IA, si pone la domanda: “ci serve un Grande pennello ? Questa filosofia ha guidato l’evoluzione dell’IA, enfatizzando la creazione di modelli di machine learning sempre più grandi.
Nonostante l’impero Romano fosse uno degli imperi più grandi e potenti della storia, la sua grandezza alla fine ha contribuito alla sua caduta. La gestione di un territorio così vasto ha portato a problemi logistici, difficoltà di comunicazione, tensioni interne e vulnerabilità ai nemici esterni. Quindi, in questo caso, più grande non significava necessariamente migliore.
Nonostante i successi degli ultimi LLM, ci sono limitazioni da considerare.
L’addestramento di grandi modelli di machine learning richiede molte risorse computazionali, con implicazioni economiche ed ambientali. Inoltre, questi modelli richiedono enormi quantità di dati, sollevando questioni logistiche ed etiche.
Non sempre un modello più grande garantisce un miglioramento proporzionale delle prestazioni, soprattutto se la qualità dei dati non migliora allo stesso ritmo. Questo può portare a problemi di generalizzazione.
La complessità crescente dei modelli rende difficile la loro comprensione e l’individuazione di pregiudizi incorporati, ostacolando la responsabilità e la fiducia nell’IA.
Infine, i costi e le esigenze di risorse dei modelli più grandi possono renderli inaccessibili per entità più piccole, creando una disparità nell’accesso ai benefici dell’IA.
C’è una crescente consapevolezza che l’approccio “più grande è meglio” sta raggiungendo i suoi limiti. Per migliorare i modelli di IA, sarà necessario ottenere più performance con meno risorse.
Un esempio : LLAMA2, allenato con la metà dei Token e rilasciato nel Luglio ‘23, performa peggio di DB-RX, ma non così peggio di quanto si potrebbe pensare, lo si vede bene nelle tabelle di benchmark pubblicate da DataBricks.
DB-RX ha incluso l’addestramento su 2 trilioni di token, l’uso di 3000 GPU H100 e 3 mesi di calcolo e un investimento significativo, stimato tra i 15 e i 30 milioni di euro.
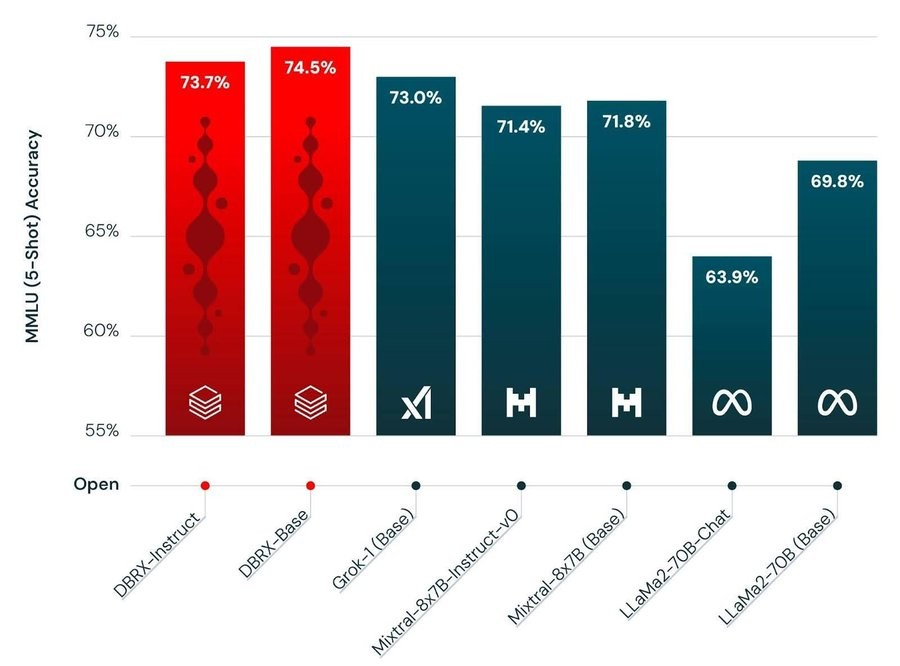
Il concetto : Più performance con meno risorse.
Alternative includono il fine-tuning per compiti specifici, l’uso di tecniche di approssimazione matematica per ridurre i requisiti hardware, e l’adattamento di modelli generalisti in modelli più piccoli e specializzati.
L’importanza del codice di programmazione e dell’hardware su cui viene eseguito è anche in discussione, evidenziando opportunità di miglioramento in questi settori.
Mentre le reti di Head-Attention e le feed-forward networks hanno avuto un ruolo fondamentale nello sviluppo dell’IA, è probabile che avremo bisogno di nuove tecniche e approcci per continuare a fare progressi in questo campo.
Le reti di Head-Attention, come quelle utilizzate nei Transformer, sono state fondamentali per il successo di molte applicazioni di apprendimento automatico. Tuttavia, queste reti possono avere dei limiti, in particolare quando si tratta di gestire sequenze molto lunghe a causa della loro complessità computazionale quadratica.
Le feed-forward networks, d’altra parte, sono state la spina dorsale dell’apprendimento profondo per molti anni. Queste reti sono in grado di apprendere rappresentazioni complesse dei dati attraverso molteplici strati di neuroni artificiali. Tuttavia, anche queste reti possono avere dei limiti, in particolare quando si tratta di modellare le dipendenze temporali nei dati.
Recenti progressi in questo campo suggeriscono che potrebbe essere possibile ottenere miglioramenti significativi nelle prestazioni dei modelli di IA attraverso l’uso di tecniche più avanzate di ottimizzazione e approssimazione.
Come l’adattamento di modelli generalisti in modelli più piccoli e specializzati, e l’esplorazione di nuovi paradigmi di apprendimento automatico.
Mentre restiamo attesa dei prossimi LLama3 e GPTNext, attesi per Luglio Agosto, Fauno (LLM) , sviluppato dal gruppo di ricerca RSTLess della Sapienza Università di Roma addestrato su ampi dataset sintetici italiani, che coprono una vasta gamma di campi come dati medici, contenuti tecnici da Stack Overflow, discussioni su Quora e dati Alpaca tradotti in italiano dovra’ confrontarsi con i numeri e i dati rilasciati da Databricks con gli investimenti di DB-REX e con un ROI che si dimezza ogni 6 mesi e senza sapere cosa uscirà da Meta o OpenAI, i quali giocano un campionato tutto loro dove le GPU si contano a centinaia di migliaia.
Il campo dell’IA è in continua evoluzione e presenta sia sfide che opportunità.
In un mondo in cui le aziende investono miliardi nello sviluppo di Large Language Models (LLM), sorgono preoccupazioni riguardo alla tecnologia della scatola nera che utilizzano. Le query di ricerca LLM richiedono una potenza di elaborazione fino a dieci volte maggiore rispetto alle ricerche standard e possono comportare spese operative milionarie su larga scala. Alcuni LLM proprietari offrono un utilizzo gratuito, ma come recita il vecchio proverbio: “Se non paghi per il prodotto, il prodotto sei tu.” Questo ha spinto alcuni a esplorare approcci alternativi
Le organizzazioni e gli individui che lavorano in questo campo devono essere pronti a navigare in questo panorama in rapida evoluzione..

Quando Alibaba Group si è quotato in borsa alla Borsa di New York il 18 settembre 2014, il CEO Jack Ma ha detto dell’IPO da 25 miliardi di dollari da record: “Quello che abbiamo raccolto oggi non è denaro, è fiducia”.
Alibaba sta tagliando i prezzi per i suoi clienti cloud a livello globale fino al 59%, in un contesto di crescente concorrenza per respingere i rivali e attirare sviluppatori di software AI, ha riferito Reuters.
Il colosso tecnologico cinese ha affermato che i prodotti relativi all’informatica, allo storage, alla rete, ai database e ai big data vedranno in media una riduzione dei prezzi del 23%, aggiunge il rapporto di Reuters .
Queste riduzioni di prezzo riguardano circa 500 specifiche di prodotti cloud e gli sconti sono ora disponibili per i clienti in 13 regioni, tra cui Giappone, Indonesia, Emirati Arabi Uniti e Germania, ha riferito Bloomberg News .
Questa è la terza volta che l’azienda riduce i prezzi nell’ultimo anno.
A febbraio, Alibaba ha dichiarato che avrebbe effettuato una forte riduzione dei prezzi per i suoi servizi cloud, con l’obiettivo di recuperare utenti da concorrenti come Tencent , che competono per fornire gli strumenti necessari per addestrare l’intelligenza artificiale .
I giganti della tecnologia cinese Alibaba Group Holding e Tencent Holdings hanno investito congiuntamente 2,5 miliardi di yuan (342 milioni di dollari) in Zhipu, una startup di intelligenza artificiale con sede a Pechino .
Alibaba e Tencent, insieme ad altre importanti aziende cinesi come Ant Group, Xiaomi e Meituan, stanno supportando Zhipu nella sua missione di sviluppare alternative nazionali al ChatGPT di OpenAI .
Zhipu è tra le numerose startup cinesi che stanno lavorando attivamente su tecnologie di intelligenza artificiale generativa, con l’obiettivo di competere con attori riconosciuti a livello globale come OpenAI e Google.
Pochi giorni dopo l’annuncio di Alibaba, anche JD.com ha dichiarato che avrebbe tagliato i prezzi del cloud computing.
JD.com ha recentemente annunciato il lancio della sua iniziativa Spring Dawn migliorata, una solida suite di soluzioni per i commercianti di terze parti per aumentare i ricavi, inclusi nuovi servizi di intelligenza artificiale progettati per ridurre i costi operativi dei commercianti fino al 50%.
Dal suo lancio iniziale nel gennaio 2023, l’ iniziativa Spring Dawn è stata un catalizzatore di crescita, aumentando di 4,3 volte il numero di commercianti terzi sulla nostra piattaforma. Mentre ci avviciniamo all’accoglienza del nostro milionesimo partner commerciale, siamo entusiasti di lanciare la fase successiva dell’iniziativa.
Le riduzioni dei prezzi segnano le mosse aggressive di Alibaba per stare al passo con i rivali, tra cui Tencent e Baidu, nel business del cloud, e rischiano di iniziare una guerra dei prezzi in un settore già fortemente competitivo.
Secondo il rapporto di Reuters, gli attuali tagli dei prezzi rappresentano l’ultimo sforzo di Alibaba per attirare gli sviluppatori a creare modelli e applicazioni di intelligenza artificiale ad alta intensità di dati utilizzando i servizi cloud dell’azienda.
Lo scorso novembre, Alibaba ha annullato il progetto di spin-off del suo Cloud Intelligence Group, noto anche come Aliyun. La società ha affermato che l’espansione delle restrizioni statunitensi sull’esportazione di chip informatici avanzati ha creato incertezze sulle prospettive del business del cloud. Successivamente, Alibaba ha avviato un rinnovamento del business del cloud computing, coinvolgendo, tra le altre cose, veterani in nuove posizioni di leadership.
L’intelligenza artificiale ha il potenziale per trasformare vari settori, dai trasporti ai media e alla finanza, e potrebbe guidare una nuova fase di crescita economica.
Tuttavia, la tecnologia ha anche applicazioni militari e governative, il che potrebbe complicare ulteriormente il già teso rapporto tra Washington e Pechino.

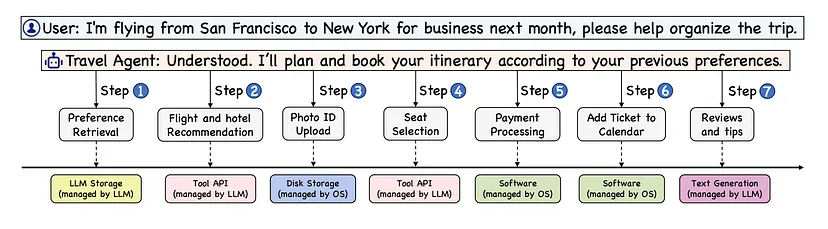
Andrey Karpathy: “Guardare i LLM come chatbot è come guardare i primi computer come calcolatrici. Stiamo assistendo all’emergere di un nuovo paradigma di calcolo, e siamo solo all’inizio.” (23/09)
Carlos E. Perez: “AIOS costituisce una piattaforma olistica per liberare veramente il potenziale degli agenti LLM nel mondo reale.”
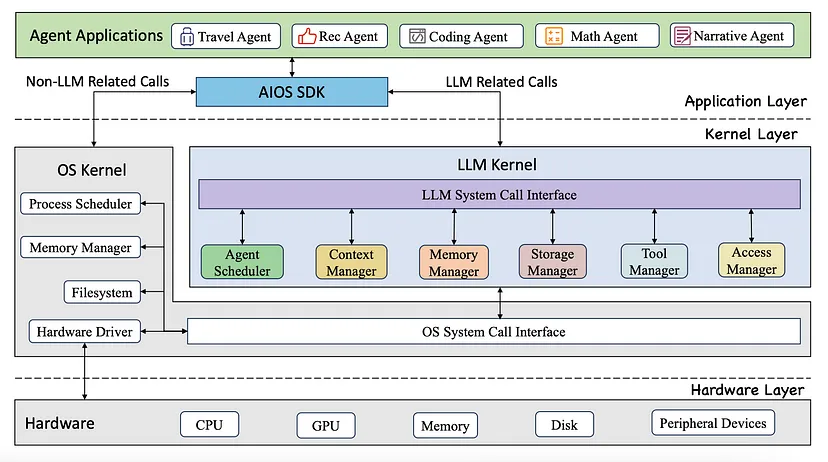
Sistema operativo dell’agente LLM. arXiv prestampa arXiv:2403.16971 .
AIOS (LLM Agent Operating System) è un nuovo framework di orchestrazione degli agenti che incorpora modelli di linguaggio di grandi dimensioni nei sistemi operativi, creando un sistema operativo con un “cervello” capace di “comprendere”.
AIOS è progettato per una distribuzione ottimale delle risorse, facilitando i cambi di contesto, l’esecuzione simultanea, i servizi di strumenti per gli agenti, il controllo degli accessi e fornendo un ricco set di strumenti per gli sviluppatori.
AIOS si basa su diversi agenti chiave che orchestrano gli altri. È composto da:
- un Gestore di Agenti per la priorizzazione delle richieste degli agenti,
- un Gestore di Contesto per la gestione del contesto di interazione,
- un Gestore di Memoria per la memoria a breve termine,
- un Gestore di Archiviazione per la conservazione dei dati a lungo termine,
- un Gestore di Strumenti per la gestione degli strumenti API esterni,
- e un Gestore di Accessi per l’applicazione delle politiche di privacy e controllo degli accessi.
Questi agenti comunicano con l’SDK di AIOS in modalità interattiva, insieme a compiti non-LLM provenienti dal Kernel del sistema operativo (con il pianificatore di processi, il gestore di memoria, ecc).
Questa architettura permette ad AIOS di integrare funzionalità AI complesse nei sistemi operativi tradizionali, consentendo lo sviluppo di applicazioni più intelligenti, reattive ed efficienti che possono sfruttare tutta la potenza dei LLM insieme alle risorse e capacità del sistema operativo convenzionale.
Perché è importante.
Questo approccio rappresenta un cambiamento nel modo in cui interagiamo con le macchine, con agenti implementati a livello di Sistema Operativo che svolgono compiti complessi.
Questa tendenza è dimostrata anche dai modelli ReALM di Apple, capaci di comprendere non solo la conversazione, ma anche le informazioni sullo schermo e sui lavori in background. Stiamo entrando in una nuova era del computing intelligente.
L’executive summary della “Strategia Italiana per l’Intelligenza Artificiale 2024-2026” è stato recentemente pubblicato, delineando una visione ambiziosa per posizionare l’Italia come leader nell’innovazione guidata dall’IA. Questa strategia è un piano dettagliato che mira a sfruttare l’IA come catalizzatore di innovazione, con importanti benefici previsti per la competitività, l’efficienza della pubblica amministrazione e la diffusione delle competenze digitali.
La strategia si sviluppa lungo quattro direttrici principali: Ricerca, Pubblica Amministrazione, Imprese e Formazione.
Ricerca: L’obiettivo è rafforzare e consolidare l’ecosistema di ricerca italiano sull’IA. Questo include il rafforzamento di iniziative esistenti come il Partenariato Esteso sull’Intelligenza Artificiale, l’attrazione e la ritenzione di talenti nel campo dell’IA, lo sviluppo di modelli di linguaggio di grandi dimensioni (LLM) italiani che rispettano i valori e le normative europee, e il finanziamento della ricerca fondamentale e interdisciplinare sull’IA.
Pubblica Amministrazione: L’IA sarà il motore della trasformazione digitale nella pubblica amministrazione. Saranno stabilite linee guida per l’adozione, l’acquisto e lo sviluppo di applicazioni IA nella pubblica amministrazione. Progetti pilota semplificheranno i servizi per cittadini e imprese, mentre iniziative nazionali mireranno a rendere più efficienti i processi interni.
Imprese: L’Italia mira a rafforzare sia il settore ICT che sviluppa soluzioni di intelligenza artificiale, sia i settori tradizionali che possono beneficiare di queste innovazioni. Sarà creato un ecosistema di facilitatori per le piccole e medie imprese (PMI), sostenendo lo sviluppo e l’adozione di soluzioni IA con fondi dedicati. Laboratori congiunti industria-ricerca e misure di supporto per le start-up completeranno il quadro.
Formazione: La formazione è cruciale per colmare il divario di competenze nell’IA. Si prevedono percorsi di avvicinamento all’IA nelle scuole, il potenziamento dell’offerta universitaria nell’IA, incluso il Dottorato Nazionale in IA, programmi di upskilling e reskilling per i lavoratori, e iniziative di alfabetizzazione digitale per i cittadini.
Infine, i fattori abilitanti saranno il potenziamento delle infrastrutture digitali, la creazione di un repository nazionale di dataset e modelli IA, e l’istituzione di una Fondazione per l’IA che coordinerà l’attuazione della strategia. Questi elementi sono fondamentali per garantire il successo della strategia e per fare dell’IA un volano di innovazione in Italia.
L’attuazione della “Strategia Italiana per l’Intelligenza Artificiale 2024-2026” prevede una serie di passaggi chiave:
Ricerca: Si prevede l’implementazione di iniziative per aumentare il numero di dottorati e attrarre in Italia i migliori ricercatori, sia in ambito di ricerca fondamentale sia applicata. Inoltre, si punta alla creazione di nuove cattedre di ricerca sull’IA, a promuovere progetti per incentivare il rientro in Italia di professionisti del settore, e a finanziare piattaforme per la condivisione di dati e software a livello nazionale.
Pubblica Amministrazione: Si prevede un aumento significativo delle procedure di acquisto di servizi legati all’IA, passando da 100 nel 2025 a 300 nel 2026. Inoltre, si prevede l’implementazione di 150 progetti di IA entro il 2025, destinati a crescere fino a 400 entro il 2026.
Imprese: Le misure a favore delle imprese hanno lo scopo di supportare la Transizione 4.0, favorire la nascita e la crescita di imprese innovative dell’IA e supportarle nella sperimentazione e certificazione dei prodotti di IA.
Formazione: Il programma include politiche per promuovere corsi e carriere nelle materie STEM e per rafforzare le competenze digitali e in Intelligenza Artificiale.
Infine, si prevede la creazione di una Fondazione per l’IA che coordinerà l’attuazione della strategia. Questi passaggi rappresentano un impegno significativo per l’Italia nel campo dell’Intelligenza Artificiale.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
[newsletter_form type=”minimal”]